【Python】超市数据处理(to_datetime(),strptime()获取特定时间数据)
任务要求
1、哪些类别的商品比较畅销?
2、哪些商品比较畅销?
3、求不同门店的销售额占比,绘制饼图
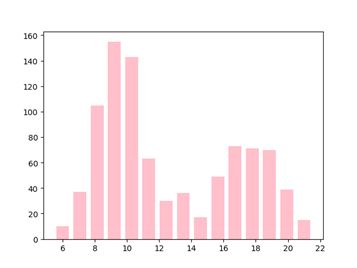
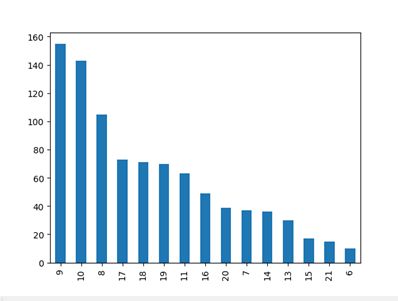
4、哪段时间段是超市的客流高峰期?
知识点杂记
1、Python time strptime()方法
struct_time = time.strptime("30 Nov 00", "%d %b %y")
print("返回的元组: " ,struct_time)

2、python统计list中个元素出现次数
pd.value_counts(data)
3、Pandas 中Dataframe数据插入: Insert函数 详解
Dataframe.insert(loc, column, value, allow_duplicates=False)
loc: 插在第几列之后
column: 列名
value:插入的内容 array,series等
allow_duplicates: 是否允许列名重复,Ture允许。
4、Pandas 中 SettingwithCopyWarning 的原理和解决方案
5、pandas.to_datetime | (官方文档)
pandas.to_datetime(arg,errors ='raise',utc = None,format = None,unit = None )
6、编码随手记录
中文编码 utf8 gbk gb8030 ansi
代码分享
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import time
#0、获取数据,查看数据
data = pd.read_csv('order.csv',encoding = 'ansi')
print(data.describe())
print(print(data.info()))
#1、哪些类别的商品比较畅销?
data = data[data['销量'] >= 0] #剔除销量小于0的数据
#print(data['销量'].describe())
data1 = data.groupby(['类别ID' ])['销量'].sum().sort_values(ascending = False)[:10]
print("最畅销的前十类商品:",data1)
#2、哪些商品比较畅销?
data2 = data.groupby(['商品ID' ])['销量'].sum().sort_values(ascending = False)[:10]
print("最畅销的前十种商品:",data2)
#3、求不同门店的销售额占比,绘制饼图
data['销售额'] = data['单价']*data['销量'] #计算销售额
data3 = data.groupby(['门店编号'])['销售额'].sum()
print('各个门店营销',data3)
#data3.plot(kind = 'pie') #绘制饼图简单实现版
plt.pie(data3,autopct='%1.2f%%', labels=['CDLG','CDNL','CDXL'])
plt.show()
#4、哪段时间段是超市的客流高峰期?
data.drop_duplicates(subset='订单ID',inplace=True) #对订单进行去重
#方法1:to_datetime转换时间,通过订单数来看客流量
data.loc[:,'成交时间'] = pd.to_datetime(data.loc[:,'成交时间'])
data.loc[:,'小时'] = [i.hour for i in data.loc[:,'成交时间']]
data4 = data.groupby(['小时'])['订单ID'].count().sort_values(ascending=False)
print('客流量降序分布情况:',data4)
'''
#方法2: time.strptime转换时间,用列表存放数据
time_tuple =[] #用列表方式存放数据
for i in range(len(data)):
time_tuple.append(time.strptime(data.iloc[i]['成交时间'],'%Y/%m/%d %H:%M')[3]) #2017/1/3 9:56
print(pd.value_counts(time_tuple))
#data['h']=pd.DataFrame(time_tuple) #列表乱内存放元素是乱序的,不能直接合并会原data
#但考虑到实际上,只需要获取小时数的具体数目就能知道客流量分布,实际上不合并回原data,任务也完成了
#方法3:time.strptime转换时间,用ndarray获取数据
#在方法2种提到:list会乱序,这里可采用ndarry类型规避这个问题
hour3 = np.zeros(data.shape[0])
for i in range(len(data)):
hour3[i] = time.strptime(data.iloc[i]['成交时间'],'%Y/%m/%d %H:%M')[3]
#print(pd.value_counts(time_tuple))
data.insert(8,'hour3', hour3) #在data的第8列后插入一列数据hour3
'''
#客流量绘图
#pd.value_counts(time_tuple).plot(kind = 'bar')
#data4.plot(kind = 'bar')
#plt.bar(np.linspace(6,21,15),data.groupby(['小时'])['订单ID'].count(),color='pink')
#plt.show()