咱们编程教室有不少同学,学完了基础课程,掌握了一定的编程能力,开始做项目了。然后很可能遇到一个问题:管理数据。课程里有讲过用文件保存数据,还有 pickle 、 csv 等模块辅助。但对于稍微复杂一点的数据,往往不够方便。成熟的解决方案就是使用 数据库 。
估计每个刚刚使用数据库的人都会被坑得遍体鳞伤。对于一个刚刚学会 Python 不久的开发新手来说,使用数据库的 SQL 语句 几乎相当于再学一种新的语言。虽然 sqlite 、 pymysql 等模块提供了与数据的连接,但仍然需要自己去拼接 SQL 语句。Python 语法和 SQL 语法、各种引号、百分号、转义字符混杂在一起的酸爽,用过的人都忘不了。
所以实际开发中,如无特殊需求,一般不会直接写 SQL,而是用更为方便的 ORM(对象关系映射,Object Relational Mapping) 。顾名思义,就是将关系型数据库与 Python 中的对象关联起来,提供了一种操作数据的简便方式,相当于对数据库加了一层更友好的接口。
目前 Python 中比较流行的 ORM 解决方案有三种:
- Django ORM 。使用方便,但很难脱离 Django 单独使用。
- SQLAlchemy 。功能强大,成熟可扩展,但学习门槛较高。
- peewee 。轻量,可扩展,易学习,但功能有限。
对于偏初级的小型项目,通常用不到很复杂的功能,这时候 peewee 或许是最好的选择。今天我们就来重点介绍下 peewee 这个 Python ORM 库。
> 安装
pip install peewee
> 连接数据库
以 SQLite 为例:
import peewee
db = peewee.SqliteDatabase('people.db')
db.connect()
people.db 是 SQLite 的数据库文件,如果不存在会自己新建。
如果是 MySQL,要稍微复杂点,需再提供地址、用户名、密码等信息,并且必须先手动建好库:
db = peewee.MySQLDatabase('people', host='127.0.0.1', user='root', passwd='', charset='utf8', port=3306)
特别要记住的一点是,代码进行完所有数据库操作后,要主动关闭数据库:
db.close()
> 创建数据类型
既然是与对象关联,自然需要以面向对象的方式定义数据结构。我们假定一个表示人的类型 Person,包含姓名 name 和生日 birthday 两个字段:
class Person(peewee.Model):
class Meta:
database = db
name = peewee.CharField()
birthday = peewee.DateField()
Person.create_table()
如果是用过 Django 的同学,对这个 Model 应该非常熟悉了。要注意的就是,需要在 Meta 里定义 database 为前面创建的数据库。然后使用相应的 Field 类型定义字段即可。
> 新增数据对象
from datetime import date
# 方法1
uncle_bob = Person(name='Bob', birthday=date(1960, 1, 15))
uncle_bob.save()
# 方法2
Person.create(name='Crossin', birthday=date(1985, 5, 5))
直接创建数据对象,需要调用 save 方法保存到数据库中。而使用 create 方法创建则不用。
> 查找数据对象
bob = Person.get(Person.name == 'Bob')
print(bob.name, bob.birthday)
# 获取所有数据
for person in Person.select():
print(person.name)
注意这里的查找条件写法,这与 Django 是不同的。查找还可以用 where 语句,这里不做演示,可以参考官方文档。
> 修改数据对象
对于上一步找到的 bob 变量:
bob.name = 'Robert'
bob.save()
直接向属性赋值,修改完记得要 save。
> 删除数据对象
bob.delete_instance()
顺便说句,一般不建议在数据库里删除数据,因为数据删了就不好找回来了,而且可能还会引发关联数据的报错。通常是增加一个 is_deleted 字段标记已删除的内容。(所以,不要以为在网上把发布过的内容删掉就真的不存在了)
> 创建关联数据
在程序中,经常会有一些具有关联关系的数据。比如我们再创建一个宠物类 Pet,每个宠物有名字 name 和主人 owner。owner 对应的就是我们前面创建的 Person 类:
class Pet(peewee.Model):
class Meta:
database = db
owner = peewee.ForeignKeyField(Person, backref='pets')
name = peewee.CharField()
这样一来,我们就可以很方便的通过宠物找到它的主人:
bob_kitty = Pet.create(owner=bob, name='Kitty')
bob_fido = Pet.create(owner=bob, name='Fido')
print(bob_kitty.owner.name)
也可以找到一个人养的所有宠物:
for pet in bob.pets:
print(pet.name)
以上就是 peewee 的基本操作,如果你了解面向对象,应该不难理解。这些例子取自其官方文档的快速上手 Quickstart。虽然没有像 Requests 那样贴心地提供中文版,但也同样足够人性化。
地址:http://docs.peewee-orm.com/en/latest/peewee/quickstart.html
> 自动生成代码
peewee 提供了一个功能,可以从已有的数据库反向生成数据模型代码。以 SQLite 为例:
python -m pwiz -e sqlite people.db > db.py
在你的数据库文件所在路径下执行这条命令,就可以在 db.py 中自动生成代码。
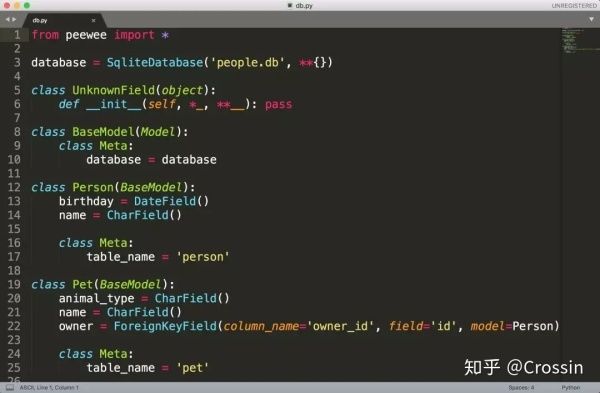 自动生成的代码
自动生成的代码
在本专栏先前的案例中,有一些就使用了 peewee。比如 Python 高频词汇表 (关键字: 单词 )和 押韵检索工具 (关键字: 押韵 )。在本公众号( Crossin的编程教室 )里回复相应关键字可查看文章及代码。
最后提一下,除了使用 ORM 外,对于数据存储还有一种解决方案,就是使用非关系型数据库,比如 mongodb 。尽管坑也不少,但对于简单的数据存储来说,它有个巨大的优势就是 同 Python 内置的 dict、list 等类型兼容良好 ,可以直接存取,让你甚至感觉不到有数据库的存在,也根本无需关心 SQL 语句。爬虫实战课程中的部分案例,就选择了 mongodb 作为数据存储方案。
════
其他文章及回答:
如何自学Python | 新手引导 | 精选Python问答 | Python单词表 | 区块链 | 人工智能 | 双11 | 嘻哈 | 爬虫 | 排序算法 | 我用Python | 高考 | 世界杯 | requests
欢迎搜索及关注: Crossin的编程教室
