普及一下行业尖端知识——腾讯自研分布式数据库TBase
我们在之前的博客中,了解过Hbase,那么你对TBase有过了解吗?
1、TBase是什么?
TBase是腾讯自研的分布式数据库,可以轻松应对亿级数据的存储、分析和查询。集高扩展性、高SQL兼容度、完整的分布式事务支持、多级容灾能力以及多维度资源隔离等能力于一身,采用无共享的集群架构,适用于PB级海量 HTAP 场景。
1.1、 TBase的总体架构

首先看下TBase的背景和架构,主要是由三个部分组成:
- Coordinator:协调节点(简称CN),对外提供接口,负责数据的分发和查询规划,多个节点位置对等,每个节点都提供相同的数据库视图;在功能上CN上只存储系统的全局元数据,并不存储实际的业务数据。
- Datanode:用于处理存储本节点相关的元数据,每个节点还存储业务数据的分片,简称DN。在功能上,DN节点负责完成执行协调节点分发的执行请求。
- GTM:全局事务管理器(Global transactionmanager.),主要是做分布式事务,负责管理集群事务信息,同时管理集群的全局对象,比如序列等,例如序列,除此之外GTM上不提供其他的功能。
1.2、TBase的特性
1.3、 TBase的产品特性:
首先是接口友好,完全兼容SQL2003,支持部分的ORACLE语法,方便了业务接入,降低了业务接入的门槛。其次是有完整的分布式事务能力,稍后会仔细介绍。再有就是在金融级数据安全保护方面的能力,以及我们在开源的基础上做的一些优化,最后就是云多租户的能力。
1.4、TBase的架构优点:
- 多活/多主:每个coordinator提供相同的集群视图,可以从任何一个CN进行写入,业务无需感知集群拓扑。
- 读/写扩展:数据被分片存储在了不同的DN,集群的读/写能力,随着集群规模的扩大做而得到提升。
- 集群写一致:业务在一个CN节点发生的写事务会一致性的呈现在其他的CN节点,就像这些事务是本CN节点发生的一样。
- 集群结构透明:数据位于不同的数据库节点中,当查询数据时,不必关心数据位于具体的节点。
2、TBase小背景
如果把每天新增亿级数据存放在普通单机数据库里,数据库的查询性能会急剧下降,甚至分析能力也会受影响。同时,急速的增长量受空间限制无法长期存储,即使通过大批量扩容满足了性能要求,随之而来的是极高的成本投入。最重要的是,普通单机数据库数亿数据的查询性能无法满足秒级返回的需求。
因此业务方迫切需要一款支持PB级,且可以应对高速联机分析和高并发的事务处理的云上可伸缩的HTAP分布式数据库系统,经过了微信支付这样严苛业务考验的腾讯自研国产分布式数据库——TBase,可以全方位满足需求。

3、TBase 分布式事务
3.1. 分布式事务一致性为什么重要?
对于分布式数据库来说,分布式事务实际上是最核心最难的部分。所有的分布式数据库都会面临一个问题,就是到底能不能给用户,提供一个数据一致性读写功能。影响事务一致性的场景很多,很多分布式场景用2PC来解决分布式事务的问题,但是2PC不能解决其全部问题。
3.2. 分布式事务的核心问题:全局时钟、事务状态同步、死锁检查
- 全局时钟
因为集群里有多个节点,每个节点有自己的时钟,我们怎么在集群范围内做到两个事件间先后关系的比较,例如,如何判断事务A在事务B开始之前提交? 这是分布式事务的一个基础,只有当事件能够比较,才可以去考虑事务的ACID特性。
- 事务状态同步
一个事务在集群里可能在很多节点参与,这个事务的状态最终一定要同步到每一个参与节点中。只要事务有不同状态,又有先后不同提交顺序,就会涉及到一个问题?从整个集群上看,这个事务到底是什么时候提交的?集群范围内看一个事务状态的翻转,必须只能有一个依据
- 死锁检测
多个事务在单个节点间看没有死锁,在多个节点之间的死锁是一个问题。跨节点死锁如何发现死锁?
3.3. Tbase怎么做到全局事务一致性?
通过两个手段:
- 第一:全局时钟。GTS从哪里来?逻辑时钟从零开始内部单向递增且唯一,由GTM维护,定时和服务器硬件计数器对齐;硬件保证时钟源稳定度。
- 第二:对MVCC做了一些分布式的改造。多个GTM节点构成集群,主节点对外提供服务;主备之间通过日志同步时间戳状态,保证GTS核心服务可靠性,提升GTM最大容量。
通过MVCC+GTS,保证事务在提交时,无论是什么状态,都能保证最后的读写是一致的。那么,GTM是否会成为整个系统的瓶颈呢?理论上是,因为每个事物都要冲GTM获取时钟。实际上我们还没有遇到过哪个生产系统达到GTM瓶颈,因为TBase GTM的最高吞吐量,我们测过,可以到1200万,也就是说每秒钟产生1200万个时间戳,对于绝大部分系统来说足够了。根据我们用TPCC测试结果来看,TBase在达到300万tpmc之前,吞吐量基本上是随着节点数增加而线性增长的。
4、实例引入
抗疫时期,云南在全省范围内的公共场所推广由腾讯云提供技术支持的“云南抗疫情”扫码系统,实现全体民众出行扫码,全面分析预测确诊者、疑似者、密切接触者等重点人群流动情况。
截至2月24日,云南省累计有1.65亿人次扫码登记“云南抗疫情”微信小程序,用户数1325.81万人。市民使用起来也极其便捷,在进入公众场所前用微信扫描“入”二维码,离开时再扫描“出”二维码,这两张二维码就是云南打赢新冠肺炎疫情防控阻击战的两杆枪。
在云南抗疫小程序中,为满足业务高并发的入库和业务分析查询,TBase使用高性能分区表功能,根据数据量的大小将人群流动数据按照天或者间隔几天进行分区存放,解决了业务分库分表的痛点,并且可以进行冷热数据分离,为海量数据的处理提供了高效的方案。同时,利用TBase智能扫描快速定位数据的位置,减少人群范围,实现快速定位。另外,TBase采用分布式架构,可根据业务压力大小灵活扩展计算和存储资源,在节省成本的同时帮助业务高效稳定运行。
在数据的读取上,TBase将查询下推,并行执行用户SQL,分布式join执行示例如下:
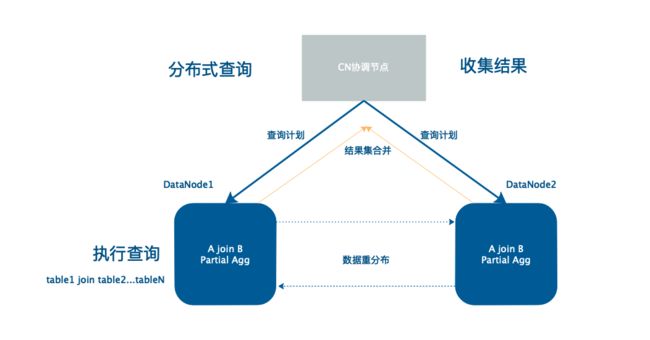
要实现亿级数据的秒级返回,最重要的是提高数据节点执行效率,这里就需要提到数据重分布技术。
大家都知道,在分布式执行中通用的技术是数据重分布,数据重分布时容易导致数据节点内部资源使用不平衡,从而影响效率。TBase的数据重分布模型进行了业界独一无二的优化,该优化利用了CPU多核并行计算能力,增强了对复杂SQL的执行优化,可以减轻生产者负担,从而大大提高数据重分布时的执行效率和分布式系统中关联和聚合的效率,轻松实现小程序查询业务中亿级数据的秒级返回。
通过TBase的shard算法可以将数据快速均匀的分布到各个数据节点中,提升检索效率的同时也解决了单库的存储压力瓶颈问题。
我们看出TBase的一大特点:高效处理急速爆发的亿级流量,第二大特点是:海量数据智能处理分析与建模
通过抗疫小程序,在疫情病患恢复期间,一旦发现确诊人员就可以快速回溯病患曾经出入过的场所,从而快速找出可能和他有过接触的人员并及时通过短信、电话等方式向可能接触者发出提醒,尽最大可能减少交叉传播的可能性。特别是复工人潮的冲击下,为确保市民安全防止病毒扩散,需要不间断的对人群进行流动和回溯分析。
在TBase的智能分析与建模能力下,仅需30秒即可实现亿级数据量去重。这样的秒级响应是怎么实现的呢?TBase利用两个计算特性对海量数据进行分析和关联:

分布列下推查询

非分布列join
在人流不断进出公共场所时,由于前端在设计表结构并未增加主键,存在业务重复扫码以及误操作等情况,这将导致一部分数据是重复,但是这些数据依然是有参考价值的,将这些数据用在后续计算模型丰富,但这无疑给模型带来了不必要的计算。因此我们需要对业务数据进行数据去重操作。利用TBase独特的node_id和ctid以及业务主键属性进行快速筛选以及去重处理之后,简化了后续数据建模中产生的不必要中间结果。
根据扫码数据以及人群的动态轨迹信息,首先根据业务数据量的一些特征分布列设计。比如一些主属性的唯一特征,利用分布列进行下推查询,提升分布式的join计算能力。一些无法下推的查询,将复杂查询的各部分数据转化成重分布查询,利用CPU内存计算优势提高计算。通过针对业务主属性快速的分析,合理进行相关表结构设计,快速的将分析结果提供给前端设备进行预警。
另外,TBase的多核计算能力也成功将CPU多核并行计算能力、执行SQL能力实现秒级返回,保障了模型的稳定分析能力。
在TBase强悍性能的支持下,“云南防抗疫”小程序从接入数据库到上线仅用了18个小时,有效运用科技化、信息化、大数据的手段,推动疫情防控工作更加高效和精准,进一步降低疫情防控风险。
参考资料:
腾讯技术工程
腾讯云