PyTorch实现SRGAN——动漫人脸超分辨率
文章目录
- 1. 数据集介绍
- 2. SRGAN模型的构建
- 3. 数据读取
- 4. 损失函数构建
- 5. 模型训练
- 6. 测试模型
全部代码: GitHub
1. 数据集介绍
使用的是一个动漫人脸数据集,完整数据集下载链接:百度云 提取码:lt05
该数据集图像大小均为96×96的像素,把原图当做HR,把原图resize为48×48作为LR,实现48到96的二倍超分辨,我仅选取了100张图像作为训练集,20张图像做测试。

![]()

![]()
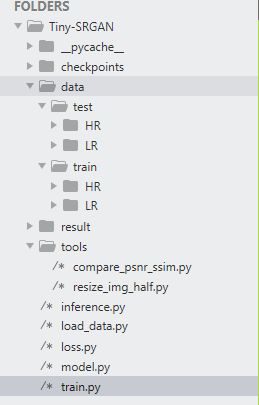
文件结构如下:
2. SRGAN模型的构建
为了节省训练时间,我将原始SRGAN生成器删了几个残差快,判别器删了几个卷积层,原始SRGAN的网络结构可以去看论文里的图。
model.py:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Resblock(nn.Module):
def __init__(self, channels):
super(Resblock, self).__init__()
self.residual = nn.Sequential(
nn.Conv2d(channels, channels, kernel_size=3, padding=1),
nn.BatchNorm2d(channels),
nn.PReLU(),
nn.Conv2d(channels, channels, kernel_size=3, padding=1),
nn.BatchNorm2d(channels)
)
def forward(self, x):
residual = self.residual(x)
return x + residual
class UpsampleBLock(nn.Module):
def __init__(self, in_channels, up_scale):
super(UpsampleBLock, self).__init__()
self.upsample = nn.Sequential(
nn.Conv2d(in_channels, 256, kernel_size=3, padding=1),
nn.PixelShuffle(up_scale),
nn.PReLU()
)
def forward(self, x):
return self.upsample(x)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=5, padding=2),
nn.PReLU()
)
self.resblocks = nn.Sequential(
Resblock(64),
Resblock(64),
Resblock(64)
)
self.conv2 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.PReLU()
)
self.upsample = UpsampleBLock(64, 2)
self.conv3 = nn.Conv2d(64, 3, kernel_size=5, padding=2)
def forward(self, x):
block1 = self.conv1(x)
block2 = self.resblocks(block1)
block3 = self.conv2(block2)
block4 = self.upsample(block1 + block3)
block5 = self.conv3(block4)
# return (torch.tanh(block5)+1) / 2
return block5
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.net = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(256, 512, kernel_size=1),
nn.LeakyReLU(0.2),
nn.Conv2d(512, 1, kernel_size=1)
)
def forward(self, x):
batch_size = x.size(0)
return torch.sigmoid(self.net(x).view(batch_size))
if __name__ == '__main__':
a = torch.randn(1, 3, 48, 48)
net = Generator()
net2 = Discriminator()
out = net(a)
print(out.shape)
3. 数据读取
数据读取,把训练数据HR图像和LR图像读进来。
load_data.py:
from torch.utils.data.dataset import Dataset
import os
from PIL import Image
from torch.utils.data import DataLoader
from torchvision import transforms
import numpy as np
class TrainDataset(Dataset):
def __init__(self, train_img_path, transform=None):
super(TrainDataset, self).__init__()
self.img_hr = os.listdir(train_img_path + '/HR')
self.img_lr = os.listdir(train_img_path + '/LR')
self.transform = transform
self.hr_and_lr = []
assert len(self.img_hr) == len(self.img_lr), 'Number does not match'
for i in range(len(self.img_hr)):
self.hr_and_lr.append(
(os.path.join(train_img_path, 'HR', self.img_hr[i]),
os.path.join(train_img_path, 'LR', self.img_lr[i]))
)
def __getitem__(self, item):
hr_path, lr_path = self.hr_and_lr[item]
hr_arr = Image.open(hr_path)
lr_arr = Image.open(lr_path)
return np.array(lr_arr).transpose(2, 0, 1).astype(np.float32), np.array(hr_arr).transpose(2, 0, 1).astype(np.float32)
def __len__(self):
return len(self.img_hr)
if __name__ == '__main__':
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
data = TrainDataset('data/train', transform)
print(len(data))
data_loader = DataLoader(data, batch_size=8, shuffle=True)
sample = next(iter(data_loader))
print(sample[0].shape)
4. 损失函数构建
SRGAN损失函数分为VGG感知损失、图像MSE损失和对抗损失。
loss.py:
import torch.nn as nn
import torch
from torchvision.models.vgg import vgg16
class ContentLoss(nn.Module):
def __init__(self):
super(ContentLoss, self).__init__()
vgg = vgg16(pretrained=True)
loss_network = nn.Sequential(*list(vgg.features)[:31]).eval()
for param in loss_network.parameters():
param.requires_grad = False
self.loss_network = loss_network
self.mse_loss = nn.MSELoss()
def forward(self, fake_img_hr, target_img_hr):
# Perception Loss
perception_loss = self.mse_loss(self.loss_network(fake_img_hr), self.loss_network(target_img_hr))
# img MSE Loss
image_mse_loss = self.mse_loss(fake_img_hr, target_img_hr)
return image_mse_loss + 0.006 * perception_loss
class AdversarialLoss(nn.Module):
def __init__(self):
super(AdversarialLoss, self).__init__()
self.bec_loss = nn.BCELoss()
def forward(self, logits_fake):
# Adversarial Loss
adversarial_loss = self.bec_loss(logits_fake, torch.ones_like(logits_fake))
return 0.001 * adversarial_loss
5. 模型训练
batsize设置为1,训练100个epoch,学习率设置为0.0001.
train.py:
import torch
import torch.nn as nn
from load_data import TrainDataset
from model import Generator, Discriminator
from loss import ContentLoss, AdversarialLoss
from torch.utils.data import DataLoader
from torchvision import transforms
import torch.optim as optim
import os
batchsize = 1
epochs = 100
learning_rate = 0.0001
train_data_path = 'data/train'
checkpoint_path = 'checkpoints'
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
traindata = TrainDataset(train_data_path, transform)
traindata_loader = DataLoader(traindata, batch_size=batchsize, shuffle=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
netG = Generator().to(device)
netD = Discriminator().to(device)
optimizerG = optim.Adam(netG.parameters(), lr=learning_rate)
optimizerD = optim.Adam(netD.parameters(), lr=learning_rate)
bce = nn.BCELoss()
contentLoss = ContentLoss().to(device)
adversarialLoss = AdversarialLoss()
# print(netG)
# print(netD)
if not os.path.exists(checkpoint_path):
os.mkdir(checkpoint_path)
torch.save(netG, checkpoint_path+'/netG-epoch_000.pth')
for epoch in range(1, epochs+1):
for idx, (lr, hr) in enumerate(traindata_loader):
lr = lr.to(device)
hr = hr.to(device)
# 更新判别器
netD.zero_grad()
logits_fake = netD(netG(lr).detach())
logits_real = netD(hr)
# Lable smoothing
real = torch.tensor(torch.rand(logits_real.size())*0.25 + 0.85).to(device)
fake = torch.tensor(torch.rand(logits_fake.size())*0.15).to(device)
d_loss = bce(logits_real, real) + bce(logits_fake, fake)
d_loss.backward(retain_graph=True)
optimizerD.step()
# 更新生成器
netG.zero_grad()
g_loss = contentLoss(netG(lr), hr) + adversarialLoss(logits_fake)
g_loss.backward()
optimizerG.step()
print('Epoch:[%d/%d]\tStep:[%d/%d]\tD_loss:%6f\tG_loss:%6f'%
(epoch, epochs, idx, len(traindata_loader), d_loss.item(), g_loss.item()))
if epoch % 10 == 0:
torch.save(netG, checkpoint_path+'/netG-epoch_%03d.pth' % epoch)
# torch.save(netD, 'netD-epoch_%03d.pth' % epoch)
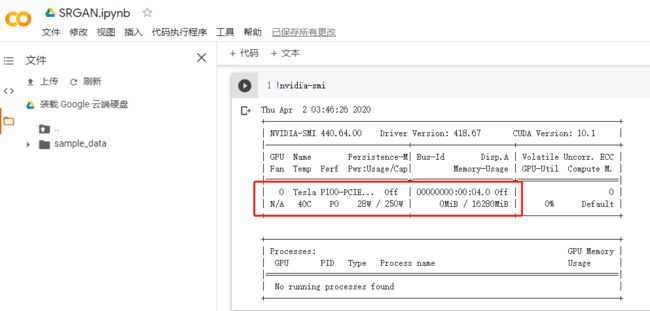
我笔记本配置太低,我是在Google Colab(需要科学上网)上训练的,他提供免费的Tesla P4、Tesla P100或者Tesla K80,这个自己没法选,看运气分配,Colab用来学习还是很不错的。
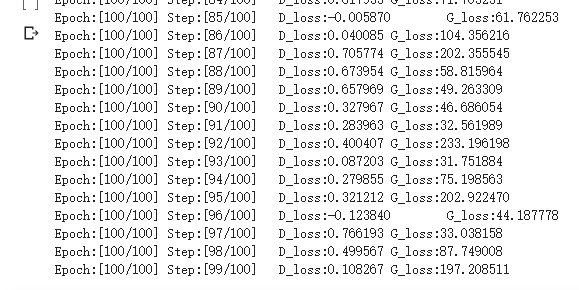
训练结果:
6. 测试模型
将测试集中的LR图像通过训练好的模型生成HR图像。
inference.py:
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import os
from load_data import TrainDataset
import torchvision.utils as vutils
test_img_path = 'data/test/'
checkpoint_path = 'checkpoints/netG-epoch_100.pth'
save_img_path = os.path.join('result', 'fake_hr_%s'%checkpoint_path.split('.')[0][-9:])
if not os.path.exists(save_img_path):
os.makedirs(save_img_path)
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
test_data = TrainDataset(test_img_path,)
testloader = DataLoader(test_data, batch_size=1, shuffle=False)
netG = torch.load(checkpoint_path, map_location=torch.device('cpu'))
for idx, (lr, hr) in enumerate(testloader):
fake_hr = netG(lr)
vutils.save_image(fake_hr.data,
'%s/%03d.png'%(save_img_path, idx),
normalize=True)
print(idx)
从左往右依次为LR,生成的HR,真实的HR。
![]()


![]()


计算20张测试图像的平均MSE和平均PSNR。
compare_psnr_mse.py:
from sewar.full_ref import mse
from sewar.full_ref import psnr
import os
import cv2
def calculate_mse_psnr(fake_path, true_path):
fake_imgs_name = os.listdir(fake_path)
fake_imgs_name.sort()
true_imgs_name = os.listdir(true_path)
true_imgs_name.sort()
assert len(fake_imgs_name) == len(true_imgs_name), '图片数量不匹配'
MSE_list = []
PSNR_list = []
for idx in range(len(fake_imgs_name)):
fake_arr = cv2.imread(os.path.join(fake_path, fake_imgs_name[idx]))
true_arr = cv2.imread(os.path.join(true_path, true_imgs_name[idx]))
MSE = mse(true_arr, fake_arr)
PSNR = psnr(true_arr, fake_arr)
MSE_list.append(MSE)
PSNR_list.append(PSNR)
print(fake_imgs_name[idx])
return sum(MSE_list)/len(fake_imgs_name), sum(PSNR_list)/len(fake_imgs_name)
def main():
fake_path = '../result/fake_hr_epoch_100'
true_path = '../data/test/HR'
avg_mse, avg_psnr = calculate_mse_psnr(fake_path, true_path)
print('平均MSE:', avg_mse)
print('平均PSNR:', avg_psnr )
if __name__ == '__main__':
main()
统计结果如下表所示:
| 指标 | epoch_000 | epoch_010 | epoch_020 | epoch_030 | epoch_040 | epoch_050 | epoch_060 | epoch_070 | epoch_080 | epoch_090 | epoch_100 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| MSE | 9832.695 | 416.394 | 379.517 | 317.068 | 289.540 | 336.753 | 281.660 | 267.475 | 273.542 | 271.774 | 280.439 |
| PSNR | 8.291 | 22.889 | 23.337 | 24.291 | 24.754 | 23.838 | 24.773 | 25.098 | 24.872 | 25.184 | 24.942 |
全部代码:GitHub