初识机器学习--MNIST 手写数字识别
参考博客:MNIST 手写数字识别(一)https://blog.csdn.net/sinat_34328764/article/details/83832487
MNIST是一个很有名的手写数字识别数据集,对于每张图片,存储的方式是一个 28 * 28 的矩阵,导入数据进行使用的时候会自动展平成 1 * 784(28 * 28)的向量,这在TensorFlow导入很方便,在使用命令下载数据之后,可以看到有四个数据集:

模型
来看一个最基础的模型建立,首先了解TensoFlow对MNIST数据集的一些操作
1.TensorFlow 对MNIST数据集的操作
下载、导入
from tensorflow.examples.tutorials.mnist import input_data
# 第一次运行会自动下载到代码所在的路径下
mnist = input_data.read_data_sets('location', one_hot=True)
# location 是保存的文件夹的名称
打印MNIST数据集的一些信息
# 打印 mnist 的一些信息
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
print("number of train data is %d" % mnist.train.num_examples)
print("number of test data is %d" % mnist.test.num_examples)
# 将所有的数据加载为这样的四个数组 方便之后的使用
trainimg = mnist.train.images
trainlabel = mnist.train.labels
testimg = mnist.test.images
testlabel = mnist.test.labels
输出结果:
number of train data is 55000 # 训练集共有55000条数据
number of test data is 10000 # 训练集有10000条数据
2.简单逻辑回归模型建立
这是一个逻辑回归(分类)的问题,首先来建立一个最简单的模型,之后会逐渐地优化。分类模型一般会采用交叉熵方式作为损失函数,所以,对于这个模型的输出,首先使用 SoftmaxSoftmaxSoftmax 回归方式处理为概率分布,然后采用交叉熵作为损失函数,使用梯度下降的方式进行优化。
Softmax 回归
这个函数的作用是将一组数据转化为概率的形式,
函数表达式:
![]()
SoftmaxSoftmaxSoftmax回归可以将一组数据整理为一个概率分布,其实计算很简单,也很好理解,这里是用来处理模型的原本输出结果: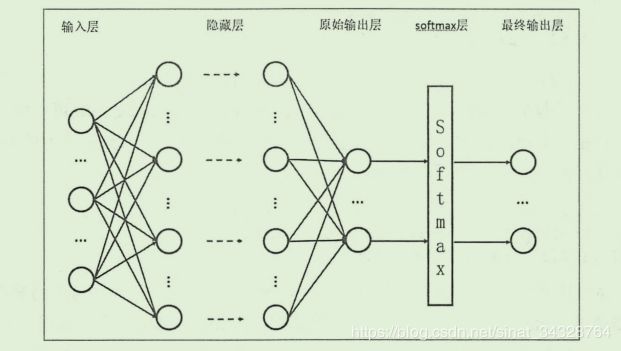
这是因为模型原本的输出可能是(1,2,3...)这样形式,无法使用交叉熵的方式进行衡量,所以先进行一次处理,举个例子就是,对于一个向量 (1,2,,3) 经过 Softmax回归之后就是 (![]() ,
,![]() ,
,![]() ),这样就成为一个概率分布,方便接下来计算交叉熵了。
),这样就成为一个概率分布,方便接下来计算交叉熵了。
交叉熵的介绍
交叉熵(cross entropy)的概念取自信息论,刻画的是两个概率分布之间的距离,一般都会用在分类问题中,对于两个给定的概率分布 p 和 q,(注意:这里指的是 概率分布,不是单个的概率值,所以才会有下面公式中的求和运算)通过 q 来表示 p 的交叉熵表达为:
![]()
这里还是要解释一下,使用交叉熵的前提:概率分布 p(X=x)必须要满足:∀xp(X=x)∈[0,1] and ∑p(X=x)=1
现在可以理解为什么要先使用softmaxsoftmaxsoftmax回归对输出地数据先进行处理了吧,本来模型对于一张图片的输出是不符合概率分布的,所以经过softmaxsoftmaxsoftmax回归转化之后,就可以使用交叉熵来衡量了。
如果通俗地理解交叉熵,可以理解为用给定的一个概率分布表达另一个概率分布的困难程度,如果两个概率分布越接近,那么显然这种困难程度就越小,那么交叉熵就会越小,回到MNIST中,我们知道对于某一张图片的label,也就是正确分类是这样的形式:(1, 0, 0, …) ,对于这张图片,我们的模型的输出可能是 (0.5, 0.3, 0.2) 这样的形式,那么计算交叉熵就是 −(1×log(0.5)+0×log(0.3)+0×log(0.2)),这样就计算出了交叉熵,在上面程序中 lost函数中就是这样计算的。这里还用到了一个函数 : tf.clip_by_value(),这个函数是将数组中的值限定在一个范围内
# 损失函数 使用交叉熵的方式 softmax()函数与交叉熵一般都会结合使用
cost = tf.reduce_mean(-tf.reduce_sum(y * tf.log(tf.clip_by_value(actv, 1e-10, 1.0)), reduction_indices=1))
虽然模型的输出一般不会出现某个元素为0这种情况,但是这样并不保险,一旦出现actv中某个元素为0,根据交叉熵的计算,就会出现 log(0) 的情况,所以最好对这个数组加以限制,对于clip_by_value()函数,定义如下:
def clip_by_value(t: Any, # 这个参数就是需要整理的数组
clip_value_min: Any, # 最小值
clip_value_max: Any, # 最大值
name: Any = None) ->
# 经过这个函数,数组中小于clip_value_min 的元素就会被替换为clip_value_min, 同样,超过的也会被替换
# 所以用在交叉熵中就保证了计算的合法
这样,很明显,交叉熵越小,也就说明模型地输出越接近正确的结果,这也是使用交叉熵描述损失函数地原因,接下来使用梯度下降(这里是)不断更新参数,找到最小地lost,就是最优的模型。
代码:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
import matplotlib.pyplot as plt
# 读入数据 ‘MNIST_data’ 是保存数据的文件夹的名称
mnist = input_data.read_data_sets('D:\深度学习\MNIST_data', one_hot=True)
# 各种图片数据以及标签 images是图像数据 labels 是预先准备好的结果
trainimg = mnist.train.images
trainlabel = mnist.train.labels
testimg = mnist.test.images
testlabel = mnist.test.labels
# 输入的数据 每张图片的大小是 28 * 28,在提供的数据集中已经被展平乘了 1 * 784(28 * 28)的向量
# 方便矩阵乘法处理
x = tf.placeholder(tf.float32,[None,784])
# 输出的结果是对于每一张图输出的是 1*10 的向量,例如 [1, 0, 0, 0...]
# 只有一个数字是1 所在的索引表示预测数据
y = tf.placeholder(tf.float32,[None,10])
# 模型参数
# 对于这样的全连接方式 某一层的参数矩阵的行数是输入数据的数量 ,列数是这一层的神经元个数
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
# 建立模型 并使用softmax()函数对输出的数据进行处理
y_ = tf.nn.softmax(tf.matmul(x,W)+b)
# 损失函数 使用交叉熵的方式 softmax()函数与交叉熵一般都会结合使用
cost = tf.reduce_mean(-tf.reduce_sum(y * tf.log(tf.clip_by_value(y_, 1e-10, 1.0)), reduction_indices=1))
# 使用梯度下降的方法进行参数优化
learning_rate = 0.01
train = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
#初始化
session = tf.InteractiveSession()
session.run(tf.global_variables_initializer())
for i in range(10000):
#进行训练
# 这里地 mnist.train.next_batch()作用是:
# 第一次取1-100数据 第二次取 101-200 ... 类似这样
batch_x,batch_y = mnist.train.next_batch(100)
session.run(train,feed_dict={x:batch_x,y:batch_y})
if i%100==0:
#测试样本 计算准确率
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
accurary = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
print(session.run(accurary,feed_dict={x:testimg,y:testlabel}))
#可视化验证
nsmaple = 10
randidx = np.random.randint(testimg.shape[0], size=nsmaple)
for i in randidx:
curr_img = np.reshape(testimg[i,:], (28, 28)) # 数据中保存的是 1*784 先reshape 成 28*28
curr_label = np.argmax(testlabel[i, :])
plt.matshow(curr_img, cmap=plt.get_cmap('gray'))
#图片可视化
plt.show()
session.run(train,feed_dict={x:[trainimg[i,:]],y:[trainlabel[i, :]]})
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
#图片的识别结果
print('test '+str(i)+':')
test = session.run(tf.matmul(np.array([testimg[i,:]]),W)+b)
print(session.run(tf.argmax(test,1)))
print('Done!')因为只有一层处理,准确率大约只有92%左右。