Keras 实现 动态调整学习率 保存最佳模型
深度学习的训练过程中,经常需要动态调整学习率同时保存最佳模型,本教程使用 Keras 框架,通过其自设的回调函数,实现所需
Keras使用手册网址:Keras Documentation(英文版)Keras 中文文档(中文版)
中文版的使用手册部分内容无法查看,但可在英文版中查询所有
Keras使用手册可输入查询,但查询函数时,需要在函数前添加 ` (英文格式的反引号,键盘上的波浪线所在按键,其下方表示的符号),同时函数输入不需要添加 ()
动态调整学习率
本教程参考 Keras学习率调整 实现,该篇博客还提出了两种调整学习率的方法,博主仅使用了其中的一种,也是最常用的方法
# 动态调整学习率lr
def scheduler(epoch):
lr = K.get_value(model.optimizer.lr)
# // 取整除 - 向下取接近商的整数
# ** 幂 - 返回x的y次幂
K.set_value(model.optimizer.lr, lr * (0.1 ** (epoch // lr_epochs)))
return K.get_value(model.optimizer.lr)
lr_new = LearningRateScheduler(scheduler)
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, callbacks=[lr_new], validation_data=(x_test, y_test))
其中,对于 LearningRateScheduler 的描述,中文文档给出了如下的回答

而 scheduler 函数并没有具体的描述,但可在其内部,通过 K.get_value(model.optimizer.lr) 获取当前学习率,用 K.set_value(model.optimizer.lr, lr * (0.1 ** (epoch // lr_epochs))) 修改学习率,而后将其加入LearningRateScheduler
在模型训练的函数中需要添加回调 callbacks=[lr_new],以实现学习率的动态调整
至此,在模型的训练过程中,将会以每一epoch的周期自动修改学习率
保存最佳模型
该部分涉及 ModelCheckpoint 的使用,其中文描述如下
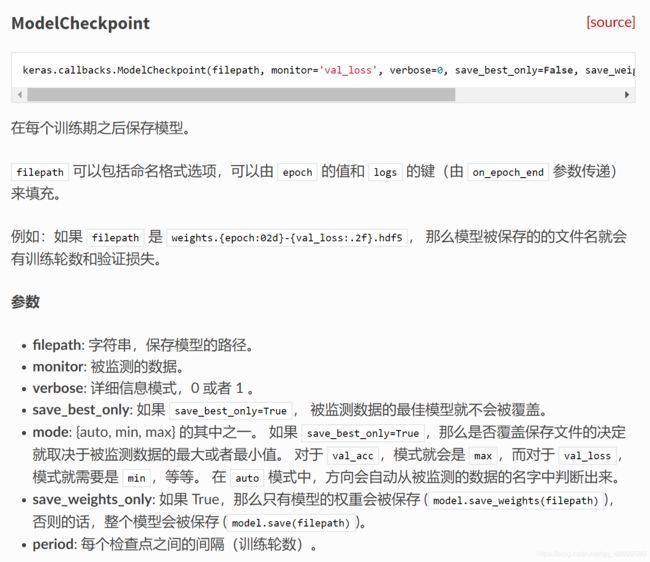
代码实现如下,其中的具体参数上图已作详细说明,就不再赘述,但同样是使用了回调函数,所以在模型训练的函数中要添加 callbacks=[checkpoint](若涉及准确率,需要在模型设置时,添加 metrics=[‘accuracy’] 参数)
model.compile(optimizer=adam, loss='categorical_crossentropy', metrics=['accuracy'])
# 保存最佳模型
filepath = 'weights.{epoch:02d}-{val_loss:.2f}.hdf5'
checkpoint = ModelCheckpoint(filepath, monitor='val_accuracy', verbose=1, save_best_only=True, mode='max')
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, callbacks=[checkpoint], validation_data=(x_test, y_test))
需要注意一下,文档中在使用 ModelCheckpoint 时,其参数 monitor 使用了 val_acc,但实际运行时该参数命名存在问题,需要修改为 val_accuracy
代码
最后将博主使用的完整代码附上,以MNIST数据集为例(没有优化),其中 def scheduler(epoch) 函数嵌套在了 def main() 函数中,算是Python的一个使用的便捷技巧
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense
from keras import optimizers
import keras.backend as K
from keras.callbacks import LearningRateScheduler, ModelCheckpoint
def main(batch_size=100, test_batch_size=100, lr=1e-3, momentum=0.9, decay=1e-5, epochs=10, lr_epochs=20):
# 载入数据
(x_train, y_train), (x_test, y_test) = mnist.load_data() # 自动从网络上下载
# x_shape: (60000, 28, 28)
# y_shape: (60000,)
# 数据格式转换,归一
# -1自动转换合适的数列
# (60000, 28, 28) -> (60000, 784)
x_train = x_train.reshape(x_train.shape[0], -1) / 255.0
x_test = x_test.reshape(x_test.shape[0], -1) / 255.0
# 转换one_hot格式,num_classes种类,数字有10个
y_train = np_utils.to_categorical(y_train, num_classes=10)
y_test = np_utils.to_categorical(y_test, num_classes=10)
# 创建模型,输入784个神经元,输出10个神经元
# bias_initializer偏置值初始化
model = Sequential([Dense(units=10, input_dim=784, bias_initializer='one', activation='softmax')])
# 定义优化器
# sgd = optimizers.SGD(lr=lr, momentum=momentum, decay=decay, nesterov=True)
adam = optimizers.Adam(lr=lr, beta_1=0.9, beta_2=0.999, epsilon=None, decay=decay, amsgrad=False)
# metrices=['accuracy']准确率
# categorical_crossentropy交叉熵
model.compile(optimizer=adam, loss='categorical_crossentropy', metrics=['accuracy'])
# 动态调整学习率lr
def scheduler(epoch):
lr = K.get_value(model.optimizer.lr)
# // 取整除 - 向下取接近商的整数
# ** 幂 - 返回x的y次幂
K.set_value(model.optimizer.lr, lr * (0.1 ** (epoch // lr_epochs)))
return K.get_value(model.optimizer.lr)
lr_new = LearningRateScheduler(scheduler)
# 保存最佳模型
filepath = 'weights.{epoch:02d}-{val_loss:.2f}.hdf5'
checkpoint = ModelCheckpoint(filepath, monitor='val_accuracy', verbose=1, save_best_only=True, mode='max')
# epochs迭代周期,图片全部训练一次为一周期
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, callbacks=[lr_new, checkpoint], validation_data=(x_test, y_test))
# 评估模型
loss, accuracy = model.evaluate(x_test, y_test, batch_size=test_batch_size)
print('\nFinally Test loss:', loss, '\taccuracy:', accuracy)
if __name__ == '__main__':
main()
该代码运行结果如下,仅展示部分内容

保存的最佳模型文件列表如下
