k8s学习笔记(10)--- kubernetes核心组件之controller manager详解
kubernetes核心组件之controller manager详解
- 一、Controller Manager简介
- 1.1 Replication Controller
- 1.2 Node Controller
- 1.3 ResourceQuota Controller
- 1.4 ResourceQuota Controller
- 1.5 Endpoint Controller
- 1.6 Service Controller
- 二、kube-controller-manager启动参数详解
- 三、kube-controller-manager安装部署
一、Controller Manager简介
Controller Manager作为集群内部的管理控制中心,负责集群内的Node、Pod副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的管理,当某个Node意外宕机时,Controller Manager会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。
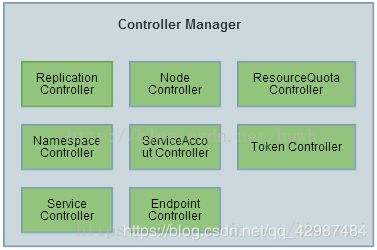
每个Controller通过API Server提供的接口实时监控整个集群的每个资源对象的当前状态,当发生各种故障导致系统状态发生变化时,会尝试将系统状态修复到“期望状态”。
1.1 Replication Controller
controller manager 中的 Replication controller(副本控制器) 和 K8S 中的资源 replication controller 不是同一个东西, 为了区别, 此处将资源类型的 replication controller 用RC 表示, controller manager 中的replication controller 仍然用 replication controller 表示,指代副本控制器。
replication controller 的核心作用是保障集群中某个 RC 关联的pod副本数与预设值一致. 当pod 重启策略为always 时(RestartPolicy=Always), Replication Controller 才会管理该 POD 的操作(创建, 销毁, 重启等), 在默认情况下, POD 对象被创建成功后不会消失, 唯一例外是当pod 处于succeed 或failed 状态的实践过长(超时参数由系统设定)时, 该pod 会被系统自动回收, 管理该 pod 的副本控制器将在其他工作节点上重新创建,运行该POD 副本。
RC 中的POD 模版就像模具, POD 一旦通过模版制作出来,就和RC 再也没有联系了. 无论模版如何变化, 甚至换成一个新的模版, 也不会影响到已经创建的POD . 因此POD 可以通过修改标签来脱离 RC 的管控. 改方法可以用于将POD 从集群中迁移, 数据修复等调试。
- replication controller 的职责
- 确保集群中有且仅有N 个POD的实例, N 是RC 中定义的POD 副本数量;
- 通过调整 RC 的 spec.replicas 属性值来扩容或缩容;
- 通过改变 RC 中的 POD 模版(主要是镜像), 来实现滚动升级;
- replication controller 的使用场景
- 重新调度。当发生节点故障或Pod被意外终止运行时,可以重新调度保证集群中仍然运行指定的副本数。
- 弹性伸缩。通过手动或自动扩容代理修复副本控制器的spec.replicas属性,可以实现弹性伸缩。
- 滚动升级。创建一个新的RC文件,通过kubectl 命令或API执行,则会新增一个新的副本同时删除旧的副本,当旧副本为0时,删除旧的RC。
当 RC 的spec.relicas 设置为0 时, 相关pod 将会被删除
1.2 Node Controller
kubelet在启动时会通过API Server注册自身的节点信息,并定时向API Server汇报状态信息,API Server接收到信息后将信息更新到etcd中。

Node Controller通过API Server实时获取Node的相关信息,实现管理和监控集群中的各个Node节点的相关控制功能。流程如下
- controller manager 判断是否有 --cluster-cidr 参数, 如果有在每个节点设置spec.PodCIDR 并保障cidr 不冲突;
- 逐个读取Node 信息, 多次尝试修改nodeStatusMap中的节点状态信息, 将该节点信息和 Node Controller 的 nodeStatusMap 中保存的信息作比较;
A. 如果判断出没有收到 kubelet 发送的信息, 第一次收到 kubelet 发送的的节点信息, 或在该处理过程中节点状态编程非"健康", 则在 nodeStatusMap 中保存该节点状态信息, 并用 Node Controller 所在节点的系统时间,作为探测时间和节点状态变化时间。
B. 如果判断出在指定时间内受到的新的节点信息, 且节点状态发生变化, 则在 nodeStatusMap 中保存该界节点的状态信息. 并用 Node Controller 所在节点的系统时间,作为探测时间和节点状态变化时间。
C. 如果判断出在指定时间内收到新的节点信息, 但状态没有变化则在 nodeStatusMap 中保存该节点的状态信息. 并用 Node Controller 所在节点的系统时间作为探测时间, 将上次节点信息中的节点状态变化时间作为该节点的状态变化时间. 如果判断出某段时间(gracePeriod) 内没有收到节点状态信息, 则设置节点状态为"位置", 并通过api server 保存节点状态。 - 逐个读取节点信息, 如果节点状态变为非"就绪"状态, 则将节点加入待删除队列, 否则将节点从该队列删除. 如果节点为非就绪状态, 且系统指定了 cloud provider, 则 Node Controller 调用 cloud provider 查看节点, 若发现节点故障 则删除etcd中的信息, 并删除该节点相关的pod 等资源信息。
1.3 ResourceQuota Controller
K8S 的配额管理是通过admiss control 来控制的, admission control 当前提供了两种方式进行配额约束, 分别是 LimitRanger 与 ResourceQuota. 其中 LimitRanger 作用于 POD 和 Container , ResourceQuota 作用于 Namespace。
资源配额管理确保指定的资源对象在任何时候都不会超量占用系统物理资源。 支持三个层次的资源配置管理:
1)容器级别:对CPU和Memory进行限制
2)Pod级别:对一个Pod内所有容器的可用资源进行限制
3)Namespace级别:包括Pod数量、Replication Controller数量、Service数量、ResourceQuota数量、Secret数量、可持有的PV(Persistent Volume)数量
1、k8s配额管理是通过Admission Control(准入控制)来控制的;
2、Admission Control提供两种配额约束方式:LimitRanger和ResourceQuota;
3、LimitRanger作用于Pod和Container;
4、ResourceQuota作用于Namespace上,限定一个Namespace里的各类资源的使用总额。
- ResourceQuota controller 流程图

1.4 ResourceQuota Controller
用户通过API Server可以创建新的Namespace并保存在etcd中,Namespace Controller定时通过API Server读取这些Namespace信息。
如果Namespace被API标记为优雅删除(即设置删除期限,DeletionTimestamp),则将该Namespace状态设置为“Terminating”,并保存到etcd中。同时Namespace Controller删除该Namespace下的ServiceAccount、RC、Pod等资源对象。
1.5 Endpoint Controller
Endpoints表示了一个Service对应的所有Pod副本的访问地址,而Endpoints Controller负责生成和维护所有Endpoints对象的控制器。它负责监听Service和对应的Pod副本的变化。
如果监测到Service被删除,则删除和该Service同名的Endpoints对象;
如果监测到新的Service被创建或修改,则根据该Service信息获得相关的Pod列表,然后创建或更新Service对应的Endpoints对象。
如果监测到Pod的事件,则更新它对应的Service的Endpoints对象。
Service、Endpoint、Pod的关系:

kube-proxy进程获取每个Service的Endpoints,实现Service的负载均衡功能。
1.6 Service Controller
Service Controller是属于kubernetes集群与外部的云平台之间的一个接口控制器。Service Controller监听Service变化,如果是一个LoadBalancer类型的Service,则确保外部的云平台上对该Service对应的LoadBalancer实例被相应地创建、删除及更新路由转发表。
二、kube-controller-manager启动参数详解
Usage:
kube-controller-manager [flags]
- Debugging flags
| 参数 | 说明 |
|---|---|
| --contention-profiling | 启用了 profiling,则启用锁争用性分析 |
| --profiling | 开启profilling,通过web接口host:port/debug/pprof/分析性能 |
- Generic flags
| 参数 | 说明 |
|---|---|
| --allocate-node-cidrs | 是否应在云提供商上分配和设置Pod的CIDR |
| --cidr-allocator-type string | CIDR分配器的类型 (default “RangeAllocator”) |
| --cloud-config string | 云提供商配置文件路径,空代表没有配置文件 |
| --cloud-provider string | 云提供商,空代表没有云提供商 |
| --cluster-cidr string | 集群中Pod的CIDR范围,要求–allocate-node-cidrs为true |
--cluster-name string |
集群的实例前缀(default “kubernetes”) |
| --configure-cloud-routes | 是否在云提供商上配置allocate-node-cidrs分配的CIDR(default true) |
| --controller-start-interval duration | 启动controller manager的间隔时间 |
| --controllers strings | 需要开启的controller列表,*代表开启所有(默认),‘foo’代表开启foo controller,‘-foo’代表禁止foo controller。 所有的controller如下: attachdetach, bootstrapsigner, clusterrole-aggregation,cronjob, csrapproving, csrcleaner, csrsigning, daemonset,deployment, disruption, endpoint, garbagecollector,horizontalpodautoscaling, job, namespace, nodeipam, nodelifecycle, persistentvolume-binder, persistentvolume-expander, podgc, pv-protection,pvc-protection, replicaset, replicationcontroller,resourcequota, route, service, serviceaccount, serviceaccount-token,statefulset, tokencleaner, ttl,ttl-after-finished |
| --feature-gates mapStringBool | key = value对,用于试验 |
| --kube-api-burst int32 | 发送到kube-apiserver每秒请求量 (default 100) |
| --kube-api-content-type string | 发送到kube-apiserver请求内容类型(default “application/vnd.kubernetes.protobuf”) |
| --kube-api-qps float32 | 与kube-apiserver通信的qps(default 50) |
--leader-elect |
多个master情况设置为true保证高可用,进行leader选举 |
| --leader-elect-lease-duration duration | 当leader-elect设置为true生效,选举过程中非leader候选等待选举的时间间隔(default 15s) |
| --leader-elect-renew-deadline duration | eader选举过程中在停止leading,再次renew时间间隔,小于或者等于leader-elect-lease-duration duration,也是leader-elect设置为true生效(default 10s) |
| --leader-elect-retry-period duration | 当leader-elect设置为true生效,获取leader或者重新选举的等待间隔(default 2s) |
| --min-resync-period duration | 重新同步周期,在 [MinResyncPeriod-2 * MinResyncPeriod]间取随机值(default 12h0m0s) |
| --node-monitor-period duration | NodeController同步NodeStatus的时间间隔(default 5s) |
| --route-reconciliation-period duration | 协调由云提供商为节点创建的路由的时间间隔 (default 10s) |
| --use-service-account-credentials | 设置true为每个控制器使用单个service account |
- Service controller flags
| 参数 | 说明 |
|---|---|
| --concurrent-service-syncs int32 | 允许同时同步的 service 数量。 数字越大=服务管理响应越快,但消耗更多 CPU 和网络资源 |
- Secure serving flags
| 参数 | 说明 |
|---|---|
--bind-address ip |
监听–secure-port端口的IP地址(default 0.0.0.0) |
--cert-dir string |
TLS证书所在的目录。如果提供了–tls-cert-file和–tls-private-key-file,则将忽略此标志(default “/var/run/kubernetes”) |
| --http2-max-streams-per-connection int | api server 提供给 client 的HTTP / 2最大 stream 连接数。0 用golang的默认值 |
--secure-port int |
使用身份验证和授权提供服务的HTTPS端口。0禁用HTTPS |
| --tls-cert-file string | 文件包含HTTPS的默认x509证书的文件。 (如果有CA证书,在服务器证书之后级联)。如果启用了HTTPS服务,但是 --tls-cert-file和–tls-private-key-file 未设置,则会为公共地址生成自签名证书和密钥,并将其保存到–cert-dir的目录中 |
| --tls-cipher-suites strings | 逗号分隔的cipher suites列表。如果省略则使用默认的Go cipher suites |
| --tls-min-version string | 支持最低TLS版本。 主要有:VersionTLS10,VersionTLS11,VersionTLS12 |
| --tls-private-key-file string | 文件包括与 --tls-cert-file 匹配的默认x509私钥 |
| --tls-sni-cert-key namedCertKey | x509证书和私钥对的文件路径(default []) Examples: “example.crt,example.key” or “foo.crt,foo.key:*.foo.com,foo.com” |
- Insecure serving flags
| 参数 | 说明 |
|---|---|
--address ip |
为不安全端口提供服务的IP地址(对于所有IPv4设置为0.0.0.0)接口和::所有IPv6接口)。(默认值0.0.0.0)(已弃用:参见 --bind-address代替。) |
--port int |
为不安全、未经身份验证的访问提供服务的端口。设置为0禁用。(默认10252)(弃用:参见 --secure-port) |
- Authentication flags
| 参数 | 说明 |
|---|---|
| --authentication-kubeconfig string | kubeconfig文件指向有权力创建tokenaccessreviews.authentication.k8s.io的核心kubernetes server,如果未设置所有的token请求被视为匿名的,在集群中也不查找client CA |
| --authentication-skip-lookup | 如果设置false,authentication-kubeconfig用来在集群中查找缺失的authentication配置 |
| --authentication-token-webhook-cache-ttl duration | 来自webhook token验证器的缓存响应时间 (default 10s) |
| --client-ca-file string | 如果设置任何请求必须提供其中一个客户端证书签名。则用其中的 Common Name 作为请求的用户名验证 |
| --requestheader-allowed-names strings | 客户端证书通用名称列表,允许在–requestheader-username-headers指定的标头中提供用户名。如果为空,则允–requestheader-client-ca-file中验证的任何客户端证书。 |
| --requestheader-client-ca-file string | 根证书包,用于在信任由–requestheader-username-headers指定的头文件中的用户名之前对传入请求验证客户端证书。警告:通常不要依赖于对传入请求已经进行的授权。 |
| --requestheader-extra-headers-prefix strings | 要检查的请求头前缀列表。建议X-Remote-Extra-。(默认[x-remote-extra -]) |
| --requestheader-group-headers strings | 要检查组的请求标头列表。建议X-Remote-Group。(默认[x-remote-group]) |
| --requestheader-username-headers strings | 检查用户名的请求头列表。X-Remote-User是常用的。(默认[x-remote-user]) |
- Authorization flags
| 参数 | 说明 |
|---|---|
| --authorization-always-allow-paths strings | 授权期间要跳过的HTTP路径列表,这些路径是经过授权、无须与’核心’kubernetes服务通信(default [/healthz]) |
| --authorization-kubeconfig string | kubeconfig指向核心的kubernetes服务拥有足够的权力来创建subjectaccessreviews.authorization.k8s.io,也是可选项,如果未设置,则所有请求将被禁止 |
| --authorization-webhook-cache-authorized-ttl duration | 从webhook授权器对于cache验证响应时间(default 10s) |
| --authorization-webhook-cache-unauthorized-ttl duration | 从webhook授权器对于cache验证未响应时间(default 10s) |
- Attachdetach controller flags
| 参数 | 说明 |
|---|---|
| --attach-detach-reconcile-sync-period duration | 在volume attach detach调整同步等待时间,时间间隔必须大于1s,增加默认值可能导致volume与pod不匹配(default 1m0s) |
| --disable-attach-detach-reconcile-sync | 禁止volume attach detach 调整同步,禁用此功能可能会导致卷与 pod 不匹配 |
- Csrsigning controller flags
| 参数 | 说明 |
|---|---|
--cluster-signing-cert-file string |
包含peme编码的X509 CA证书的文件名,用于发出集群范围的证书(默认为“/etc/kubernetes/ CA / CA .pem”) |
--cluster-signing-key-file string |
包含pemm编码的RSA或ECDSA私有密钥的文件名,用于对集群范围的证书进行签名(默认为“/etc/kubernetes/ca/ca.key”) |
| --experimental-cluster-signing-duration duration | 签署证书的期限将会被给出。(默认8760h0m0s) |
- Deployment controller flags
| 参数 | 说明 |
|---|---|
| --concurrent-deployment-syncs int32 | 允许同时同步的deployment对象的数量,部署数量越大需要的CPU网络load也多(default 5) |
| --deployment-controller-sync-period duration | 同步deployment的周期(default 30s) |
- Endpoint controller flags
| 参数 | 说明 |
|---|---|
| --concurrent-endpoint-syncs int32 | 同时同步endpoint的数量,也是数量越多需要越多的CPU和network(default 5) |
- Garbagecollector controller flags
| 参数 | 说明 |
|---|---|
| --concurrent-gc-syncs int32 | 允许同时同步的garbage collector workers数量(default 20) |
| --enable-garbage-collector | 启用通用垃圾收集器,必须与kube-apiserver的相应参数一起使用(default true) |
- Horizontalpodautoscaling controller flags
| 参数 | 说明 |
|---|---|
| --horizontal-pod-autoscaler-cpu-initialization-period duration | 当CPU samples略过,在pod启动之后的周期(default 5m0s) |
| --horizontal-pod-autoscaler-downscale-stabilization duration | autoscaler将向后查看并且不会缩小到低于其在此期间提出的任何建议的时间段(default 5m0s) |
| --horizontal-pod-autoscaler-initial-readiness-delay duration | pod启动后的一段时间,在此期间战备状态的变化将被视为初始战备状态(默认为30秒) |
| --horizontal-pod-autoscaler-sync-period duration | The period for syncing the number of pods in horizontal pod autoscaler. (default 15s) |
| --horizontal-pod-autoscaler-tolerance float | 水平pod自动调度器所需的实际度量比的最小变化(从1.0开始)需要考虑缩放。(default 0.1) |
- Namespace controller flags
| 参数 | 说明 |
|---|---|
| --concurrent-namespace-syncs int32 | 允许并发同步的名称空间对象的数量。更大的数字=响应更快的名称空间终止,但是更多的CPU(和网络)负载(默认为10) |
| --namespace-sync-period duration | 同步namespace生命周期更新的周期(default 5m0s) |
- Nodeipam controller flags
| 参数 | 说明 |
|---|---|
| --node-cidr-mask-size int32 | 集群中节点子网掩码打小(default 24) |
--service-cluster-ip-range string |
集群service的cidr范围,需要–allocate-node-cidrs设置为true |
- Nodelifecycle controller flags
| 参数 | 说明 |
|---|---|
| --enable-taint-manager | 如果设置为true则开启NoExecute Taints,将驱逐所有节点上(拥有这种污点的节点)不容忍运行pod (default true) |
| --large-cluster-size-threshold int32 | NodeController出于驱逐逻辑目的而将集群视为大节点的节点数量。对于这种大小或更小的集群(默认为50),–secondary-node-eviction-rate被隐式覆盖为0 |
| --node-eviction-rate float32 | 当zone健康node失败情况,删除节点上的pod的速率 (default 0.1) |
| --node-monitor-grace-period duration | 在标记节点不健康之前,允许运行节点不响应的时间,必须是n倍的kubelet’s nodeStatusUpdateFrequency,N意味着kubelet报告node状态重试的次数(default 40s) |
| --node-startup-grace-period duration | 在标记节点不健康之前,允许开始节点不响应的时间 (default 1m0s) |
| --pod-eviction-timeout duration | 在失败的节点上删除pod的宽限时间 (default 5m0s) |
| --secondary-node-eviction-rate float32 | 当zone不健康node失败情况,删除节点上的pod的速率,如果集群大小小于 large-cluster-size-threshold,则隐式地将设置为0。(default 0.01) |
| --unhealthy-zone-threshold float32 | not ready 节点(至少3个)的比例达到该值时,将 Zone 标记为不健康 (default 0.55) |
- Persistentvolume-binder controller flags
| 参数 | 说明 |
|---|---|
| --enable-dynamic-provisioning | 为支持它的环境启用动态配置 (default true) |
| --enable-hostpath-provisioner | 当没有云提供商运行时开启host path pv配置,这主要适合测试以及开发配置features,host path配置不支持多点集群 |
| --flex-volume-plugin-dir string | 第三方插件路径 (default “/usr/libexec/kubernetes/kubelet-plugins/volume/exec/”) |
| --pv-recycler-increment-timeout-nfs int32 | NFS scrubber pod添加每Gi到ActiveDeadlineSeconds的时间增量(default 30) |
| --pv-recycler-minimum-timeout-hostpath int32 | 对于HostPath Recycler pod的最小ActiveDeadlineSeconds,仅使用于测试于开发,不使用于多几点集群 (default 60) |
| --pv-recycler-minimum-timeout-nfs int32 | 对于NFS Recycler pod的最小ActiveDeadlineSeconds (default 300) |
| --pv-recycler-pod-template-filepath-hostpath string | 对于hostpaht持久卷重使用定义的模板路径,仅使用于测试于开发,不使用于多几点集群 |
| --pv-recycler-timeout-increment-hostpath int32 | 对于HostPath scrubber pod每增加Gi到ActiveDeadlineSeconds的时间增量,仅使用于测试于开发,不使用于多几点集群 (default 30) |
| --pvclaimbinder-sync-period duration | 同步pv以及pvc的周期 (default 15s) |
- Podgc controller flags
| 参数 | 说明 |
|---|---|
| --terminated-pod-gc-threshold int32 | 当终止的pod达到该值时,pod garbage collector开始删除终止pod,如果设置<=0,关闭pod garbage collector (default 12500) |
- Replicaset controller flags
| 参数 | 说明 |
|---|---|
| --concurrent-replicaset-syncs int32 | 允许同时同步的rs数量,Larger number = more responsive replica management, but more CPU (and network) load (default 5) |
- Replicationcontroller flags
| 参数 | 说明 |
|---|---|
| --concurrent_rc_syncs int32 | 允许并发同步的复制控制器的数目。更大的数字=响应更快的副本管理,但是更多的CPU(和网络)负载(默认5) |
- Resourcequota controller flags
| 参数 | 说明 |
|---|---|
| --concurrent-resource-quota-syncs int32 | 允许并发同步的资源配额数量。更大的数字=响应性更好的配额管理,但是更多的CPU(和网络)负载(默认5) |
| --resource-quota-sync-period duration | 在系统中同步配额使用状态的周期 (default 5m0s) |
- Serviceaccount controller flags
| 参数 | 说明 |
|---|---|
| --concurrent-serviceaccount-token-syncs int32 | 允许并发同步的服务帐户令牌对象的数量。更大的数字=响应性更好的令牌生成,但是更多的CPU(和网络)负载(默认5) |
--root-ca-file string |
根CA 证书文件路径,如果设置的话将被用于 Service Account 的 token secret 中 |
--service-account-private-key-file string |
包含用于对服务帐户令牌签名的pemm编码的私有RSA或ECDSA密钥的文件名 |
- Ttl-after-finished controller flags
| 参数 | 说明 |
|---|---|
| --concurrent-ttl-after-finished-syncs int32 | 允许并发同步的ttl后完成的控制器工作人员的数量。(默认5) |
- Misc flags
| 参数 | 说明 |
|---|---|
| --insecure-experimental-approve-all-kubelet-csrs-for-group string | This flag does nothing. |
| --kubeconfig string | kubeconfig文件路径,带有验证以及master信息 |
--master string |
kubernetes api server的地址,将会覆盖kubeconfig设置的值 |
三、kube-controller-manager安装部署
注意:以下kube-schedule安装部署是在k8s的etcd、apiserver组件已部署后的前提下部署验证的;
-
下载地址:https://github.com/kubernetes/kubernetes (包含了k8s所必须的组件,如kube-apiserver、kubelet、kube-scheduler、kube-controller-manager等等)
1.在windows下进入https://github.com/kubernetes/kubernetes后,点击如CHANGELOG-1.16.md文件查看对应的版本(1.16版本)和下载的文件;
2.选择Server Binaries的kubernetes-server-linux-amd64.tar.gz下载;
3.在windows下载后通过lrzsz工具执行rz上传到linux上(linux上无法直接通过wget https://dl.k8s.io/v1.16.4/kubernetes.tar.gz下载);
4.解压后生成kubernetes目录,把/kubernetes/service/bin/下的kube-controller-manager复制到/opt/kubernetes/bin下; -
创建controller manager配置文件kube-controller-manager
cat > /opt/kubernetes/cfg/kube-controller-manager < -
systemd管理controller manager,创建kube-controller-manager服务文件
cat > /usr/lib/systemd/system/kube-controller-manager.service < -
启动kube-controller-manager服务
systemctl daemon-reload systemctl enable kube-scheduler systemctl start kube-scheduler -
验证kube-controller-manager服务是否启动成功
systemctl status kube-controller-manager 若失败可通过查看服务日志定位问题: journalctl _PID=|vim - 执行命令查看scheduler组件是否健康正常 kubectl get cs controller-manager -o yaml
本文仅是个人学习时的整理收藏,以便回顾所用,内容均来源其它处。
[参考文档]https://kubernetes.io/zh/docs/reference/command-line-tools-reference/kube-controller-manager/