爬虫入门:爬取猫眼电影TOP100
注意:该作者博客已迁移至https://buxianshan.xyz
参考《Python3网络爬虫开发实战》 作者:崔庆才
爬取结果
控制台输出:序号+电影名称+评分
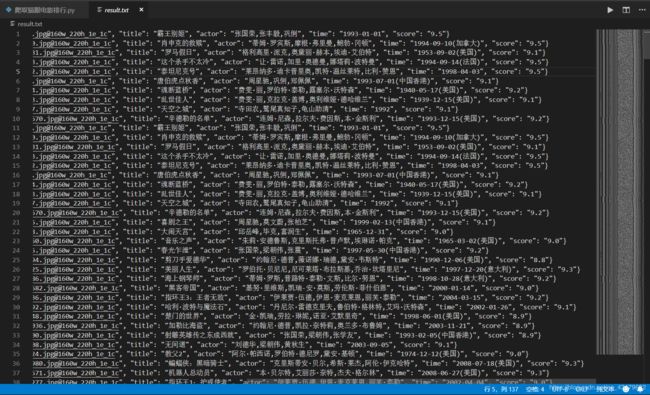
同时保存完整信息到本地文件 result.txt
完整代码
import requests
import re
import json
def get_one_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
def parse_one_page(html):
pattern = re.compile(
'.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?).*?star.*?>(.*?).*?releasetime.*?>(.*?).*?integer.*?>(.*?).*?fraction.*?>(.*?).*? ',
re.S
)
items = re.findall(pattern, html)
for item in items:
yield{
'index':item[0],
'image':item[1],
'title':item[2].strip(),
'actor':item[3].strip()[3:] if len(item[3]) > 3 else '',
'time':item[4].strip()[5:] if len(item[4]) > 5 else '',
'score':item[5].strip() + item[6].strip()
}
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f:
# print(type(json.dumps(content)))
f.write(json.dumps(content, ensure_ascii=False) + '\n')
def main(offset):
url = 'https://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item['index'] + '《' + item['title'] + '》 ' + '评分:' + item['score'])
write_to_file(item)
if __name__=="__main__":
for i in range(10):
main(offset=i*10)