python网络爬虫与信息提取1-规则
网络爬虫之规则
requests.get(url,params=None,**kwargs)
url:拟获取页面的url连接
params:url中的额外参数,字典或字节流格式,可选
**kwargs:12个控制访问的参数

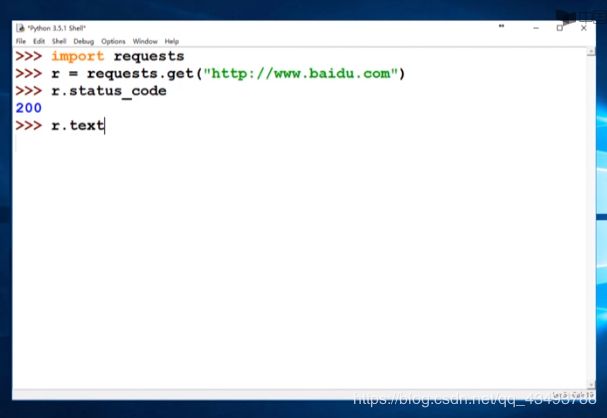
requests 库的两个重要对象:response(包含爬虫返回的内容)、request

response对象的属性
| 属性 | 说明 |
|---|---|
| r.status_code | HTTP请求的返回状态,200-连接成功,100-失败 |
| r.text | HTTP响应内容的字符串形式,即,url对应的页面内容 |
| r.encoding | 从HTTP header 中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析的响应内容编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式 |
r.encoding:如果header中不存在charset,则认为编码为ISO-8859-1
r.apparent_encoding:根据网页内容分析出的编码方式

理解requests库的异常
| 异常 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败、拒绝连接等 |
| requests. HTTPError | HTTP错误异常 |
| requests. URLRequired | url缺失异常 |
| requests. TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests. ConnectTimeout | 连接远程服务器超时异常 |
| requests. Timeout | 请求url超时,产生超时异常 |
| r.raise_for_status() | 如果不是200,产生异常requests. HTTPError |

requests库的7个主要方法
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑以下各方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的get |
| requests.head() | 获取HTML网页头信息的主要方法,对应于HTTP的head |
| requests.post() | 向HTTP网页提交post请求的方法,对应于HTTP的post |
| requests.put() | 向HTTP网页提交put请求的方法,对应于HTTP的put |
| requests.patch() | 向HTTP网页提交局部修改请求,对应于HTTP的patch |
| requests.delete() | 向HTTP网页提交删除请求,对应于HTTP的delete |
| HTTP协议 |
|---|
| hypertext transfer protocol, 超文本传输协议 |
| HTTP是一个基于“请求与响应”模式的、无状态的应用层协议 |
| HTTP协议采用url作为定位网络资源的标识 |
url格式 http.//host[:port][path]
host:合法的Internet主机域名或IP地址
port:端口号,缺省端口为80
path:请求资源的路径
HTTP协议对资源的操作
| 方法 | 说明 |
|---|---|
| get | 请求获取url位置的资源 |
| head | 请求获取url位置资源的响应消息报告,即获取该资源的头部信息 |
| post | 请求获取url位置的资源后附加新的信息 |
| put | 请求获取url位置存储一个资源,覆盖原url位置的资源 |
| patch | 请求局部更新url位置的资源,即改变该处资源的部分内容 |
| delete | 请求删除url位置存储的资源 |

patch和put的区别
假设url位置有一组数据UserInfo,包括UserID、UserName等20个字段。
需求:用户修改了UserName,其他不变
- 采用patch,仅向url提交UserName的局部更新请求。
- 采用put,必须将所有20个字段一并提交到url,未提交字段被删除
patch的最主要好处:节省网路带宽
HTTP协议与requests库
| HTTP协议方法 | requests库方法 | 功能一致性 |
|---|---|---|
| get | requests.get() | 一致 |
| head | requests.head() | 一致 |
| post | requests.post() | 一致 |
| put | requests.put() | 一致 |
| patch | requests.patch() | 一致 |
| delete | requests.delete() | 一致 |




requests.request(method,url,**kwargs) #13
requests.get(url,params=None,**kwargs) #12
requests.head(url,**kwargs) #13
requests.post(url,data=None,,json=None,**kwargs) #11
requests.put(url,data=None,**kwargs) #12
requests.patch(url,data=None,**kwargs) #12
requests.delete(url,**kwargs) #13
method:请求方式,对应get/put/post等七种
url:拟获取页面的url连接
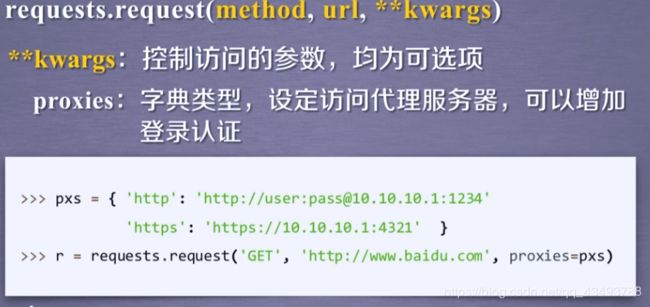
**kwargs:控制访问的参数
params:url中的额外参数,字典或字节流格式,可选
data:字典、字节序列或文件,request的内容
json:JSON格式的数据,request的内容
如:
requests.request('GET',url,**kwargs)
requests.request('HEAD',url,**kwargs)
requests.request('POST',url,**kwargs)
requests.request('PUT',url,**kwargs)
requests.request('PATCH',url,**kwargs)
requests.request('delete',url,**kwargs)
requests.request('OPTIONS',url,**kwargs)
**kwargs:
| params | cookies | proxies | cert |
| data | auth | allow_redirects | |
| json | files | stream | |
| hesders | timeout | verify |








try:
r = requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("爬取失败")
网络爬虫的尺寸
| 小规模,数据量小,爬取速度不敏感 | 中规模,数据规模较大,爬取速度敏感 | 大规模,搜索引擎,爬取速度关键 |
| requests库 | scrapy库 | 定制开发 |
| 爬取网页 玩转网页 | 爬取网页 爬取系列网站 | 爬取全网 |
网络爬虫的限制
- 来源审查:判断User-Agent进行限制
检查来访HTTP协议头的User-Agent域,只响应浏览器或好友爬虫的访问。 - 发布公告:Robots协议
告知所有爬虫网站的爬取策略,要求爬虫遵守
实例1(京东商品页面的爬取)
>>> import requests
>>> r = requests.get("https://item.jd.com/100010640208.html")
>>> r.status_code
200
>>> r.encoding
'gbk'
>>> r.text[:1000]
京东页面提取全代码:
import requests
url="https://item.jd.com/100010640208.html"
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败")
实例2(亚马逊商品页面的爬取)
>>> import requests
>>> r = requests.get("https://www.amazon.cn/dp/B07ZVPY6KY/ref=s9_acsd_hps_bw_c2_x_0_i")
>>> r.status_code
503
>>> r.encoding
'ISO-8859-1'
>>> r.encoding = r.apparent_encoding
>>> t.text[:1000]
Traceback (most recent call last):
File "" , line 1, in <module>
t.text[:1000]
NameError: name 't' is not defined
>>> r.text[:1000]
'\n\n\n\n\n\n\n\n\nAmazon CAPTCHA \n\n\n\n\r\n\r\n'
>>>
IP地址查询全代码:
import requests
url = "http://m.ip138.com/ip.asp?ip="
try:
r = requests.get(url + '202.204.80.112')
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[-500:])
except:
print("爬取失败")