数据挖掘①单文本分析之词频统计
目录
- A 任务说明
- B 要求
- C 进阶
- D 覆盖的知识点(学习)
- 一.自然语言分析的基本术语
- 二. jieba模块学习
- 1.安装jieba模块
- 2.jieba模块常用
- (1)分词
- (2)添加自定义字典
- (3)调整词典
- (5)基于 TF-IDF 算法的关键词抽取
- (6)基于 TextRank 算法的关键词抽取
- (7)词性标注
- (8)并行分词
- (10)搜索模式
- (9)延迟加载机制
- 3.读取不同格式文本的方法
- ~实操
- 一. txt篇
- 二. doc文档篇
- 三.pdf篇
A 任务说明
读取单个文本内容(txt,word,pdf),对文章进行分词(中文),并统计每个词语出现的次数并按从大到小排序。同时通过停用词库排除停用词,并展示结果。
B 要求
- 自选3篇文章,读取单个文本内容(txt,word,pdf),对文章进行分词(中文),使用jieba模块
- 统计每个词语出现的次数并按从大到小排序,导出邻接矩阵,同时通过停用词库排除停用词,并展示结果。统计词频时注意兼顾速度。
C 进阶
优化统计词频的算法减少统计词频的时间
D 覆盖的知识点(学习)
(1)掌握自然语言分析的基本术语:词频,停用词
(2)jieba模块的使用
(3)读取不同格式文本的方法
一.自然语言分析的基本术语
①词频:(TF)百科解释(click me)
即:词频 (TF) 是指的是某一个给定的词语在该文件中出现的次数。
是一词语出现的次数除以该文件的总词语数。
②逆向文件频率:(IDF)是一个词语普遍重要性的度量。
某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
eg:
一篇文件的总词语数是100个,
而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是 0.03 (3/100)。
一个计算文件频率 (DF) 的方法是测定有多少份文件出现过“母牛”一词,然后除以文件集里包含的文件总数。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是 9.21=( ln(10,000,000 / 1,000) )。
最后的TF-IDF的分数为0.28=( 0.03 * 9.21)。
③停用词:百科解释 click me
为节省存储空间和提高搜索效率,搜索引擎在索引页面或处理搜索请求时会自动忽略某些字或词,这些字或词即被称为Stop Words(停用词)。通常意义上,Stop Words大致为如下两类:
1.这些词应用十分广泛,在Internet上随处可见。
2、例如语气助词、副词、介词、连接词等,通常自身 并无明确的意义,只有将其放入一个完整的句子中才有一定作用,如常见的“的”、“在”之类。
④隐马尔可夫模型: 百科解释 click me
二. jieba模块学习
1.安装jieba模块
pip install jieba
注意:如果是要用 pycharm,则在config-settings-Project Interpreter-(+号)导包jieba(download)
2.jieba模块常用
1.官方文档详见read me(https://github.com/fxsjy/jieba)
2.主要功能:所有详细例子见官方文档https://github.com/fxsjy/jieba/blob/master/test/demo.py
(感谢各位帮助我学习jieba模块的大佬!!!)
(1)分词
① jieba.cut
②jieba.cut_for_search
③jieba,lcut(返回列表)
④jieba.lcut_for_search(返回列表)
⑤jieba.Tokenizer(dictionary=DEFAULT_DICT)(新建自定义分词器,可用于同时使用不同词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。)
代码实例:
# encoding=utf-8
import jieba
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
输出效果
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
【精确模式】: 我/ 来到/ 北京/ 清华大学
【新词识别】:他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了)
【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
(2)添加自定义字典
①开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率
②用法: jieba.load_userdict(file_name)
#file_name 为文件类对象或自定义词典的路径
③词典格式和 dict.txt 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码。
④词频省略时使用自动计算的能保证分出该词的词频。
实例:
1.自定义词典(userdict.text文件)
云计算 5
李小福 2 nr
创新办 3 i
easy_install 3 eng
好用 300
韩玉赏鉴 3 nz
八一双鹿 3 nz
台中
凱特琳 nz
Edu Trust认证 2000
2.用法示例
#encoding=utf-8
from __future__ import print_function, unicode_literals
import sys
sys.path.append("../")
import jieba
jieba.load_userdict("userdict.txt")
import jieba.posseg as pseg
jieba.add_word('石墨烯')
jieba.add_word('凱特琳')
jieba.del_word('自定义词')
test_sent = (
"李小福是创新办主任也是云计算方面的专家; 什么是八一双鹿\n"
"例如我输入一个带“韩玉赏鉴”的标题,在自定义词库中也增加了此词为N类\n"
"「台中」正確應該不會被切開。mac上可分出「石墨烯」;此時又可以分出來凱特琳了。"
)
words = jieba.cut(test_sent)
print('/'.join(words))
print("="*40)
result = pseg.cut(test_sent)
for w in result:
print(w.word, "/", w.flag, ", ", end=' ')
print("\n" + "="*40)
terms = jieba.cut('easy_install is great')
print('/'.join(terms))
terms = jieba.cut('python 的正则表达式是好用的')
print('/'.join(terms))
print("="*40)
# test frequency tune
testlist = [
('今天天气不错', ('今天', '天气')),
('如果放到post中将出错。', ('中', '将')),
('我们中出了一个叛徒', ('中', '出')),
]
for sent, seg in testlist:
print('/'.join(jieba.cut(sent, HMM=False)))
word = ''.join(seg)
print('%s Before: %s, After: %s' % (word, jieba.get_FREQ(word), jieba.suggest_freq(seg, True)))
print('/'.join(jieba.cut(sent, HMM=False)))
print("-"*40)
之前:李小福 / 是 / 创新 / 办 / 主任 / 也 / 是 / 云 / 计算 / 方面 / 的 / 专家 /
之后:李小福 / 是 / 创新办 / 主任 / 也 / 是 / 云计算 / 方面 / 的 / 专家 /
(3)调整词典
- add_word(word, freq=None, tag=None)(见上面代码块)
- del_word(word) (见上面代码块)
- 使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
have a try!!!
#coding:utf-8
import jieba
words =jieba.cut("我们中出了一个叛徒",HMM=False)
print('/'.join(words))
#coding:utf-8
import jieba
words =jieba.cut("我们中出了一个叛徒",HMM=False)
jieba.suggest_freq(('中出'),True)
print('/'.join(words))
#coding:utf-8
import jieba
words =jieba.cut("我们中出了一个叛徒",HMM=False)
jieba.suggest_freq(('中出'),True)
jieba.suggest_freq(('中','出'),True)
print('/'.join(words))
- 注意:自动计算的词频在使用 HMM 新词发现功能时可能无效。
关键字提取:
(5)基于 TF-IDF 算法的关键词抽取
import sys #其实sys.path是一个列表,这个列表内的路径都添加到环境变量中去了。
sys.path.append('../') #使用sys.path.append()方法可以添加自定义的路径。这种方法是运行时修改,脚本运行后就会失效的。
import jieba
import jieba.analyse
from optparse import OptionParser #optparse是专门用来在命令行添加选项的一个模块。
#################################################################
USAGE = "usage: python extract_tags.py [file name] -k [top k]"
#################################################################
parser = OptionParser(USAGE)
parser.add_option("-k", dest="topK")
opt, args = parser.parse_args()
if len(args) < 1:
print(USAGE)
sys.exit(1)
file_name = args[0]
if opt.topK is None:
topK = 10
else:
topK = int(opt.topK)
content = open(file_name, 'rb').read()
######################################################
tags = jieba.analyse.extract_tags(content, topK=topK)
######################################################
'''
1.jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
sentence 为待提取的文本
2.topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
3.withWeight 为是否一并返回关键词权重值,默认值为 False
4.allowPOS 仅包括指定词性的词,默认值为空,即不筛选
5.jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件'''
print(",".join(tags))
关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径
用法: jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
关键词提取所使用停止词(Stop Words)文本语料库可以切换成自定义语料库的路径
用法: jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径
关键词一并返回关键词权重值示例
(6)基于 TextRank 算法的关键词抽取
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))
直接使用,接口相同,注意默认过滤词性。
jieba.analyse.TextRank() 新建自定义 TextRank 实例
(7)词性标注
>>> import jieba.posseg as pseg
>>> words = pseg.cut("我爱北京天安门")
>>> for word, flag in words:
... print('%s %s' % (word, flag))
...
我 r
爱 v
北京 ns
天安门 ns
(8)并行分词
result = jieba.tokenize(u'永和服装饰品有限公司')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
word 永和 start: 0 end:2
word 服装 start: 2 end:4
word 饰品 start: 4 end:6
word 有限公司 start: 6 end:10
(10)搜索模式
result = jieba.tokenize(u'永和服装饰品有限公司', mode='search')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
word 永和 start: 0 end:2
word 服装 start: 2 end:4
word 饰品 start: 4 end:6
word 有限 start: 6 end:8
word 公司 start: 8 end:10
word 有限公司 start: 6 end:10
(9)延迟加载机制
(先挖个坑以后来补)
3.读取不同格式文本的方法
推荐博客(click ME)
~实操
查看源码(click me)
一. txt篇
注意事项:
①首先要知道你的文件是什么格式的
在cmd下输入如下命令:
>>>python
>>> f=open('E:作业篇\天龙八部.txt')
>>> f.read()
********************************************************(输出文字)
>>> f
<_io.TextIOWrapper name='E:\\作业篇\\天龙八部.txt' mode='r' encoding='cp936'>
>>>


其中输出的 “cp936” 就是文件编码格式
后来为了好看,把《天龙八部》改成了绕口令23333
②因为要进行排序,所以采用了 python自带的counter计数器
二. doc文档篇
关键是对docx的操作代码
三.pdf篇
①注意在python3环境中应该下载安装pdfminer3k
pip install pdfminer3k
在python2中应该下载安装pdfminer
pip inastall pdfminer
python3 下载 pdfminer 报错信息

其实在报错信息里面我们也可以看出端倪

这里说
print __version__
报错
这很明显是python2的写法,然而我的配置环境为python3 ( 2333333)
attention:
我的代码里用了两次jieba来处理停用词
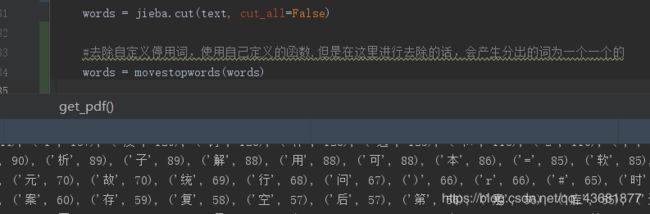
这是使用了两次jieba
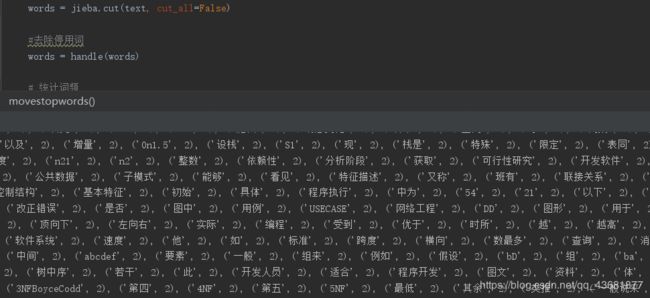
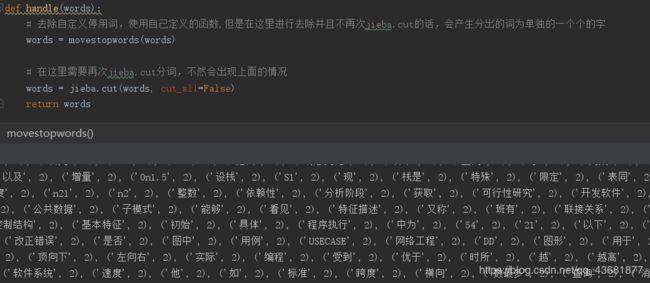
暂时告一段落啦~~~~~