数据结构之链表(C语言版,内含单链表,循环链表,双向链表,双向循环链表详解)
序言:这是我写的第一篇有关于数据结构的文章,案例来源于上课老师布置的一道题,之后也会进行相关的数据结构的简单总结
在介绍链表之前,先大概介绍下函数指针,指针函数,以及结构体,因为后面的代码会涉及到这些
函数指针:函数指针顾名思义就是结合了函数的指针,函数名便是函数地址,但是其还是属于指针,一个指向函数的指针,
其有两种定义方式:
设一函数:
int print_int(int x){
printf("hello%d",x);
return 0;
}
1.typedef int (*F)(int x);
2int (*f1)(int x) = print_int;
指针函数
指针函数则是含有指针的函数,其属于函数,但是与普通函数不同的是其返回值则是指针类型
结构体
结构体定义
typedef struct node{
int data;
struct node *next;
}node,*pnode;
这里就对后面的node,*pnode做一个简单介绍,node相当于该结构体的另一个名字,*pnode则是指向该结构体的指针.。pnode也等于node *p,node *p也是指向该结构体的指针。
然后再对链表做一个简单介绍:链表实际是线性表的链式存储结构,它与数组为代表的顺序表不同,它是一种动态数据结构。链表是一种在存储单元上非连续、非顺序的存储结构,通过指针将各个单元连接在一起。链表的每单个元素被称之为一个节点,没几个节点可以存储在内存的不同位置,一般节点都包含两个部分域——指针域与数据域
下面针对单链表、单向循环链表、双向链表、双向循环链表做一些总结:
一.单链表
原理图:
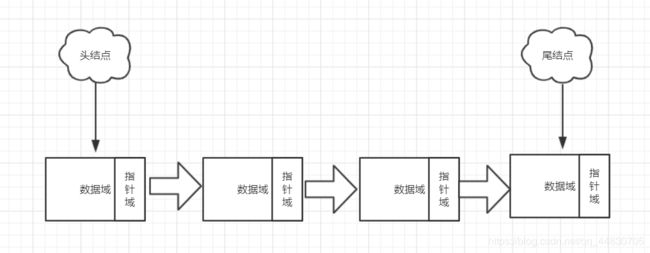
由于链表是由多个节点连接而成,因此在创建链表之前先介绍下如何创建一个节点:
1.创建一个简单的节点
1.定义节点
typedef struct node{
int val;//创建数据域
struct node *next;//创建指针域
} node,*pnode;
2.创建节点
这里的返回值为返回一个节点
node *create_List(){
node *head = (node*)malloc(sizeof(node));
if(head == NULL){
return NULL;
}
//初始化空间
memset(head, 0, sizeof(node));
printf("请输入一个值");
scanf("%d", &head->val);
head->next = NULL;
return head;
}
2.创建链表
在了解了如何创建一个节点后,便可以开始试着去创建链表,创建链表有两种方法,一种是头插法,另一种是尾插法
1.头插法
头插法是一种从头部插入的方法,这里的代码不需要用户输入链表长度,当用户输入数据值为0时,结束插入节点
//头插法创建
node *create_head_list(){
node *h = NULL;
while(1){
node *p = (node *)malloc(sizeof(node));
if(p == NULL){
return h;
}
memset(p, 0, sizeof(node));
printf("请输入值:");
scanf("%d", &p->val);
p->next = NULL;
if(h == NULL){
h = p; //将头结点指针指向该节点
}else{
p ->next = h;
//由于使用的头插法,所以此时该链表的头结点已经不是h,而是p
h = p;
}
if(p->val==0){
break;
}
}
return h;
}
2.尾插法
这里写的函数接口需要用户输入链表长度
//尾插法创建
node *create_tail_list(int size){
node *h = NULL;
for(int i = 0; i < size;i++){
node *p = (node *)malloc(sizeof(node));
if(p == NULL){
return h;
}
memset(p, 0, sizeof(node));
printf("请输入一个值:");
scanf("%d", &p->val);
printf("\n");
p->next = NULL;
if(h == NULL){
h = p;
} else{
//通过h遍历链表,找到链表的尾节点
node *q = h;
while(q->next){
q = q->next;
}
q->next = p;
//p->next = NULL;
}
}
return h;
}
3.插入数据
根据用户输入的插入位置进行插入
//插入数据
void insert_list(node **h, int i){
//创建新节点,并存入数据
node *p = (node *)malloc(sizeof(node));
memset(p, 0, sizeof(node));
printf("输入插入的数据:");
scanf("%d", &p->val);
p->next=NULL;
node *q = *h;
node *x = *h;
int j = 1;
if(*h==NULL){
*h=p;
}else{
if(i==1){
p->next=q;
*h=p;
printf("插入成功\n");
return ;
}
while(q&&i-1>j){
q = q->next;
j++;
}
if(!q||i-1>j){
printf("插入失败\n");
return ;
}else{
p->next=q->next;
q->next=p;
printf("插入成功\n");
return ;
}
}
}
接口中传入的二级指针是因为当插入的数据是头结点位置,会修改指针的值,则需要用到二级指针才可以修改
注:这里的的节点的next域改变一定要清楚,否则很容易插入失败或者插入到其他位置
4.删除数据
这里我写了两种接口:
1.根据用户输入的值进行删除
//根据值删除节点
int delete_list_node(node **h, int value){
if(*h == NULL){
return 0;
}
//获取链表的头结点
node *p = *h;
//定义一个节点用于存储要删除的节点
node *q = NULL;
while(p){
if(p->val == value){
//判断p是否是头结点
if(p == *h){
//这里会改变头结点指针的值,则在传参数时,需要传入二级指针
*h = (*h)->next;
free(p);
}else{//若p不是头结点
q->next = p->next;
free(p);
p=NULL;
}
return 1;
}
q = p;//获取p的前一个节点并赋值为q
p = p->next;
}
return 0;
}
2.根据用户输入的序列号位置进行删除
//根据序列号删除节点
void delete_no_list(node **h, int i){
if(*h==NULL){
return ;
}
node *p = *h;
node *q = NULL;
while(p){
int j = 1;
if(i==1){
*h=p->next;
printf("删除成功\n");
return ;
}
while(p&&i-1>j){
p=p->next;
j++;
}
q=p->next;
p->next=q->next;
printf("删除成功\n");
return ;
}
}
5.遍历链表
//遍历链表
void traverse_list(node *h){
if(h == NULL){
return;
}
node *p = h;
while(p!=NULL){
printf("%d ",p->val);
p = p->next;
}
printf("\n");
}
6.销毁链表
//销毁表
void distory_list(node *h){
if(h==NULL){
return;
}
node *p=h;
while(p){
//需要创建一个临时指针q将当前节点记录下来
node *q = p;
p = p->next;
free(q);
}
}
7.主函数
最后还是把主函数的代码也放上来吧(本来不准备,因为相对比较简单)
int main(){
node *h;
while(1){
int x;
printf("1:创建电话簿\n");
printf("2:插入数据\n");
printf("3:删除数据\n");
printf("4:遍历链表\n");
printf("5:销毁表\n");
printf("请输入操作数字:");
scanf("%d", &x);
switch(x){
case 1:{
int size;
printf("请输入链表长度:");
scanf("%d", &size);
h = create_tail_list(size);
if(h==NULL){
printf("create list failed\n");
return -1;
}
break;
}
case 2:{
int i;
printf("输入插入位置:");
scanf("%d", &i);
insert_list(&h, i);
break;
}
case 3:{
int x;
printf("请输入数字:1.根据对应值删除 2.根据序号删除\n");
scanf("%d", &x);
if(x==1){
printf("请输入删除值:");
int value = 0;
scanf("%d", &value);
if(delete_list_node(&h, value)){
printf("delete Success\n");
}else{
printf("value not found\n");
}
}
if(x==2){
int size;
printf("请输入删除位置:");
scanf("%d", &size);
delete_no_list(&h, size);
}
break;
}
case 4:{
traverse_list(h);
break;
}
case 5:{
distory_list(h);
break;
}
}
}
return 0;
}
二.单向循环链表
原理图:
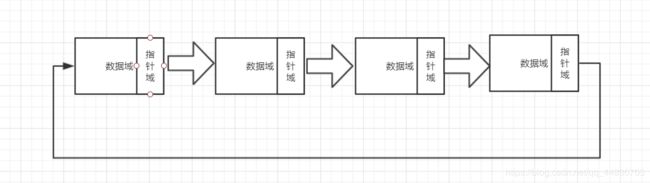
单向循环链表与普通单链表最本质的区别就是单向循环链表的尾结点指向链表的头结点
这里就将单向循环链表的创建,遍历与销毁代码以及判断链表是否为循环链表的代码展示下,插入节点的原理类似于创建该链表的原理,删除节点的原理与删除单链表节点的原理类似。
1.循环链表节点定义
typedef struct node{
int val;
struct node *next;
}node,*pnode;
2.循环链表的创建
node *CreateList(int n)
{
node *p,*q;
node *h;
//先创建一个节点
h=(node *)malloc(sizeof(node));
if(h==NULL)
{
printf("结点申请失败\n");
return h;
}
printf("请输入存储值:");
scanf("%d", &h->val);
h->next=h;//第一个结点
q=h;
for(int i=1;i<n;i++)
{
p=(node *)malloc(sizeof(node));
printf("输入存储值:");
scanf("%d",&p->val);
p->next=h;//创建新节点(作为链表的‘尾结点’),指向头结点,这种方法是通过不断插入的方法来创建一个链表
q->next=p;
q=q->next;
}
return h;
}
3.循环链表的遍历
void traverse_list(node *h){
if(h==NULL){
return;
}
node *p=h;
//头结点需要来判断循环的退出
do{
printf("%d ", p->val);
p=p->next;
}while(p!=h);
//最后剩下一个头结点来最后删除
printf("\n");
}
4.循环链表的销毁
void destory_loop_list(node *h){
if(h==NULL){
return;
}
//从循环链表中的第二个节点开始删除
node *p=h->next;
do{
node *q=p;
p=p->next;
free(q);
}while(p!=h);
free(h);
}
5.判断链表是否为循环链表
bool is_list_loop(node *h){
//判断链表是否为循环链表
node *p=h;
node *q=h->next;
while(p&&q&&q->next&&p!=q){
p=p->next;
q=q->next->next;
}
if(p==q){
printf("该链表为循环链表");
return 1;
}
}
三.双向链表
原理图:
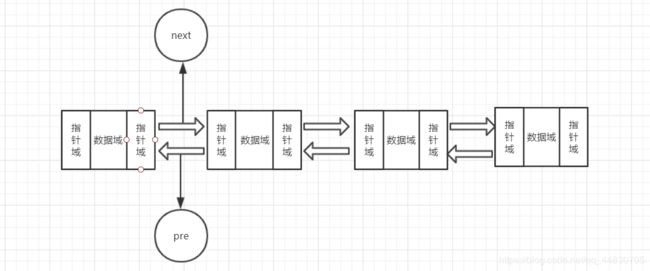
双向链表中每个节点中含有两个指针,一个前驱指针为pre指针,另一个为后去指针为next指针,分别指向前一个节点和后一个节点
1.定义双向链表的节点:
typedef struct node{
int val;
struct node *next;
struct node *pre;
}node,*pnode;
2.创建双向链表
1.从头插法创建
node *create_head_list(int size){
node *h=NULL;
for(int i=0;i<size;i++){
node *p=(node *)malloc(sizeof(node));
if(p==NULL){
printf("内存分配失败");
return h;
}
memset(p, 0, sizeof(node));
printf("请输入存储值:");
scanf("%d", &p->val);
p->next=NULL;
p->pre=NULL;
if(h==NULL){
h=p;
} else{
p->next=h;
h->pre=p;
h=p;
}
}
return h;
}
2.尾插法创建
node *create_tail_list(int size){
node *h=NULL;
for(int i=0;i<size;i++){
node *p=(node *)malloc(sizeof(node));
node *q=h;
if(p==NULL){
printf("内存分配失败");
return h;
}
memset(p, 0, sizeof(node));
printf("请输入存储值:");
scanf("%d", &p->val);
p->next=NULL;
p->pre=NULL;
if(h==NULL){
h=p;
}else{
while(q->next){
q=q->next;
}
q->next=p;
p->pre=q;
}
}
return h;
}
3.遍历双向链表
void traverse_list(node *h){
if(h==NULL){
printf("概念表为空链表");
return ;
}
node *p = h;
while(p){
printf("%d ",p->val);
p=p->next;
}
printf("\n");
}
4.双向链表的节点删除
int delete_list(node **h,int value){
//由于改变了指针的值,这里应该用二级指针
if(*h==NULL){
return 0;
}
node *p=*h;
//判断该节点是否为头结点
if(value==1){
*h=(*h)->next;
(*h)->pre=NULL;
free(p);
return 1;
}
int i=1;
while(value>i){
if(p->next==NULL){
printf("你输入的删除位置非法\n");
return 0;
}
p=p->next;
i++;
}
//判断该节点是否为尾结点
if(p->next==NULL){
p->pre->next=NULL;
free(p);
return 1;
}
p->pre->next=p->next;
p->next->pre=p->pre;
free(p);
return 1;
}
4.销毁双向链表
void destory_list(node *h){
if(h==NULL){
return;
}
node *p=h;
while(p){
node *q=p;
p=p->next;
free(q);
}
printf("链表销毁完成\n");
}
5.main函数代码
int main(){
node *h;
int size;
int i;
printf("请输入创建的链表长度:");
scanf("%d",&size);
h = create_tail_list(size);
traverse_list(h);
while(1){
int x;
printf("请输入删除位置");
scanf("%d",&i);
delete_list(&h, i);
traverse_list(h);
printf("1退出 2继续\n");
scanf("%d",&x);
if(x==1){
break;
}
}
destory_list(h);
return 0;
}
四.双向循环链表
双向循环链表顾名思义就是双向链表的尾结点与头结点相连,因为其原理与之前写的单链表以及单向循环链表原理相似,我这里就不做代码展示。