ELK日志采集实战
ELK日志采集实战
需求背景:
- 业务发展越来越庞大,服务器越来越多
- 各种访问日志、应用日志、错误日志量越来越多,导致运维人员无法很好的去管理日志
- 开发人员排查问题,需要到服务器上查日志,不方便
- 运营人员需要一些数据,需要我们运维到服务器上分析日志,并用图标更直观的展示出来
为什么要用到ELK
- 一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大也就是日志量多而复杂的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
- 大型系统通常都是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
一个完整的集中式日志系统,需要包含以下几个主要特点:
- 收集-能够采集多种来源的日志数据
- 传输-能够稳定的把日志数据传输到中央系统
- 存储-如何存储日志数据
- 分析-可以支持 UI 分析
- 警告-能够提供错误报告,监控机制
而ELK则提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。是目前主流的一种日志系统。
ELK简介
ELK是三个开源软件的缩写,分别为:Elasticsearch 、 Logstash以及Kibana , 它们都是开源软件。不过现在还新增了一个Beats,它是一个轻量级的日志收集处理工具(Agent),Beats占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具,目前由于原本的ELK Stack成员中加入了 Beats 工具所以已改名为Elastic Stack.
Elastic Stack包含:
- Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。详细可参考Elasticsearch权威指南
- Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
- Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
- Beats在这里是一个轻量级日志采集器,其实Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比 Logstash,Beats所占系统的CPU和内存几乎可以忽略不计
需求介绍
我的需求是,需要采集两种日志,一种是正常的系统日志,这个日志异常排查做服务的,还有一种日志是自定义日志结构,这个日志用来统计分析.
解决思路
- 系统部署到docker容器中,通过logback将日志存放到指定目录下,比如说我有十个服务,这时候我需要部署十个docker容器,这十个系统的日志,我都放到同一目录下,再启动docker容器时,我需要将docker容器的 目录和本地机器做目录映射.
- 采集日志我是用FileBeat进行日志采集,但我不打算在每个服务的docker 容器中部署一个filebeat,那我filebeat怎么才能采集到系统日志呢, 我是这样解决的,我部署一个FileBeat的容器,但在启动容器时,我映射上面说的系统目录,这时候所有的日志都会到FileBeat容器内部,这样我只需要部署一台filebeat就可以采集十台服务的日志,这里我没有考虑性能,大家实际情况实际分析.
- 上面说过,我有两种日志结构,我用filebeat采集日志,在Logstash中通过判断,将两种不同的日志,存到不同的index 中就可以了.下面开始实际操作.
搭建ELK环境
在这里我们使用docker来部署ElK,我们使用docker hub 上的镜像来进行搭建.
镜像介绍
我们这里使用docker hub 上的sebp/elk镜像,网站为https://hub.docker.com/r/sebp/elk.下面我针对该镜像开始介绍搭建.我们以670为例.
拉取镜像
在你的系统中运行 docker pull sebp/elk:670
创建容器
docker run -p 5601:5601 -p 9200:9200 -p 5044:5044 -p 9300:9300 -p 9201:9201 -v /home/ubuntu/iri/chenzhe/logstash/config:/etc/logstash/conf.d/ -v /home/ubuntu/iri/chenzhe/elasticsearch/elasticsearch.yml:/etc/elasticsearch/elasticsearch.yml -it --name elk --restart=always sebp/elk:670
命令介绍
上面了命令我们做了端口映射,和文件映射,
端口介绍
- 5601 (Kibana web interface).
- 9200 (Elasticsearch JSON interface).
- 5044 Logstash input 开放端口
- 9300 因为我的程序需要使用Java代码操作ES 9300 是ES的内部通讯端口
- 9201 是我通过logback 往ES里存储Sleuth的端口
目录映射介绍
做目录映射的目的是为了方便我们操作容器内部的配置文件,防止因为直接修改容器内的配置文件,出错后容器跑不起来,我们还改不了配置文件,只能重新搭建.
- /etc/logstash/conf.d/ 是LogStash的 input 和 output 配置文件
- etc/elasticsearch/elasticsearch.yml 是ES的配置文件目录,它和我们正常下载的ES的配置文件所在地址不太一样,在elasticsearch目录下也有一个elasticsearch.yml 但是你改这个不生效
常见问题
容器创建后会默认启动全部程序,你可能遇到一些错误
- 你可能会遇到ElasticSearch 报出 用户执行内存权限不够的情况你需要在 /etc/sysctl.conf 下 添加 vm.max_map_count=300000
- ES默认不能使用root用户操作,你需要使用其他用户
总结
当你完成上面的步骤之后到这里你的ELK环境已经搭建完成,下面我们针对我遇到的实际需求来讲解我的实现过程.
部署服务应用
配置项目的logback
-
可以看到我们将日志文件全部输出到了/opt/logs/tdf-cloud/zipkin/zipkin.log下
-
CONSOLE_LOG_PATTERN 是日志采集的正则表达式符合规则的日志才进行采集
-
这个日志配置你可以在Spirng Cloud Sleuth 官网中看到
https://cloud.spring.io/spring-cloud-static/spring-cloud-sleuth/2.2.0.M1/
-
这个配置文件你必须在你每个项目下都配置一个,你可以根据不同的项目将日志输出到不同的目录下.
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<property resource="bootstrap.yml" />
<springProperty scope="context" name="springAppName" source="spring.application.name"/>
<property name="LOG_FILE" value="/opt/logs/tdf-cloud/zipkin/zipkin.log"/>
<property name="CONSOLE_LOG_PATTERN"
value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>DEBUGlevel>
filter>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}pattern>
<charset>utf8charset>
encoder>
appender>
<appender name="flatfile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.%d{yyyy-MM-dd}.gzfileNamePattern>
<maxHistory>7maxHistory>
rollingPolicy>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}pattern>
<charset>utf8charset>
encoder>
appender>
<root level="INFO">
<appender-ref ref="console"/>
<appender-ref ref="flatfile"/>
root>
configuration>
部署docker容器
docker run
-p 8770:8770
-e “SPRING_PROFILES_ACTIVE=test”
–name tdf-cloud-zipkin
–restart=always
-e “eureka.instance.hostname=192.168.70.40”
-e “spring.cloud.client.hostname=192.168.70.40”
-v /opt/logs/tdf-cloud:/opt/logs/tdf-cloud \
命令介绍
我们这里动态传入了,注册中心地址和服务器地址. 同时做了目录映射.做目录映射的目的是将容器内的日志,映射到服务器中.
遇到的问题
在日志输出到文件后,我进行了查看,发现乱码,里面有大量的ESC字样,查找问题发现,是因为SpringBoot的彩色日志导致的.通过spring.output.ansi.enabled=NEVER 可以解决这个问题.
搭建FileBeat环境
因为我们需要通过FileBeat采集日志,后将日志输出到LogStash.再有LogStash存到ES中
官网
https://www.elastic.co/guide/en/beats/filebeat/6.7/index.html
部署FileBeat
这里我们使用docker-compose进行部署
docker-compose.yml
version: '3'
services:
filebeat:
image: docker.elastic.co/beats/filebeat:6.7.0
restart: always
user: root
volumes:
- /opt/logs/tdf-cloud:/opt/logs/tdf-cloud
- /home/ubuntu/iri/chenzhe/filebeat/config/filebeat.yml
:/usr/share/filebeat/filebeat.yml
命令介绍
我们这里将容器下的/opt/logs/tdf-cloud和Ubuntu上的/opt/logs/tdf-cloud做了目录映射.注意在Ubuntu下的opt/logs/tdf-cloud因为已经和部署服务的容器做了目录映射,里面已经有日志文件了.我再将Ubuntu的目录和filebeat容器做目录映射,所有的日志文件都会到filebeat容器中.
filebeat日志采集配置文件
filebeat采集自己容器下的目录,/opt/logs/tdf-cloud/因为做了目录映射这时候已经全是日志了.
filebeat.inputs:
- type: log
enabled: true
paths:
- /opt/logs/tdf-cloud/*/*/*.log
output.logstash:
hosts: ["192.168.70.40:5044"]
总结
fileBeat已经采集到了两种结构不同的日志,全部输出到了LogStash中我们需要在LogStash中区分两种日志,并存储到ES不同的索引中.
配置LogStash
官网
https://www.elastic.co/guide/en/logstash/6.7/index.html
日志例子
日志一
2019-07-26 01:44:24.602 INFO [tdf-cloud-gateway,085bc5cef3a9ec0a,085bc5cef3a9ec0a,true] 1 — [or-http-epoll-9] c.c.t.gateway.filter.LocalLimiterFilter : 10.0.52.92 admin tdf-service-sys 2019-07-26T01:44:24.557Z 2019-07-26T01:44:24.602Z true
对应grok正则
"%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}]\s+%{DATA:pid}\s±–\s+[%{DATA:thread}]\s+%{DATA:class}\s+:\s+%{IP:ip}\s+%{USERNAME:usernmae}\s+%{NOTSPACE:appname}\s+%{TIMESTAMP_ISO8601:requesttime}\s+%{TIMESTAMP_ISO8601:reponsetime}\s+%{NOTSPACE:success}
日志二
2019-07-26 01:46:55.618 INFO [tdf-cloud-gateway,1bb08e068c422a72,1bb08e068c422a72,false] 1 — [r-http-epoll-66] c.c.t.gateway.filter.LocalLimiterFilter : /assets/js/sba-core.ad0df74c.js:------------: 13ms
对应grok正则
%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}]\s+%{DATA:pid}\s±–\s+[%{DATA:thread}]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}
常用正则表达式
https://github.com/elastic/logstash/blob/v1.4.2/patterns/grok-patterns
grok调式
可以用Kibana里的Dev Tools 里面有Grok Debugger. 建议在里面调试好,调试正则没有太好的方法,就把那里面的正则表达式全都试一下,看那个能解析出来就可以了.
配置LogStash
配置input
input {
beats {
port => 5044
type => syslog
}
}
filter {
grok {
match => [
"message","%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{IP:ip}\s+%{USERNAME:usernmae}\s+%{NOTSPACE:appname}\s+%{TIMESTAMP_ISO8601:requesttime}\s+%{TIMESTAMP_ISO8601:reponsetime}\s+%{NOTSPACE:success}",
"message", "%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}"
]
}
}
配置output
output {
if[type]=="sleuth"{
elasticsearch {
hosts => ["localhost"]
manage_template => false
index => "sleuth-%{+YYYY.MM.dd}"
document_type => "sleuth"
}
}
if [type]=="syslog" and [success]=="true" or [success]=="false" {
elasticsearch {
hosts => ["localhost"]
index => "gatewaylog-%{+YYYY.MM.dd}"
document_type => "gatewaylog"
template => "/etc/logstash/gatewaylog.json"
template_name => "gatewaylog"
template_overwrite => true
}
}
if [type]=="syslog" and ![requesttime]{
elasticsearch {
hosts => ["localhost"]
manage_template => false
index => "syslog-%{+YYYY.MM.dd}"
document_type => "syslog"
}
}
}
input配置解释
可以看到我给了它一个类型同时,我创建了一个过滤器,使用grok 配置了日志格式的正则表达;符合规则的日志会被解析成JSON,最后存到ES中
output配置解释
在第一个if中我根据类型判断将数据存到那个index中,第二个和第三个if是因为他们的类型都是syslog但是里面的字段是不一样的,这个时候我根据字段进行了判断,应该把数据放到那个index里面,template是自己定义的模板,因为有的字段在ES中不建立索引,所以我自己建立了一个模板,这样ES就会将我的字段建立索引,完了我就可以使用Kibana进行字段过滤.
模板配置
{
"template":"gatewaylog-*",
"order":1,
"settings":{
"number_of_shards":5,
"number_of_replicas":0
},
"mappings":{
"_default_":{
"_all":{
"enabled":true,
"omit_norms":true
},
"dynamic_templates":[
{
"message_field":{
"match":"message",
"match_mapping_type":"string",
"mapping":{
"type":"string",
"index":"analyzed",
"search_analyzer":"ik_max_word",
"analyzer":"ik_max_word",
"omit_norms":true,
"fielddata":{
"format":"disabled"
}
}
}
},
{
"string_fields":{
"match":"*",
"match_mapping_type":"string",
"mapping":{
"type":"string",
"index":"not_analyzed",
"doc_values":true
}
}
}
],
"properties":{
"@timestamp":{
"type":"date"
},
"@version":{
"type":"string",
"index":"not_analyzed"
}
},
"dynamic_date_formats":[
"yyyy-MM-dd HH:mm:ss.SSS"
]
}
}
}
配置ElasticSearch
官网
https://www.elastic.co/guide/en/elasticsearch/reference/6.7/index.html
遇到的问题
-
因为ES部署在docker容器中,在我使用java 操作ES的时候,始终获取不到连接,所以我在elasticsearch.yml中配置了network.publish_host: 192.168.70.40 192.168.70.40 是Ubuntu的地址,这样你的服务器就相当于一个代理,就可以通过服务器连接到ES.
-
ES默认只支持localhost访问,其他机器想访问需要配置network.host: 0.0.0.0 我这里配置的是允许所有访问.
-
ES Head插件不能连接,出现跨域问题 http.cors.enabled: true http.cors.allow-origin: “*” 配置这两项就可以了,
总结
上面都完成后,数据已经到ES中了,接下来可以通过Kibana进行查看了.
Kibana使用
官网
https://www.elastic.co/guide/en/kibana/6.7/index.html
访问kibana
服务器ip:5601 ,访问之后你会看到一个default的工作空间.我们先进去
创建工作空间
点击左下角的Default,选择Manage Space .再点击Creeat Space ,为你的空间起个名字,创建后,再点击左下角的Default你会看到你刚刚创建的空间,完了你会看到Try our sample data 这个是Kibana提供的demo ,我们选择用自己的,
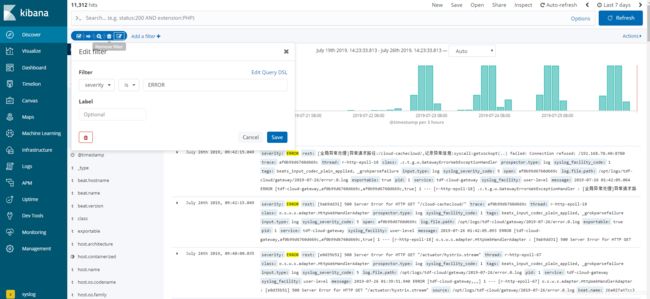
查询数据
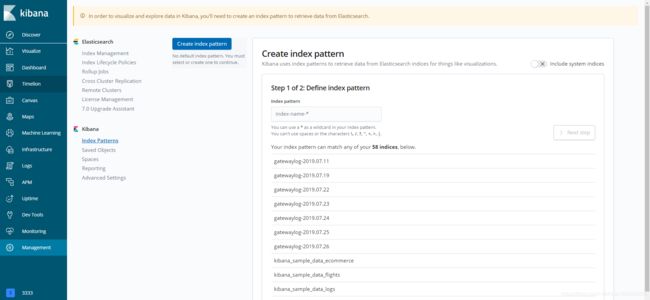
进入空间后我们我们选择Discover这个时候,我们可以看到Create index pattern这时候你要填写的是索引名,这个索引名它是支持正则的比如说我现在有gatewaylog-2019.07.11 gatewaylog-2019.07.19 我现在填写gatewaylog-* 是都可以查询出来了
数据过滤
我们在点击Discover,我们这时可以看到数据,那怎么可以看到你想看的数据.举个例子,我现在的数据是系统日志数据,我现在想看Error级别的日志,这是后点击 Add a filter 我们日志级别的字段是 severity .我们输入字段 选择is value 输入 ERROR .就能查出所有的错误日志