信息量、熵和交叉熵
信息量、熵和交叉熵
- 信息量:
- 熵
- 交叉熵
- 交叉熵和均方误差的区别
- tf.nn.softmax_cross_entropy_with_logits实现交叉熵和损失的计算
总结
- 信息量利用概率倒数的对数对事件的稀缺性进行衡量
- 熵是一个随机系统信息量的期望
- 交叉熵用于衡量两个概率分布之间的差异
信息量:
信息量是对事件发生概率的度量,一个事件发生的概率越低,则这个事件包含的信息量越大,这跟我们直观上的认知也是吻合的,越稀奇新闻包含的信息量越大,因为这种新闻出现的概率低。香农提出了一个定量衡量信息量的公式:
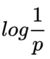
熵
熵是一种对不确定性的方法,对于存在不确定性的系统,熵越大表示该系统的不确定性越大,熵为0表示没有任何不确定性。熵的定义如下:
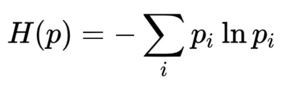
从这个公式可以看出,熵其实就是随机系统各个事件的香农信息量的期望,或者叫均值。如果这个随机系统只包含两种可能,如抛硬币的结果,正面概率为p,反面结果为1-p,那么这个系统的熵就是:
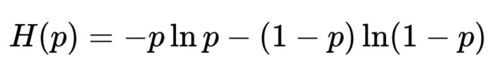
当随机系统中各个事件概率相等的时候,系统的熵最大,也就是不确定性最大,而随着某个事件的概率逐渐增大,对立事件概率越来越小,这种情况下系统的不确定性越来越小,最终趋向于0,也就是成为一个没有随机因素的系统。这个结论可以通过对熵计算极值的方法求证,对上面熵的公式进行求导,使其导数为0:
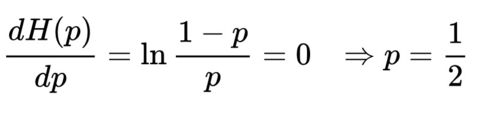
可以看出,当p=1/2的时候熵取最大值,也就是系统不确定性最大。
上面给出的计算是基于抛硬币系统进行的,这个系统只有正面或反面两种事件,推广到包含多个事件的随机系统结论也是成立的。也就是说,对于包含N个事件的随机系统,在没有任何先验知识的前提下,当这N个事件等概率的时候,系统熵最大,最混乱。
在统计学习方法中,有个最大熵模型,最大熵模型认为使得一个随机系统的熵最大(最混乱)的模型是最好的模型,这是最大熵模型的大前提。主观上理解,在没有任何先验知识的情况下,假设各个事件是等概率的,这是合理的。在这个前提或者叫准则下,最大熵模型的任务就是使得随机系统在满足约束条件的前提下,达到最大的熵。
最大熵模型的计算分三种情况:
-
不存在任何约束
这种情况下只有一个隐形的等式约束,就是各个事件概率之和为1。直接令熵的导数=0求解即可,结论上面已经给出,当N个事件等概率的时候熵最大,可以通过拉格朗日乘子法进行证明 -
只存在等式约束
这时同样需要使用拉格朗日函乘子将约束条件加入到目标函数中进行求解。下面给出一个使用拉格朗日乘子求解带等式约束的最大化问题:

-
存在不等式约束
存在不等式约束的最优化问题求解同样使用拉格朗日算子进行计算,使目标函数满足KKT条件,进行求解,此处不再推导。
交叉熵
交叉熵用来衡量预测概率分布和真实概率分布之间差异的度量,计算公式如下,其中Pi是真实分布,Qi是预测分布:
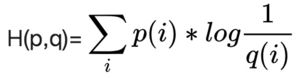
预测分布越接近真实的分布,交叉熵越小,当预测分布等于真实分布时,交叉熵最小,此时交叉熵的值等同于熵。所以,交叉熵提供了一种衡量两个分布之间差异大小的方式,常用来作为神经网络的损失函数。当神经网络的预测分布跟真实分布(人工标注结果)相差很大时,交叉熵就大;当神经网络随着训练的进行预测分布越来越接近真实分布时,交叉熵就逐渐减小。
交叉熵和均方误差的区别
交叉熵和均方误差都可以作为神经网络的损失函数,他们的区别在于:
- 交叉熵适用于分类问题,结果是离散的类别(如图片分类),而均方误差适用于回归问题,结果是一个连续的数值(如雨量预测)【实际上均方误差也可以用于分类问题】
- 在使用sigmod激活函数时,如果使用均方误差作为损失函数,反向传播的导数(直接影响学习速度)会包含sigmod函数的梯度,这个梯度随着变量的增大会趋向于0,导致学习速度迅速降低;而如果使用交叉熵作为损失函数,就不存在这个问题,反向传播的导数包含sigmod函数,而不包含sigmod函数的导数。
tf.nn.softmax_cross_entropy_with_logits实现交叉熵和损失的计算
import tensorflow as tf
logits = tf.constant([[1.0, 2.0, 3.0], [1.0, 2.0, 3.0], [1.0, 2.0, 3.0]])
y_ = tf.constant([[0.0, 0.0, 1.0], [0.0, 0.0, 1.0], [0.0, 0.0, 1.0]])
# softmax_cross_entropy_with_logits计算后,矩阵的每一行数据计算出一个交叉熵,三行数据共计算出三个交叉熵
cross_entropy_lst = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y_)
# 通过reduce_sum进行累加,计算出一个batch的交叉熵
cross_entropy = tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y_))
# 将batch里每条记录的交叉熵求均值,作为损失
cross_entropy_loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y_))
# 手动分解上面的计算,过程如下
logits_softmax = tf.nn.softmax(logits)
cross_entropy_2 = -tf.reduce_sum(y_ * tf.log(logits_softmax)) # batch所有数据求和
cross_entropy_lst_2 = -tf.reduce_sum(y_ * tf.log(logits_softmax), 1) # batch每行数据求和
cross_entropy_2_loss = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(logits_softmax), 1)) # batch每行数据求和后,再求均值
with tf.Session() as sess:
print sess.run(cross_entropy_lst)
print sess.run(cross_entropy)
print sess.run(cross_entropy_loss)
print sess.run(cross_entropy_lst_2)
print sess.run(cross_entropy_2)
print sess.run(cross_entropy_2_loss)
输出:
[ 0.40760595 0.40760595 0.40760595]
1.22282
0.407606
[ 0.40760601 0.40760601 0.40760598]
1.22282
0.407606