Kylin在用户行为轨迹分析中的应用实践与优化

大数据技术与架构
点击右侧关注,大数据开发领域最强公众号!


暴走大数据
点击右侧关注,暴走大数据!

作者:季杰
一、kylin简介
2015年12月8日,Apache Kylin 从 Apache 孵化器项目毕业,正式升级为顶级项目,也是第一个由中国团队完整贡献到 Apache 的顶级项目。kylin的诞生,为大数据高效的olap查询提供解决方案,主要由以下特点:
高并发低延迟,实现大数据集亚秒级查询
多维度,多指标,任意组合的聚合查询,支持星形模型、雪花模型
指标中包含大量需要去重的指标,且要求结果精确
支持流式cube计算和离线T+1cube计算
提供标准sql通过odbc、jdbc或restful api进行查询
二、kylin在同程艺龙实践
2016年11月,数据中心引入kylin,作为olap主要引擎之一。2017年升级kylin到2.0.0版本,2019年升级kylin到2.6.4版本。支撑数仓、酒店等业务,近100个cube,共7TB的数据量。采用2台query端,2台job端,单独的hbase集群进行部署,保证集群高可用,高稳定性和高并发能力。打通openldap,结合权限管理平台进行权限管理。
三、轨迹模型打样
轨迹模型采用雪花模型构建,1张事实表,10张维度表,共25个维度,每天亿级别的pv,千万级别的uv。
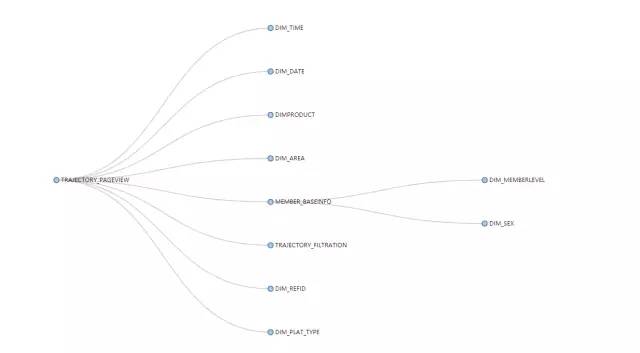
按月对轨迹模型根据不同维度进行并发查询pv和uv,其性能都有不错的体现。
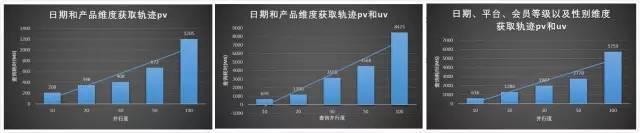
对于像轨迹这种维度超过15个的超大模型,我们就需要对模型进行深度优化,否则我们在模型构建过程以及查询过程都无法达到我们预期效果,下面,将以轨迹模型作为打样,系统讲解整个kylin建模以及查询的优化过程。
四、模型优化
对于复杂的模型,我们该如何构建出一个优秀的模型呢?下面,我们将从以下几个方面进行逐个讲解。
模型设计阶段优化
cube降维优化
hbase rowkey优化
build参数优化
关闭查询压缩
1、模型设计阶段优化
我们在构建模型的时候可以分为增量和全量模型,在增量模型能够满足我们的需求的时候,坚决不使用全量模型,因为每天只build当天增量的数据总比每天build全量历史数据来的轻松,高效。对于历史数据不会变更,数据按照T+1的模式进行增量添加的时候,那就完全符合增量模型构建。构建增量模型,首先hive表中必须存在一个日期的分区键或者列,且日期格式只能如下:yyyy-MM-dd、yyyyMMdd和yyyy-MM-dd HH:mm:ss三种。在轨迹模型构建中,我们可以将事实表中的DATE字段声明为分区列,并选择日期格式为:yyyyMMdd。
如果模型中存在count(dinstict)类型的查询指标,而且查询存在跨天统计,那么我们就需要将该指标设置为全局字典来达到我们的要求。在轨迹模型中,我们需要统计uv,因此需要将用户id声明为全局字典。
至此,我们就完成了一个增量模型的构建。
2、cube降维优化
再讲降维之前,首先我们需要了解cuboid的概念。例如我们轨迹模型有4个维度A、B、C、D,我们需要对这四个维度求pv,由于为了满足所有场景的聚合查询,我们需要对所有维度进行排列组合进行计算出pv结果,转换成kv对,存储到hbase中。而每种维度组合就对应一个cuboid,因此4个维度,共有16个cuboid,如下图所示。
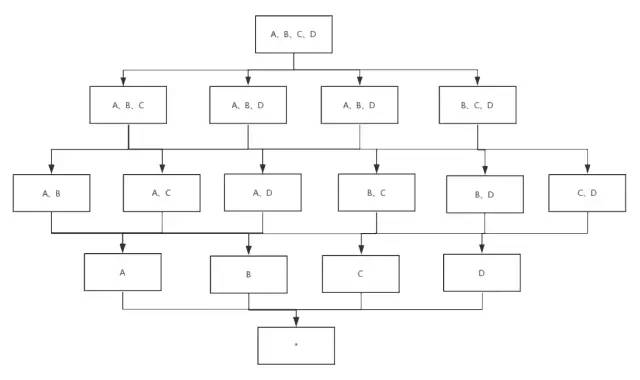
而查询则根据查询条件命中的维度数,找到对应的cuboid,然后将cuboid中对应hbase中的行,scan到kylin的内存,计算出结果进行返回。那我们为什么需要进行降维优化,因为如果不进行任何维度优化,直接将所有的维度放在一个聚集组里,Kylin就会计算所有的维度组合。例如,有15个维度,Kylin就会计算2的15次方即32768个cuboid,实际上查询可能用到的cuboid不到1000个,甚至更少。如果对维度不进行优化,当维度超出15个的时候,我们在保存模型则会出现如下异常。

当然,我们可以通过修改参数kylin.cube.aggrgroup.max-combination来扩大单个聚合组的最大cuboid个数限制,但是不推荐这么做。这样会造成集群计算和存储资源的极大浪费,也会影响cube的构建时间和查询性能,导致模型膨胀率变高,所以我们需要进行cube的降维优化。降维优化我们可以从以下几个方面进行着手:
衍生维度优化
衍生维度是不参与cuboid计算的,衍生维度只能存在维度表中,而在查询过程中,会将衍生维度对应到维度表的外键,匹配cuboid,scan出结果,然后将结果与维度表关联,将衍生维度的值补全。因此基本上所有的维度表非外键的维度均可以作为衍生维度存在,当然这个过程会损耗一定的查询性能,如果维度表较小、查询结果集也较小,性能损失可忽略不计,但对构建性能的提升是显著的。因此我们可以将DIM_TIME、DIM_DATE、TRAJECTORY_FILTRATION和DIM_PLAT_TYPE,四张维度表中共8个维度均声明为衍生维度。其优化力度为:维度N个衍生维度组合,cuboid个数会从2的N次方降低为2。
Extended Column维度优化
在OLAP分析场景中,经常存在对某个id进行过滤,但查询结果要展示往往需要展示name的详情,比如user_id和user_name。那user_name是符合衍生维度优化的,但是此时user_name为事实表的字段,那我们可以采用Extended Column维度优化,来达到类似衍生维度优化效果。当然轨迹模型中并不存在该维度的优化。其优化力度等同于衍生维度:事实表的N个Extended Column维度组合成,cuboid个数会从2的N次方降为2。
必要维度优化
对于一些模型某些维度都必须存在的,例如轨迹模型的日期字段,一直会作为where条件作为时间范围限定,那么这个维度就可以声明为必要维度,只有包含此维度的Cuboid会被生成。优化力度:事实表的N个必要维度组合成,cuboid个数会从2的N次方降为2。我们不难发现,不管是衍生维度、Extended Column维度还是必要维度优化,有N个这样的维度,最终优化效果都是将2的N次方个cuboid减少为2。如下图,总共A、B、C、D四个维度,如果维度A被声明为必要维度,那么不包含这个维度的所有cuboid就不会被构建。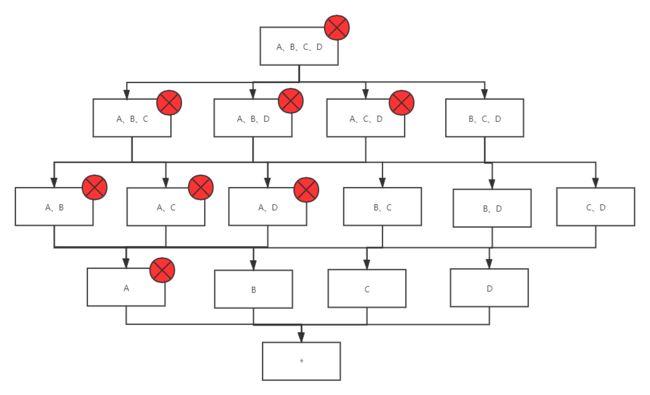
层次维度
例如轨迹模型会根据地域来统计pv和uv。而地域国家、省份、城市这些维度是有层级关系的,只会出现如下四种查询情况:
[COUNTRYNAME、PROVINCENAME、CITYNAME]
[COUNTRYNAME、PROVINCENAME]
[COUNTRYNAME]
[]
因此就可以将这些维度声明为层级维度进行优化。优化效果:N个层级维度组合,cuboid个数会从2的N次方减少到N+1。如下图所示,我们将A、B、C这三个维度声明为层级维度,其参与cuboid计算的个数将降低为8个。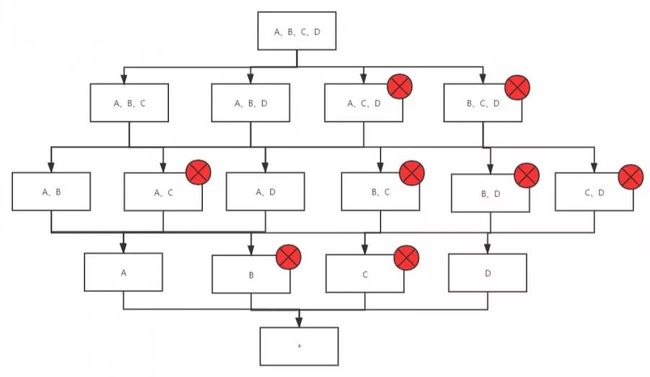
联合维度
例如轨迹模型中经常会根据渠道统计pv、uv,而渠道有一级渠道、二级渠道、三级渠道,查询过程中要么同时出现,要么同时不出现,因此可以将这类维度声明为联合维度。其优化效果:将N个维度组合成的联合维度,cuboid个数从2的N次方减少到2。如下图,我们将A、B、C这三个维度声明为联合维度,那么最后保留的cuboid个数将降低为4个。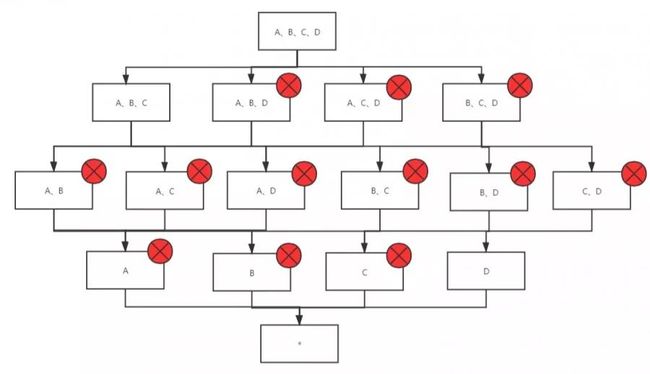
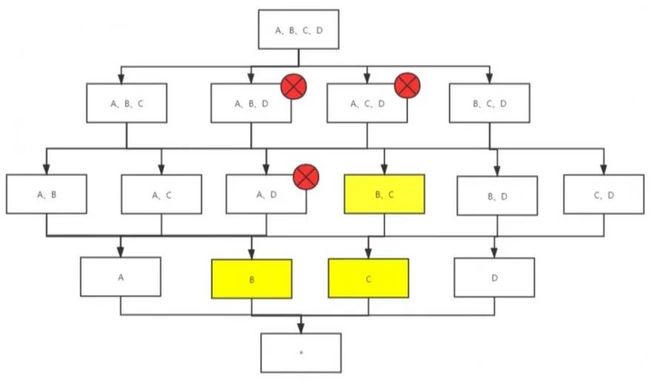
聚集组
当模型查询场景可以分为两类或者多类的时候,即每类查询使用的维度不重合或重合较少,且维度较多,那么就可以使用聚合组优化降维,聚合组不宜太多,建议不超过3个。例如一类查询只会命中A、B、C三个维度,另一来查询只会命中B、C、D三个维度,那们我们可以将A、B、C声明为一个聚合组,B、C、D声明为另一个聚合组,这样每个聚合组会生成自己的cuboid,而交叉的cuboid,包含[B、C]、[B]、[C],只会生成1次,具体如下图所示。
3、hbase rowkey优化
kylin会对字符串数据进行字典树编码,转换成数值类型数据,避免存储大量超长的字符串造成存储空间浪费和查询性能损耗。同时rowkey会按照事先设置的维度顺序将所有的维度值进行编码生成hbase的rowkey。因此,对数值类型可以省去字典树编码的步骤,这样可以在构建cube过程中减少计算,减少存储。因此标明每个字段的类型和长度是有必要的,rowkey编码类型有:Boolean、Date、Dict、Integer、Time、Fixed_length、Fixed_length_hex。我们需要根据字段类型选择正确的rowkey编码类型和编码长度,编码长度和java的基础类型对应占用的字节数一致。
java字段类型 |
占用字节数 |
byte |
1 |
short |
2 |
integer |
4 |
bigint |
8 |
同时hbase rowkey顺序设置也很重要,将mandatory维度放置rowkey的最前面, 将常用作过滤条件的维度优先放置再前面,且基数越大越先。这样查询可以优先过滤掉不必要的数据,最大可能减少hbase scan的行数,极大优化查询效率。假设我们维度有A、B、C,其中A为日期,我们需要统计2019-12-01到2020-01-01期间轨迹的pv和uv,rowkey设置顺序不同,扫描hbase数据范围会有很大的差距:
序号 |
rowkey顺序 |
hbase rowkey开始 |
hbase rowkey结束 |
扫描数据有效性 |
1 |
A、B、C |
'2019-12-01',min(B),min(C) |
'2020-01-01',max(B),max(C) |
扫描数据最少,只扫描日期限定范围内的数据,且全部数据有效 |
2 |
B、A、C |
min(B),'2019-12-01',min(C) |
max(B),'2020-01-01',max(C) |
当B值不等于最小值的时候,将会对日期限定范围外的数据也进行扫描 |
3 |
B、C、A |
min(B),min(C),'2019-12-01' |
max(B), max(C), '2020-01-01' |
当B值和C值不同时为最小值的时候,将会对日期限定范围外的数据进行扫描,扫描无效数据量最大 |
最终优化如下图所示,我们将必要维度DATE放置在rowkey的最前面,而常做过滤条件的维度产品名称,平台类型、时间维度、渠道等条件依次排序放置到必要维度的后面,并对一些integer类型的字段选择integer编码,并设置长度为4个字节。
4、build参数优化
高基数维度优化
对于高基数维度首先考虑从业务层面进行优化,从根源上避免高基数维度的产生,高基数维度对整个模型的膨胀率贡献是很大的,也极大影响查询性能,因此在模型构建中能够避免则避免。轨迹模型中采用雪花模型,其中会员id就是高基数维度,事实表通过会员id与会员基本信息表关联,然后会员信息表又和会员等级以及会员性别两张维度表进行关联,而我们关心的维度是会员性别和会员等级信息,因此可以将会员性别和会员等级信息声明为普通维度而不是衍生维度,从而将会员id剔除,不参与维度建模,避免高基数维度产生。而用户id也是一个高基数指标,用于统计uv。对于这种无法避免的高基数维度和指标,我们该如何优化呢?
由于kylin通过mapreduce进行此步骤,在reduce端,一个维度用一个reduce去重,因此当某个维度的基数很大时,数据倾斜产生了,甚至内存溢出,为了应对这种场景我们可以进行高基数维度优化。
要开启高基数维度优化,首先模型构建中必须满足如下条件的任一一个条件:
1. 对于指标,运用于去重方面,则需要将该指标设置成全局字典。
2. 对于维度,则需要将该维度设置成shard by类型,在hbase rowkey构建时进行设置。
满足上述条件后,则可以在Extract Fact Table Distinct Columns步骤对高基数维度进行优化,通过设置如下参数进行优化:

然后再构建字典过程中,我们可以额外开启一个mapreduce任务对高基数维度字典进行单独build操作,开启该步骤需要设置如下配置:

mapreduce任务优化
cube的build过程就是通过hive任务将事实表和维度表关联,打宽成一张大宽表,然后基于大宽表中间通过多个mapreduce任务或者是spark任务将大宽表数据根据维度和指标,计算成kv对的形式存储到hbase中,因此在build过程中相关的hive、mapreduce以及spark相关优化参数都是可以使用的。
其中hive阶段,设置hive参数需要在参数前设置前缀
![]()
Mapreduce阶段同样也需要设置如下前缀:
![]()
Spark阶段使用如下前缀:
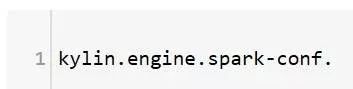
在轨迹模型构建过程中,由于会员id的基数较大,在抽取维度基数的过程中如果没有足够的内存,容易出现oom的情况,因此调整了mapreduce任务内存相关优化参数。
最终优化如下:
1 kylin.engine.mr.config-override.mapreduce.reduce.memory.mb=7168
2 kylin.engine.mr.config-override.mapreduce.reduce.java.opts=-Xmx6g
3 kylin.engine.mr.config-override.mapreduce.map.memory.mb=7168
4 kylin.engine.mr.config-override.mapreduce.map.java.opts=-Xmx6g
5 kylin.engine.mr.build-uhc-dict-in-additional-step=true
6 kylin.engine.mr.uhc-reducer-count=5
5、关闭查询压缩
在轨迹模型构建成功以后,在hbase集群压力大的时候进行查询,根据产品名称和日期两个维度查询半个月的pv和uv的时候,查询耗时在15s左右,首先怀疑是查询命中的cuboid不是最佳的cuboid,通过排查,发现kylin2.6.0开始,开启参数
![]()
则会进行减枝优化,从而导致查询命中的不是最佳的cuboid。通过cube planner可以根据历史查询推荐最优的的模型设置,可以点击推荐按钮,进行优化。
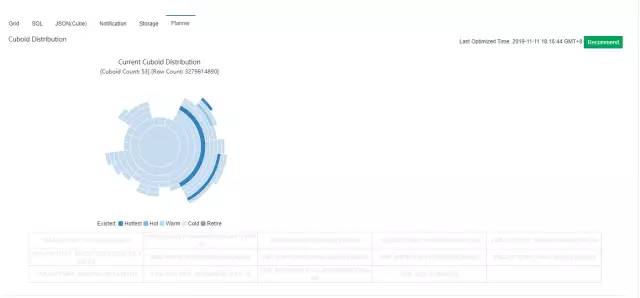
当命中最优的cuboid的查询,其查询耗时并没有明显提升,通过查看日志:
1. 2019-11-11 13:51:16,712 INFO[kylin-coproc--pool7-t5] v2.CubeHBaseEndpointRPC:344 :
2. 2019-11-11 13:51:19,114 DEBUG[kylin-coproc--pool7-t5] util.CompressionUtils : 71:Original : 121086540 bytes.Decompressed: 167658342 bytes. Time: 2402
发现这两行日志相关的数值可能是查询的耗时,通过查看源码,印证了该想法,该日志显示的内容主要分为以下几个流程,我们只关心@后面的数据,表示从启动到当前步骤的耗时,单位毫秒。

整个过程主要耗时在对聚合数据压缩上,耗时10s左右,继续跟踪源码:
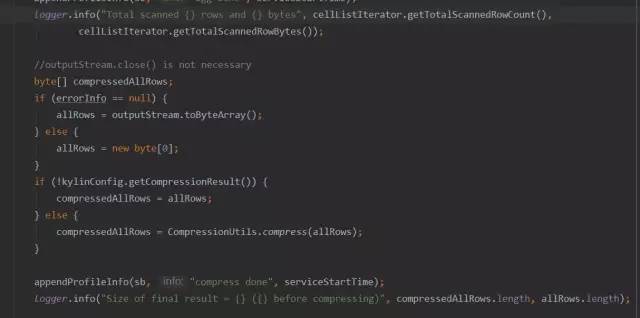
是否开启压缩主要通过参数kylin.storage.hbase.endpoint-compress-result进行控制,该参数默认为true,则进入compress方法,compress方法查看源码如下:
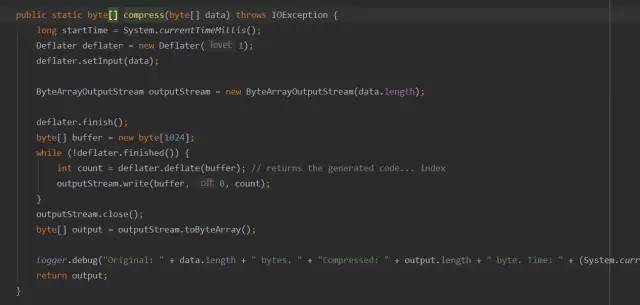
kylin对数据压缩和解压采用的是jdk自带的Deflater压缩和Inflater解压工具,其优势就是使用方便,可以序列化所有的类,但是缺点却很明显,速度慢,占空间,167658342 bytes的数据压缩后为121086540 bytes,压缩率只有72%左右。而且解压耗费了2s左右。通过整体分析,整个查询耗时15s,主要花费在压缩和解压缩上。
通过调整参数kylin.storage.hbase.endpoint-compress-result=false,我们可以关闭压缩和解压缩的操作。调整后日志如下:
2019-11-11 20:56:11,382 INFO [kylin-coproc--pool5-t1] v2.CubeHBaseEndpointRPC:344 :
整个压缩和解压缩的耗时都省去了,查询耗时也从15s降低到了几百毫秒。
五、后续规划
目前kylin建模流程、优化流程是比较繁琐的,只有对kylin有较深的了解才能创建出比较优秀的模型。针对使用难度痛点,目前正在开发kylin自动化建模接口,主要支持两个场景建模。
场景一:
业务知道模型关系,但是对指标、维度不能精准掌控的时候,业务只需要通过输入模型事实表,我们可以根据业务在presto、hive、sparksql、greenplum等组件,历史查询该表的情况,解析所有的sql字段,找出维度、指标、表的关联关系以及维度最佳组合来提供业务进行修改。如果业务清楚了解维度、指标可以基于该基础进行深度优化。最终调用kylin自动化建模接口实现模型构建。场景二:
对于一些变线业务,之前业务查询的sqlserver、mysql等等,因数据量膨胀已经无法支撑日常的olap场景,业务想通过现有的sql语句进行架构变线,则可以传入查询的sql语句,后台对sql解析出事实表、维度表、维度、指标等信息,实现自动建模。建模过程会结合hive表的元数据信息进行分析,合理的设置rowkey。根据多个sql分析,以及对hive、spark-sql、presto查询的所有关于该表的查询sql的字段进行分析,合理优化维度组合,减少人工干预,快速构建模型。
欢迎点赞+收藏
欢迎转发至朋友圈


