自然语言处理--序列标注模型
在人工智能异常火爆的当下,自然语言处理技术因其具有广泛的应用领域、良好的计算性能等因素备受科研人员的青睐;而序列标注是自然语言处理领域的一个非常常见的问题,从分词、词性标注,到较深层的组块分析以至更为深层的完全句法分析、语义角色标注等任务,都可以看作是典型的序列标注问题。
序列标注问题指对序列中每个元素进行标记,输出标记序列y = y1, . . . , yn,n是序列的长度。若yi 的取值范围定义为S = {si},输出序列的可能组合数为Ci。变量yi 的不同取值也叫不同的状态。yi 所有可能取值的集合S,也被称为“状态空间”。因为一个序列状态的组合数非常多,也不能直接用传统的学习方法通过枚举y 来得到最佳的标记,需要用动态优化的方法来求解y。
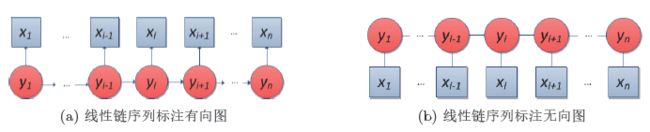
传统的单点分类器方法难以获得整个序列的最优标记。下图是两种线性链序列标注结构,每个元素标记只与相邻的元素相关,构成了线性链式结构。其中,图a是有向图结构,每个元素标记只与前一个元素标记相关,图b是无向图结构,每个元素标记与左右两个相邻元素标记相关。
序列标注问题需要解决四个问题:
1. 如何选择合适的序列标注模型?确定标记之间的关联关系。
2. 怎样从序列上抽取特征?
3. 如何进行求解?也就是解码问题。
4. 如何进行参数学习?
常用的序列标注模型有:线性模型、隐马尔可夫模型、最大熵马尔可夫模型、条件随机场等;
马尔可夫链,简称马氏链,是由随机变量组成的一个序列x1, x2, x3, · · · ,xt 的值是在时间t 时的状态。如果xt+1 对于过去状态的条件概率分布仅是xt 的一个函数,即P(xt+1|x1, x2, · · · , xt) = P(xt+1|xt) 。
序列标注模型可以分为两大类:一种是非统计方法,另一种是统计的方法:
在非统计方法中,最有代表性的是线性分类器:y = arg max w · O(x, y),
在基于统计方法,比较主流的方法是用无向图来表示模型。
对于中文分词的序列标注问题,可以定义y 属于 {B,O},这里B 表示把当前字作为一个新词的开始,O表示当前字与前面的字构成一个词。例如:句子“他/说/的/确实/在理”转化为下面以字为基本元素构成的序列。
x = 他 说 的 确 实 在 理
y = B B B B O B O
假设状态空间大小为C,对于长度为n的y,其可能的组合数为Cn。因此,穷举不同的y已获得最佳序列是不可行的。通过观察公式,我们可以用动态优化方法来快速的求解。我们首先定义As,i 是输入序列x0, · · · , xi 且yi = s 的最佳标记序列。As,i 可以通过下面两个递归公式来计算:As,0 = 0, s 属于S ;As,i = maxAs′,i−1 + w · ϕ(x, s′, s);这个方法也叫Viterbi 算法,可以保证找到得分最高的标记序列,有点动态规划的意思在里面。
学习参数的方法也不同,一般为最大似然估计、最大边际距离或最小均方误差等。可以用传统的分类器训练算法,比如感知器、SVM、kNN等。
隐马尔可夫模型(HMM)是常见的序列标注模型。
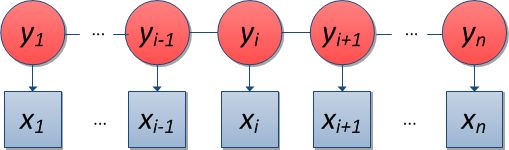
HMM有三个典型问题:
1 已知模型参数,计算某一特定输出序列的概率. 通常使用forward 算法解决.
2 已知模型参数,寻找最可能的能产生某一特定输出序列的隐含状态的序列. 通常使用
Viterbi 算法解决.
3 已知输出序列,寻找最可能的状态转移以及输出概率. 通常使用Baum-Welch 算法以及
Reversed Viterbi 算法解决
隐马尔可夫模型是一个生成式模型,要对p(x, y) 进行建模。并且样本序列的观测值只与当前状态(标记)有关,这就限制了模型的能力。最大熵马尔可夫模型是一个判别式模型,直接对p(y|x) 进行建模,这样可以利用大量的冗余特征提高模型性能。
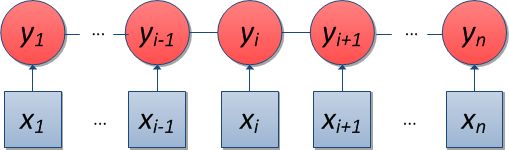
最大熵马尔可夫模型是用局部信息去优化全局,会有标注偏置(Label Bias)的问题。条件随机场(Conditional Random Fields, CRF)图模型,它是在给定需要标记的观察序列x 的条件下计算整个标记序列y 的联合概率分布,而不是在给定当前状态条件下定义下一个状态的分布。即P(y|x) = exp(w · O(x, y))/Zx;隐马尔可夫模型中存在两个假设:输出独立性假设和马尔可夫性假设。其中,输出独立性假设要求序列数据严格相互独立才能保证推导的正确性,而事实上大多数序列数据不能被表示成一系列独立事件。而条件随机场则使用一种概率图模型,条件随机场没有隐马尔可夫模型那样严格的独立性假设条件,因而可以容纳任意的上下文信息,可以灵活地设计特征。同时,条件随机场具有表达长距离依赖性和交叠性特征的能力,而且所有特征可以进行全局归一化,能够求得全局的最优解,还克服了最大熵马尔可夫模型标记偏置的缺点。条件随机场模型作为一个整句联合标定的判别式概率模型,同时具有很强的特征融入能力,是目前解决自然语言序列标注问题最好的统计模型之一。条件随机场的缺点是
训练的时间比较长。
, 上面简单介绍了基本的序列标注的模型方法,以后会详细分析。