基于ELK的日志收集分析系统(Elasticsearch+Filebeat+Kibana)
背景:
传统意义上,查找日志都是通过shell等工具登陆服务器后台去相应的日志目录下查看log文件,特别是
联调、测试时,我们需要通过tail -f 、grep 'xxx’等命令,肉眼观察日志,如果是一个复杂的业务流程,
则需要辗转多个日志目录下,并且没有统计分析等功能。
思考:
对于我们的业务系统,现在已经存在了一套日志收集系统(syslog+flume+kafka+elasticsearch),但
是是基于核心业务,收集的都是需要做分析统计和机器学习的业务日志,对于研发人员来说,需要关心
的是程序运行时log文件的日志。本着不影响核心业务的原则(如果也用flume接入log文件日志有影响
业务的风险),所以笔者调研了现在主流的ELK,本文将快速部署一套供研发人员使用的日志搜索系
统,即装即用,非常轻量级。
ELK:
ELK 是elastic公司提供的一套完整的日志收集以及展示的解决方案,是三个产品的首字母缩写,分别是
ElasticSearch、Logstash 和 Kibana,整个ELK生态圈有很多周边插件,而Logstash因为太重量级,启
动需要占用大量内存资源,并且侧重于分析过滤格式化,可以和flume进行替换,对于简单的日志收
集,官网出了一个更轻量级的替代产品filebeat,也是官方推荐使用。官网传送门 https://www.elastic.
co/cn/
原理:
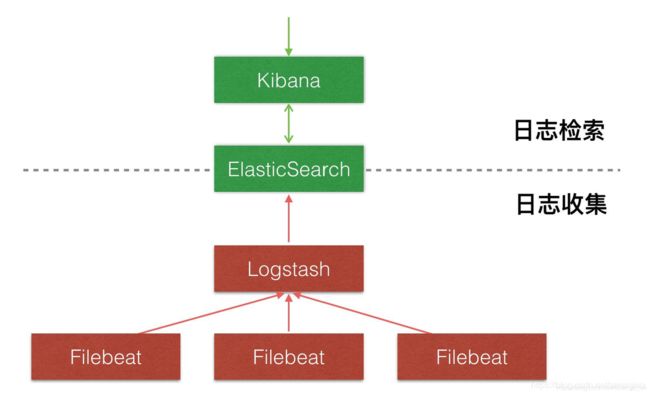
搭建ELK
一、Elasticsearch安装配置:
1、下载地址:
https://www.elastic.co/cn/downloads/elasticsearch,3个组件需要版本一致
tar -vxf elasticsearch-7.5.1.tar.gz
2、配置文件:
打开/config/elasticsearch.yml
#ip
network.host: ***.***.*.**
#端口
http.port: 9200
#主要用于集群配置,可以先放开,不打开会报错,后边具体说;ES名称,多台服务器配置名称不可相同
node.name: node-1
cluster.initial_master_nodes: ["node-1"]
3、启动:
ES默认不能用root启动,需新增一个用户,adduser esuser ,su esuser
进入bin目录,执行./elasticsearch &
4、验证:
访问http://ip:9200,返回数据则启动成功
二、Filebeat安装配置:
1、下载地址:
https://www.elastic.co/cn/downloads/beats/filebeat
tar -vxf kibana-7.5.1.tar.gz
2、配置文件:
进入安装目录下,打开filebeat.yml
注释:在inputs中配置了两个目录的.log文件,在output中也配置了两个会在es中产生的index
#=========================== Filebeat inputs =============================
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/ida/ida-osquery-service/*.log
multiline.pattern: '^[[:space:]]+(at|\.{3})\b|^Exception|^Caused by'
multiline.negate: false
max_lines: 20
multiline.match: after
document_type: "osquery"
tags: ["osquery"]
fields:
type: 'osquery'
- type: log
enabled: true
paths:
- /var/log/ida/ida-restful-api/*.log
multiline.pattern: '^[[:space:]]+(at|\.{3})\b|^Exception|^Caused by'
multiline.negate: false
max_lines: 20
multiline.match: after
document_type: "restful"
tags: ["restful"]
fields:
type: 'restful'
#================================ Outputs =====================================
#-------------------------- Elasticsearch output ------------------------------
output.elasticsearch:
hosts: ["ip:9200"]
indices:
- index: "osquery-%{+yyyy.MM.dd}"
when.equals:
fields.type: "osquery"
- index: "restful-%{+yyyy.MM.dd}"
when.equals:
fields.type: "restful"
3、启动:
/usr/local/filebeat-7.5.1-linux-x86_64/filebeat -e -c /usr/local/filebeat-7.5.1-
linux-x86_64/filebeat.yml -d "publish" &
4、验证:
ps -aux|grep filebeat
![]()
三、Kibana安装配置:
1、下载地址:
https://www.elastic.co/cn/downloads/kibana
2、配置文件:
server.host: "ip"
elasticsearch.hosts: ["http://ip:9200"]
i18n.locale: "zh-CN"
3、启动:
kibana默认不允许root启动,后面加上 --allow-root &
/usr/local/kibana-7.5.1-linux-x86_64/bin/kibana --allow-root &
4、验证:
kibana会监听5601端口,访问http://ip:5601
四、开始启用
首先需要创建索引模式,需要关注filebeat的配置文件
1、创建索引模式
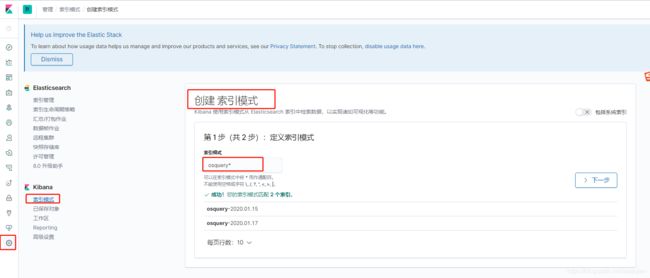
自动匹配到filebeat中创建的index
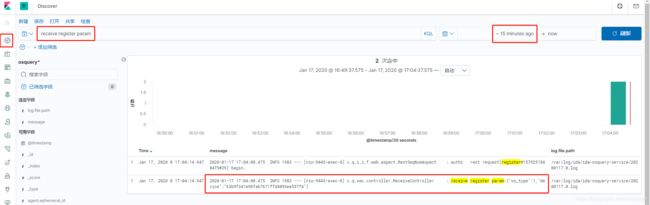
2、查询日志
模拟产生一条日志,在搜索栏输入关键字,效果如下:
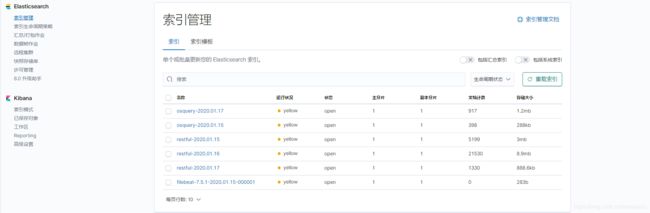
3、索引管理
在filebeat中配置了index的名字,osquery-%{+yyyy.MM.dd},会每天自动生成一个ES索引日志文件
五、总结
至此,基于ELK的日志搜索系统搭建完成,10分钟落地启用,告别传统的去服务器目录下查log文件的方
式,拥抱新技术。下一篇将分享笔者是怎么一键部署ELK的。