前言
我们看了一些,爬虫示例,对爬虫应该有比较深的理解了,
还是爬取评论,这次选择B站
点开B站,打开F12,点击评论,看ajax,观察规律,找到url
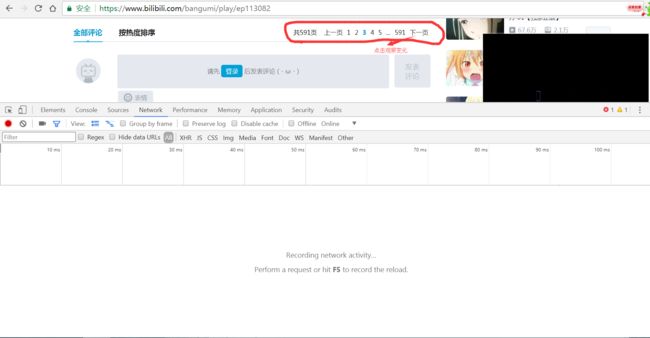
找到url,很容易
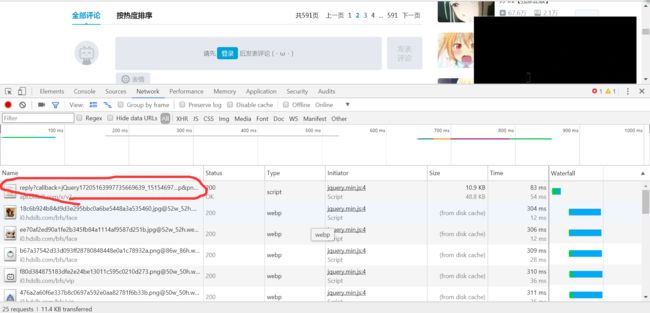
https://api.bilibili.com/x/v2/reply?callback=jQuery17205163997735669639_1515469704917&jsonp=jsonp&pn=2&type=1&oid=12009509&sort=0&_=1515471170772
多抓取几次,相互比较,得出规律,然后对url缩减
https://api.bilibili.com/x/v2/reply?jsonp=jsonp&pn=2&type=1&oid=12009509&sort=0
然后测试返回的类型,是src,我们转为dict,根据key=value获得我们需要的数据
代码
import requests
#获取评论
for page in range(10):#评论的页数
url = 'https://api.bilibili.com/x/v2/reply?jsonp=jsonp&pn={page}&type=1&oid=12009509&sort=0'.format(page=page)
resp = requests.get(url)
data = resp.json()
comment_list = data['data']['replies']
for com in comment_list:
comment = com['content']['message']
print(comment)
大概思路就是这样的,具体细节,自己完善。
爬虫之魂
我们都知道,用机器去爬取信息和人为的浏览信息是有很大的不同的。所以,网站也会经常封锁我们的爬虫,对此,我们常用的策略是伪装成浏览器,降低访问频率,让爬虫的行为更像人为的浏览。当然如果只是伪装成浏览器,降低了你的访问速度,网站仍然会封锁你的爬虫。让你访问受限,比如,访问十次该网址,就封锁,导致出错,但是,过一段时间,我们重新运行程序又可以爬取数据了。所以,为了减少麻烦,我们可以设置策略:
当我们知道自己的爬虫被封锁了以后,降低访问频率,但是还是要一直发送请求,锲而不舍,直到又可以爬取为止。坚持就是胜利。
伪装成浏览器
import requests
def scraper(url):
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'}
cookies = {'Cookie':'你的cookies'}
resp = requests.get(url,headers,cookies)
"""省略。。。解析网页"""
"""省略。。。保存数据"""
#待爬urls
urls = [...]
for url in urls:
scraper(url)
降低访问频率
import requests
import time
def scraper(url):
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'}
cookies = {'Cookie':'你的cookies'}
resp = requests.get(url,headers,cookies)
"""省略。。。解析网页"""
"""省略。。。保存数据"""
#待爬urls
urls = [...]
for url in urls:
scraper(url)
time.sleep(1)
锲而不舍
import requests
import time
def scraper(url):
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'}
cookies = {'Cookie':'你的cookies'}
resp = requests.get(url,headers,cookies)
"""省略。。。解析网页"""
"""省略。。。保存数据"""
#拥有锲而不舍精神的爬虫(slow but steady)
def scraper_with_perseverance(url):
Flag = True
while Flag:
try:
#正常爬取,爬取成功后退出循环
scraper(url)
Flag = False
except:
#被网站封锁后,降低访问频率,但仍坚持重复访问,
#直到爬取到该url的数据,退出本url的爬虫
Flag = True
time.sleep(5)
#待爬urls
urls = [...]
for url in urls:
scraper_with_perseverance(url)
time.sleep(1)
tips
如果爬的还是太多,建议使用代理IP
推荐
fake-useragent库,可以伪装生成headers请求头中的User Agent值
安装pip install fake-useragent
使用功能random方法
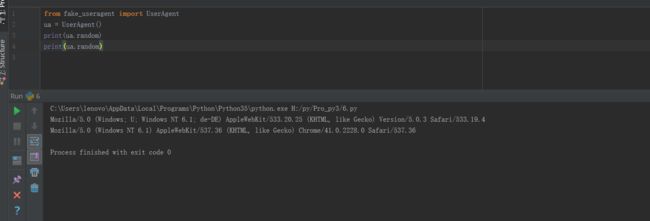
爬虫中使用
from fake_useragent import UserAgent
import requests
ua = UserAgent()
headers = {'User-Agent': ua.random}
url = '待爬取的url'
resp = requests.get(url,headers=headers)