大数据平台OLTP应用场景案例分析
大数据平台OLTP应用场景案例分析
前言
Hadoop大数据平台在当今的IT业界是非常热门的话题, 如果你关注它们的应用场景,大多数情况是做OLAP智能分析以及数据挖掘。鲜有类似于传统关系型数据库擅长的OLTP事务处理场景。今天和大家分享一个在大数据平台上OLTP应用场景案例。
背景
某国内车联网企业A,主要提供给各类大巴,货车公司安装各类传感器服务,并通过传感器收集日常车辆轨迹及各种告警违规数据。基于这些数据提供给客户实时的轨迹和告警查询,以及历史统计信息的查询。
业务需求
车辆每隔10秒中上传一条数据,同时在线的车辆数量在7万辆,要求用户能做近实时的车辆轨迹信息查询,数据加载要达到每秒8000条。为获得最佳的用户体验,查询响应时间要小于1秒,用户的并发查询数要大于100。
业务平台每天产生超过200万条告警记录,查询跨度为15天,响应时间要求在1秒以内。
业务平台每天产生5亿多条违规记录,每天需要对这些记录进行读取和统计并存储到统计表中。由于数据量较大,统计SQL复杂,该操作可在夜间闲时进行。数据读取,统计以及存储过程不能超过8小时。
工作负载特性分析
通过上面章节的分析,这是典型的混合负载。数据库既要面对汽车传感器频繁的数据加载请求迅速完成数据插入(INSERT),同时也要满足前台用户对此类数据的近实时的查询需求(SELECT). 这就意味着要对数据库进行频繁的读和写操作。同时要对每天生成的大规模数据进行读取和分析以及统计。
解决方案
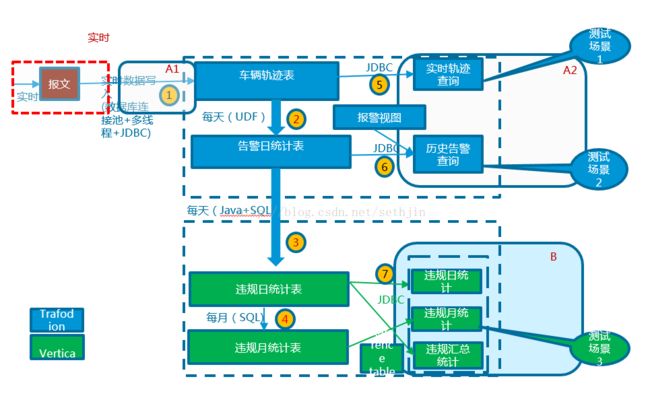
针对前章所述的的工作负载特性,并对比市场上不同的产品方案,最终采取了Trafodion+Vertica的混合解决方案。
Trafodion是基于Hadoop/Hbase的数据库,它擅长于处理OLTP负载,对于高压力的数据插入有很好的性能表现。同时能够提供秒级的查询响应时间。在累计一天的数据后,在同一表内进行数据的ETL处理并生成违规日统计数据。
Vertica是基于列存储的数据库方案,对于复杂的查询读操作有很快速的响应速度。通过JDBC可以把Trafodion中的日违规统计数据直接插入到Vertica日违规统计表中。基于日违规统计表,通过数据统计处理生成月违规统计以及违规统计总表供用户查询。
客户端可通过调用标准JDBC/ODBC接口进行WEB应用程序的开发,以及BI和数据挖掘的应用开发。方案如下图所示
测试结果
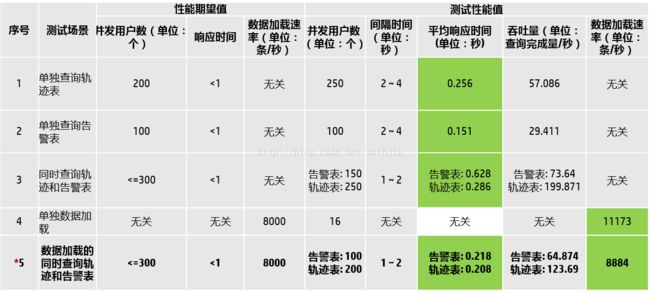
测试环境为6节点Trafodion加上3节点Vertica X86架构的集群。
测试背景数据为:车辆轨迹表格为133亿条记录,告警日统计表格3亿6千万条,违规日统计为2750万条记录,违规月统计为671万条。
Trafodion加载以及查询时间
由于Trafodion是基于Hadoop/Hbase的大数据平台,所以它也具备性能的可扩展性。因此也做了一系列的性能可扩展性测试(4,6,8个节点集群,以及不同的并发用户数括包括200,300,400,500以及600并发),结果如下表。
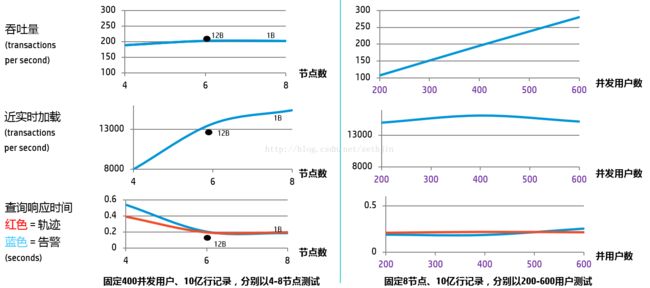
从以上结果可以看出在四节点集群配置下,可满足客户业务需求。考虑到未来车辆数量增多,可通过增加节点来提高加载速度以及缩短查询响应时间。
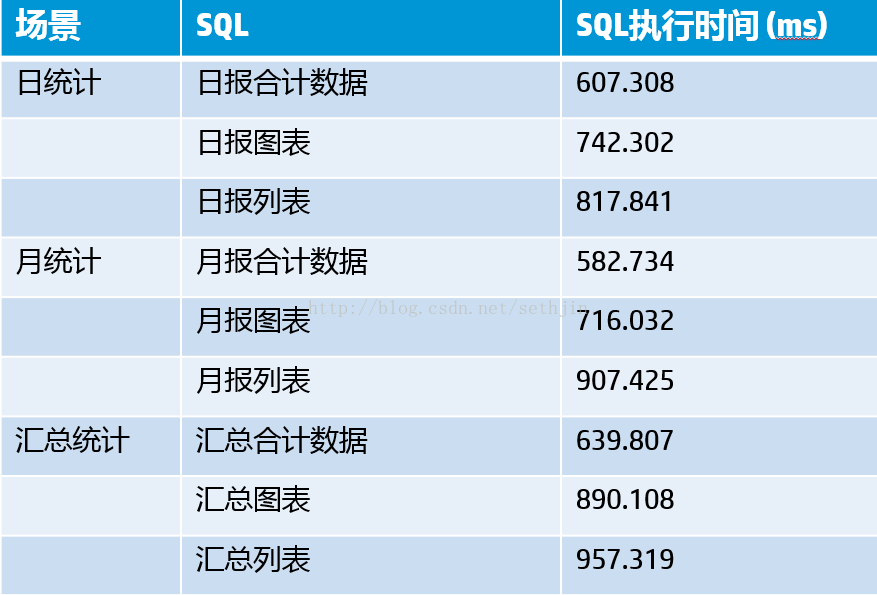
Vertica 查询执行时间
总结
通过Trafodion加Vertica的混合方案,可以很好的解决车联网行业的业务需求。虽然传统的关系型数据库(比如Oracle)也能满足业务需求。但由于Trafodion是基于Hadoop技术,它是能运行在成本更低廉的x86硬件之上的分布式系统,具有高可用性以及高扩展性。随着将来业务的扩展能更灵活地增节点,来提高系统的容量和性能。另外值得一提的是Trafodion是HP发起的一个开源项目,所以没有额外的软件license成本,并具备可自主开发的可能性,这能满足国内目前的技术趋势:开源技术,自主可控。
备注:以下是Trafodion的简单介绍。如果读者对Trafodion感兴趣,可访问开源社区: www.trafodion.org
Trafodion 简介
- 完整性: 支持完整的ANSI SQL集
可以利用已有的SQL技术储备来提高开发者的生产力
- 保护性: 支持分布式ACID事务操作
确保了跨行,跨表以及多个SQL语句操作数据的一致性
- 高效性: 对低延时要求的读写事务进行优化
目标是支持实时事务处理应用
- 灵活性:支持灵活的schema以及多种数据结构
无缝整合Trafodion,原生HBase和Hive表格
- 互操作性: 通过标准ODBC/JDBC访问数据
能够很好的和现有的工具和应用协同工作
- 扩展性:基于Hadoop 平台原生开发
高可用性,并且无限弹性扩展
- 开放性: 支持主流Hadoop和Linux开源发布
非常方便和现有的设备集成整合避免了第三方供应商的软硬件依赖性。
使用场景 (OLTP and ODS)

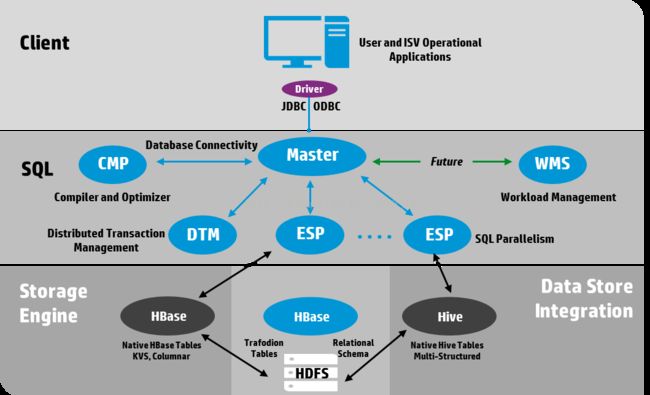
Trafodion 功能概览
• 支持全功能的ANSI SQL语言
• 支持严格的数据完整性
• 支持客户端通过ODBC/JDBC连接
• 支持分布式事务的ACID
• 无缝集成访问Trafodion, 原生HBase和Hive表格
• 具有非常成熟的SQL引擎技术,包括Cascades基于成本的优化器, MPP并发执行引擎;利用LLVM JIT生成运行时代码;支持UDF和存储过程
• 支持编译时与运行时负载优化
• SQL智能并行算法
系统架构图
Trafodion 优势
提供了全功能以及经过优化的基于HBase之上的事务型DBMS解决方案
• 可利用现有的SQL技术储备而不必掌握复杂的map/reduce 编程技术
• 便于客户二次开发以及独立软件供应商开发的应用,保护了客户的投资提高了客户的开发生产力。
• 工作负载的优化为下一代实时事务处理应用提供了基础。
• 保证了复杂事务的一致性(包含多个SQL语句, 跨行, 跨表格)
• 原有的Hadoop投资利益得到更好的补充,降低了成本,有更好的弹性与扩展性。
• 由惠普资助和投资的开源项目