爬虫学习-scrapy爬取豆瓣电影top250
scrapy爬取豆瓣电影top250
学习一下爬虫,在网上看了几个教程,毕竟实践后理解才更深,遂自己跑一下。
工具和环境
- scrapy 1.5.0
- python 3.5
- chrome
scrapy的简单认识
scrapy的数据流图
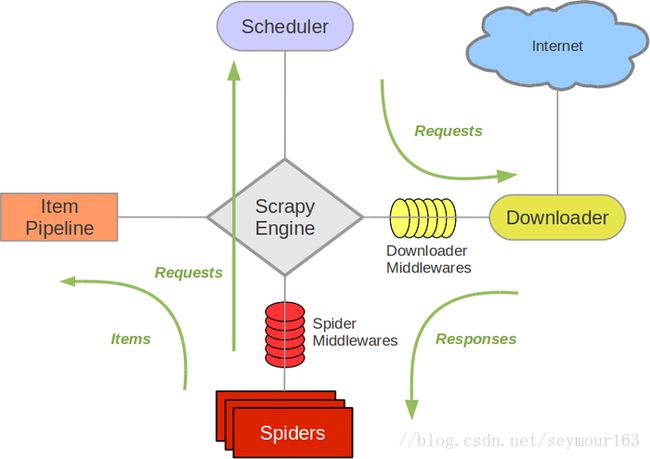
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
创建项目
scrapy startproject moviespider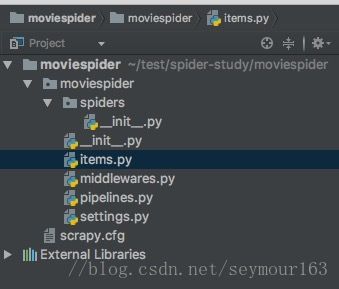
- items.py 定义需要获取的内容字段
- middlewares.py 爬虫中间件,这里可以用过自定义相关的方法,用来处理爬虫的响应和请求。
- pipelines.py 用来对Spider爬取的数据进行处理
- setting.py 项目设置文件
- scrapy.cfg 项目配置文件
定义item(items.py)
Item 对象保存爬取的数据的容器,其提供了类似于词典(dictionary-like) 的API以及用于声明可用字段的简单语法。
这里在items.py定义爬取的内容,电影排名ranking,名称name和评分score。
import scrapy
class MoviespiderItem(scrapy.Item):
# define the fields for your item here like:
ranking = scrapy.Field()
name = scrapy.Field()
score = scrapy.Field()编写爬虫(movie_spider.py)
Spider类中定义抓取对象(域名、URL)以及抓取的规则,创建自己的Spider,必须继承 scrapy.Spider 类, 且定义以下三个属性:
- name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
- start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
- parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
在moviespider/spiders下创建douban_spider.py
import scrapy
from scrapy.spiders import Spider
from moviespider.items import MoviespiderItem
class MovieTop250Spider(Spider):
name = 'movie_top250'
# 如果网站设置有防爬措施,需要添加上请求头信息,不然会爬取不到任何数据
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
start_urls = [
'https://movie.douban.com/top250'
]
# start_requests方法为scrapy的方法,对它进行重写。
# 该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取的第一个Request。当spider启动爬取并且未制定URL时,该方法被调用。
# 当指定了URL时,make_requests_from_url() 将被调用来创建Request对象。
# 该方法仅仅会被Scrapy调用一次,因此您可以将其实现为生成器。
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url=url, callback=self.parse, headers=self.headers)
def parse(self, response):
pass提取页面信息
打开豆瓣电影top250页面https://movie.douban.com/top250,command+alt+i(windows下为f12)打开开发者工具,用抓取工具(在左上角)选择找到信息所在的标签。
可以找到这里的电影信息在一个叫class属性为grid_view的ol标签内的li标签内,在class=item的div下。
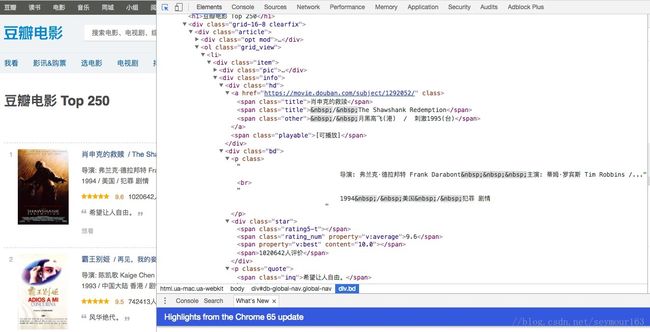
parse页面信息
从response里面解析或者说提取出要爬取的信息,可以实用XPath,CSS,beautifulsoup等,我都是第一次接触,都不太熟悉,看了XPath和CSS的提取方法后,个人感觉CSS的语法干净一点,就选择CSS了。beautifulsoup其实感觉也不错,会把html变为python的对象,转化成字典和数组,可能更好用,后面学习一下怎么用。一个讲beautifulsoup的博客链接
def parse(self, response):
item = MoviespiderItem()
for quote in response.css('div.item'):
item['name'] = quote.css('div.info div.hd a span.title::text').extract_first()
item['ranking'] = quote.css('div.pic em::text').extract()
item['score'] = quote.css('div.info div.bd div.star span.rating_num::text').extract()
yield item
next_url = response.css('div.paginator span.next a::attr(href)').extract()
if next_url:
next_url = "https://movie.douban.com/top250" + next_url[0]
print(next_url)
yield scrapy.Request(next_url, headers=self.headers)自动翻页
不能只让爬虫爬一页的信息,为了爬到完整的信息,需要让它自己翻页去下一页,实现自动翻页一般有两种方法:
- 在页面中找到下一页的地址;
- 自己根据URL的变化规律构造所有页面地址。
我们选择第二种,跟前面一样,在html中用css提取到next页的地址,然后继续发送request请求,这里的代码在上面的parse函数。
运行看结果
在命令行运行
scrapy crawl movie_top250 -o movie_list.csv
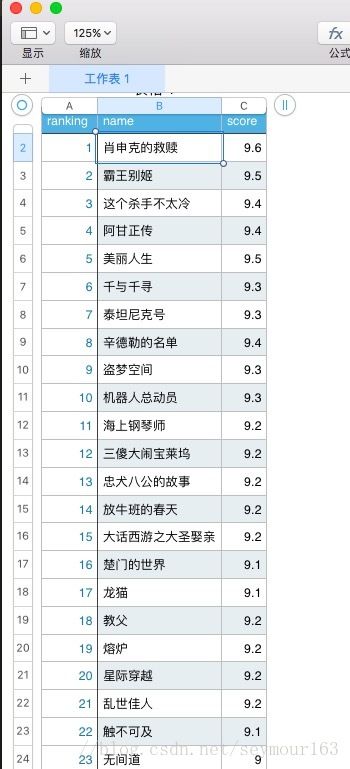
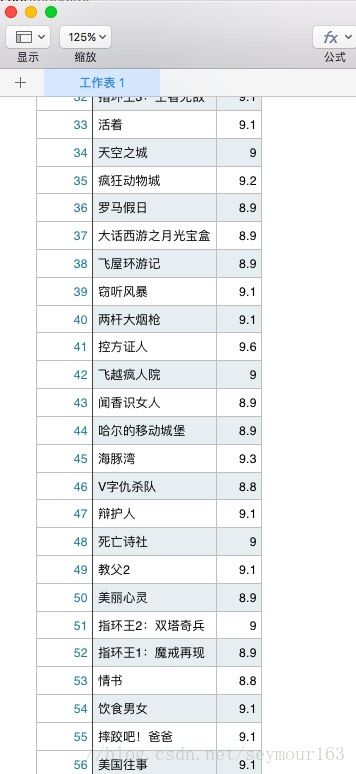
部分爬取结果