哪吒影评简单可视化分析
简单说说
写些代码简单分析一下哪吒的观影影评,步骤还是先爬取数据,然后利用pandas读取,可视化,最后把评论绘制成词云
开始动手
全程大概半个小时左右,都是一些老套路
- 爬取数据
- 数据分析
- 提取评论绘制词云
1.爬取数据
在这里来查看评论https://m.maoyan.com/movie/1211270/comments?v=yes
F12开始分析网页
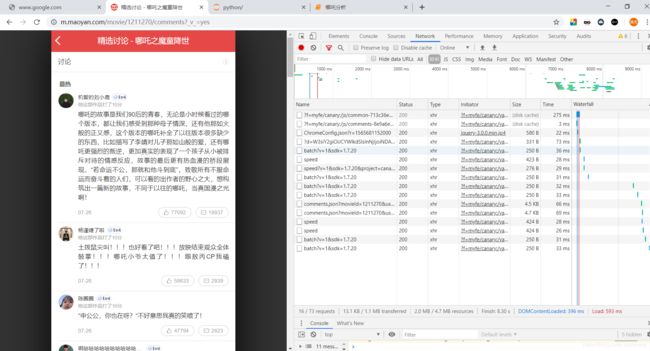
可以往下滑会发现出现很多不同的comments.json……,然后会发现不同的评论offset=后面接的数字不同,这就是待会爬取大量数据的基础。
然后在获取请求头并且复制下来
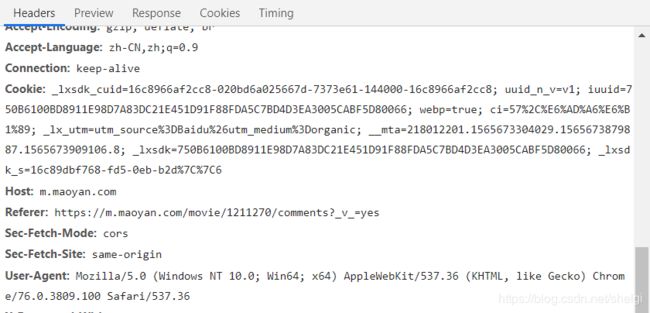
稍微看一下评论json的数据内容

大概就是性别,评分,评论,点赞数,用户等级还有一些图片等等,我们就只提取其中的性别,评分,评论,点赞数,用户等级好了
然后附上爬取数据部分的代码
import requests
import json
import csv
headers={
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Mobile Safari/537.36'
}#刚才复制的请求头
def data():
for i in range(0,50):#这是设置爬取数据的多少,为了节约时间我设成50
url='https://m.maoyan.com/review/v2/comments.json?movieId=1211270&userId=-1&offset={}&limit=15&ts=0&type=3'.format(i)
response=requests.get(url,headers=headers)
#print(response.content)
get_data(response.text)
print("哪吒评论数据保存完成")
def get_data(text):
data={}
content=json.loads(text)
#print(content['data'].get('comments'))
comments=content['data'].get('comments')
#开始提取信息
for i in comments:
#data['gender']=i.get('gender')#未知为0,男为1,女为2
if(i.get('gender')==0):
data['gender']='未知'
elif(i.get('gender')==1):
data['gender']='男'
elif(i.get('gender')==2):
data['gender']='女'
data['score']=i.get('score')#评分
data['content']=i.get('content')#评论
data['upCount']=i.get('upCount')#点赞数
data['userLevel']=i.get('userLevel')#用户等级
save_data(data)
def save_data(data):
with open('G:/数据分析/nezha.csv','a',encoding='utf-8-sig',newline='') as f:
writer=csv.writer(f)
title=['gender','score','content','upCount','userLevel']
writer.writerow([data[i] for i in title])
data()
这样就把所需要的内容保存到了我的csv文件里了
2.数据分析
因为得到的数据没什么特别的,所以我就简单的用饼图显示一下性别比例和评分比例
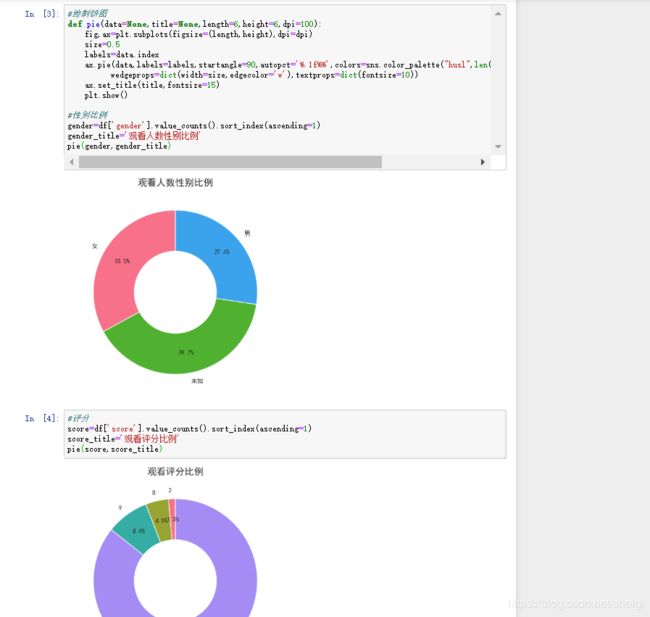
代码:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style("ticks")
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
df=pd.read_csv('G:/数据分析/nezha.csv',encoding='utf8',header=0,names=['gender','score','content','upCount','userLevel'])
df.info()
df.head(10)
#绘制饼图
def pie(data=None,title=None,length=6,height=6,dpi=100):
fig,ax=plt.subplots(figsize=(length,height),dpi=dpi)
size=0.5
labels=data.index
ax.pie(data,labels=labels,startangle=90,autopct='%.1f%%',colors=sns.color_palette("husl",len(data)),radius=1,pctdistance=0.75,
wedgeprops=dict(width=size,edgecolor='w'),textprops=dict(fontsize=10))
ax.set_title(title,fontsize=15)
plt.show()
#性别比例
gender=df['gender'].value_counts().sort_index(ascending=1)
gender_title='观看人数性别比例'
pie(gender,gender_title)
#评分
score=df['score'].value_counts().sort_index(ascending=1)
score_title='观看评分比例'
pie(score,score_title)
3.绘制词云
提取刚才df中的评论,另存为txt文件,然后用jieba+wordcloud绘制词云
import jieba
from wordcloud import WordCloud
df['content'].to_csv('G:/数据分析/nezha.txt',index=False)
f=open('G:/数据分析/nezha.txt',encoding='utf8')
txt=f.read()
f.close()
words=jieba.lcut(txt)
nettxt=' '.join(words)
wordcloud=WordCloud(background_color='white',width=800,height=600,font_path='msyh.ttc',max_words=200,max_font_size=80).generate(nettxt)
wordcloud.to_file('G:/数据分析/哪吒评论词云.png')

满满的都是好评,说明确实是一部值得观看的作品。
总结
只要安装了相关的模块,实现起来一点也不难。如果需要现成的,我会把ipynb文件待会上传,需要的可以下载来看看,只要更改相关的路径就好。继续去学算法啦,明天会写一下二叉堆(最小堆)的实现和原理。