【深度学习】Torch卷积层源码详解
本文以前向传播为例,详细分析Torch的nn包中,SpatialConvolution函数的实现方式。
在分析源文件时,同时给出了github上的链接以及安装后的文件位置。
初始化
定义一个卷积层需要如下输入参数
nInputPlane\nOutputPlane -- 输入\输出通道数,M\N
kW\kH -- 核尺寸,K
dW\dH -- 步长
padW\padH -- 补边卷积层的核心变量
weight -- 卷积核权重,N*M*K*K
bias -- 卷积核偏置,N
gradWeight -- 权重导数,N*M*K*K
gradBia -- 偏置导数,N为效率起见,torch的层采用分层方式实现:
nn(lua)->THNN(C)->THTensor(C)->THBlas(C)->LAPACK(Fortran)nn(lua)层次
在/extra/nn/SpatialConvolution.lua中,定义了卷积层的lua接口。
前向运算的函数是updateOutput(input),其中执行运算的部分如下:
input.THNN.SpatialConvolutionMM_updateOutput(
input:cdata(), self.output:cdata(),
self.weight:cdata(), THNN.optionalTensor(self.bias),
self.finput:cdata(), self.fgradInput:cdata(),
self.kW, self.kH, self.dW, self.dH, self.padW, self.padH
)其中input.THNN是输入Tensor的一个C接口,传入的参数也都用:cdata()转化成是C类型。
Torch中另有/extra/nn/SpatialConvolutionMM.lua,未在文档中出现,内容几乎相同,不做分别。
THNN库
THNN是一个C库,包含了nn包中的C实现,可以不依赖Lua运行。
/extra/nn/lib/THNN/generic/THNN.h包含了库中函数的声明。
THNN库中大量采用了宏定义的方式来命名,例如:
TH_API void THNN_(SpatialConvolutionMM_updateOutput)(...)
TH_API void THNN_(SpatialConvolutionMM_updateGradInput)(...)以THNN_开头的函数定义在/extra/nn/lib/THNN/generic/目录下,这两个在SpatialConvolutionMM.c文件中。
其他几个库
顺便辨识一下几个容易混淆的库/包:
- nn(lua)->THNN(C)
- cunn(lua)->THCUNN(cuda)
在Torch自己的github下维护;
lua文件在/extra/nn/目录下;
C文件在/extra/nn/lib/THNN/generic/目录下,cuda文件在/extra/nn/lib/THCUNN/目录下;
nn中的数据/层通过:cuda()可以转化为cunn中的数据/层;反之,则使用:float()。
- cudnn(lua)->cuDNN库
在Torch的重要作者soumith的gihub下维护;
lua文件在/extra/cudnn/目录下;
实现部分需要安装cuDNN;
nn中的层可以通过cudnn.convert(net,cudnn)转化为cudnn中的层;反之则使用cudnn.convert(net,nn)
THNN(C)层次
/extra/nn/lib/THNN/generic/SpatialConvolutionMM.c实现了卷积层的核心功能。分三步骤实现。
Step 1
首先,把输入的3D或4D的input展开成2D或3D的finput:
THNN_(unfolded_copy)(finput, input, kW, kH, dW, dH, padW, padH, nInputPlane, inputWidth, inputHeight, outputWidth, outputHeight);THNN_(unfolded_copy)是Torch中的重要函数,在/extra/nn/lib/THNN/generic/unfold.c中定义。
input尺寸为M*H*W。对于每一通道,根据卷积尺寸,将其进行平移,获得K*K个结果。这些结果摞起来得到(M*K*K)*(H*W)的finput。
例:设
input尺寸为2*4*4,两通道如下
使用3*3卷积核时,每一通道共有3*3=9个平移结果。卷积模板9个像素位置对应的平移为:

平移1=右移1+下移1:
平移4 = 右移1


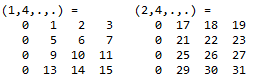
相应地,把卷积权重weight也整理成2D矩阵N*(M*K*K)
Step 2
接下来,创建N*(H*W)的输出矩阵output:
output2d = THTensor_(newWithStorage2d)(output->storage, output->storageOffset,
nOutputPlane, -1, outputHeight*outputWidth, -1);THTensor_开头的函数在/pkg/torch/lib/TH/generic/THTensor.h中声明。
然后把卷积层的bias逐通道地复制到输出output中。
for(i = 0; i < nOutputPlane; i++)
THVector_(fill)(output->storage->data+output->storageOffset+output->stride[0]*i, THTensor_(get1d)(bias, i), outputHeight*outputWidth);相似地,THVector_开头的函数直接在/pkg/torch/lib/TH/generic/THVector.c中声明和定义。
Step 3
平移展开后的输入finput,通过与weight的矩阵乘法,得到N*M*H*W的卷积结果output。
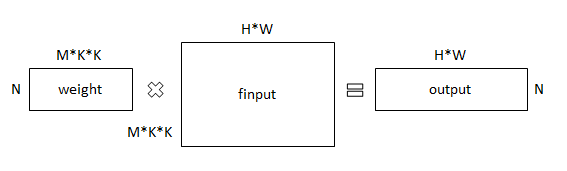
这一步是卷积的核心,通过/pkg/torch/lib/TH/generic/THTensorMath.c中的函数实现:
THTensor_(addmm)(output2d, 1, output2d, 1, weight, finput);THTensor层次
许多以THTensor_开头的函数都定义在/pkg/torch/lib/TH/generic/目录下,包括THTensor.c,THTensorConv.c,THTensorRandom.c等。前述矩阵乘法定义在THTensorMath.c中。
经过一系列合法性检查,执行乘法的是一个THBlas_函数:
THBlas_(gemm)(transpose_m1,
transpose_m2,
r__->size[(transpose_r == 'n' ? 0 : 1)],
r__->size[(transpose_r == 'n' ? 1 : 0)],
m1_->size[(transpose_r == 'n' ? 1 : 0)],
alpha,
THTensor_(data)(m1_),
(transpose_m1 == 'n' ? m1_->stride[(transpose_r == 'n' ? 1 : 0)] : m1_->stride[(transpose_r == 'n' ? 0 : 1)]),
THTensor_(data)(m2_),
(transpose_m2 == 'n' ? m2_->stride[(transpose_r == 'n' ? 1 : 0)] : m2_->stride[(transpose_r == 'n' ? 0 : 1)]),
beta,
THTensor_(data)(r__),
r__->stride[(transpose_r == 'n' ? 1 : 0)]);其中m1是卷积权重,m2是展开的输入。
THBlas(C)层次
/pkg/torch/lib/TH/generic/THBlas.c包含THBlas_(gemm)的实现。
根据数据的类型(double/float),调用LAPACK的dgemm_或sgemm_函数:
#if defined(TH_REAL_IS_DOUBLE)
dgemm_(&transa, &transb, &i_m, &i_n, &i_k, &alpha, a, &i_lda, b, &i_ldb, &beta, c, &i_ldc);
#else
sgemm_(&transa, &transb, &i_m, &i_n, &i_k, &alpha, a, &i_lda, b, &i_ldb, &beta, c, &i_ldc);
#endif