推荐系统总结
- 一、推荐系统结构
- 二、推荐引擎算法(Algorithm)
- 1、协同过滤推荐算法
- 1.1 关系矩阵与矩阵计算
- 1.1.1 用户与用户(U-U矩阵)
- 1.1.2 物品与物品(V-V矩阵)
- 1.1.3 用户与物品(U-V矩阵)
- 1.1.4 奇异值分解(SVD)
- 1.1.5 主成分分析(PCA)
-
- 目标:PCA目标是使用使用另一组基去重新描绘得到的数据空间,新的基要尽可能揭示原有数据的关系。
- 本质:实际上是K-L变换(卡洛南-洛伊(Karhunen-Loeve)变换),又名:最优正交变换
-
- 1.2 基于记忆的协同过滤算法
- 1.2.1 基于用户的协同过滤算法
- 基于用户的协同过滤算法主要包含以下两个步骤:
- 适用性
- 1.2.2 基于物品的协同过滤算法
- 基于物品的协同过滤算法主要分为两步:
- 适用性
- U-CF与I-CF比较
- 1.2.1 基于用户的协同过滤算法
- 1.3 基于模型的协同过滤算法
- 1.3.1 基于隐语义模型的协同过滤算法(LFM)
- 主要用于:填充用户打分矩阵的缺失值
- 思路来源:应该有一些隐藏的因素(不一定是人可以理解的)影响用户的评分,找到隐藏因子,可以对U和I进行关联;假定隐藏因子的个数小于U和I的数目,,因为如果每个User都关联一个独立的隐藏因子,那就没法预测了;
- 离线计算的空间复杂度
- 离线计算的时间复杂度
- 在线实时推荐
- 推荐解释
- 1.3.2 基于朴素贝叶斯分离的推荐算法
- 适用性
- 1.3.1 基于隐语义模型的协同过滤算法(LFM)
- 1.1 关系矩阵与矩阵计算
- 2、基于内容的推荐算法(CB)
- 2.1 基础CB推荐算法
- 算法流程
- 适用场景
- 2.2 基于TF-IDF的CB推荐算法
- 算法原理
- 算法流程
- 2.3 基于KNN的CB推荐算法
- 2.4 基于Rocchio的CB推荐算法
- 2.5 基于决策树的CB推荐算法
- 2.6 基于线性分类的CB推荐算法
- 2.7 基于朴素贝叶斯的CB推荐算法
- 2.1 基础CB推荐算法
- 3、 基于知识的推荐算法
- 3.1 概述
- 3.2 约束知识与约束推荐算法
-
- 创建推荐任务
-
- 3.3 关联知识与关联推荐算法
-
- 算法原理
- 算法流程
- 适用场景
-
- 4、 混合推荐算法
- 4.1 加权式
- 4.2 切换式
- 4.3 混杂式
- 4.4 特征组合
- 4.5 特征补充
- 4.6 级联式
- 1、协同过滤推荐算法
- 三、推荐系统评估
- 1、打分系统-评分误差率
- 2、Top-N推荐系统
-
- 2.1 准确率
- 2.2 召回率
- 2.3、覆盖率
- 2.4、多样性
- 2.5、其他(新颖度、惊喜度、信任度、实时性)
-
一、推荐系统结构
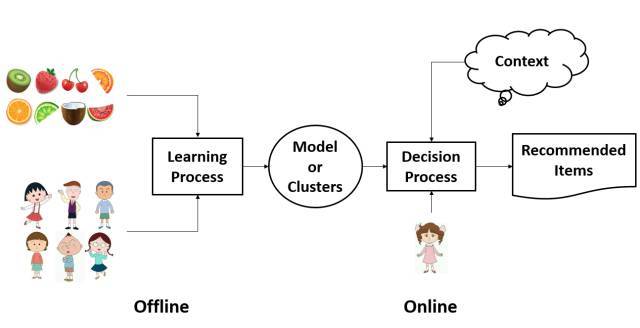
尽管不同的网站使用不同的推荐系统,但是总的来说,几乎所有的推荐系统的结构都是类似的,都由线上和线下两部分组成。线下部分包括后台的日志系统和推荐算法系统,线上部分就是我们看到的前台页面展示。线下部分通过学习用户资料和行为日志建立模型,在新的上下文背景之下,计算相应的推荐内容,呈现于线上页面中。
二、推荐引擎算法(Algorithm)
1、协同过滤推荐算法
1.1 关系矩阵与矩阵计算
1.1.1 用户与用户(U-U矩阵)
使用原理:Pearson相关系数主要用于度量两个变量 i 和 j 之间的相关性,取值范围是+1(强正相关)到-1(强负相关)
算法输入:用户行为日志。
算法输出:基于协同的用户相似度矩阵。
A. 从用户行为日志中获取用户与物品之间的关系数据,即用户对物品的评分数据。
B. 对于n个用户,依次计算用户1与其他n-1个用户的相似度;再计算用户2与其他n-2个用户的相似度。
对于其中任意两个用户 i 和 j :
a) 查找两个用户共同评价过的物品集;
b) 分别计算用户 i 和对物品 j 的平均评价和;
c) 计算用户间相似度,得到用户 i 和 j 的相似度。
C. 将计算得到的相似度结果存储于数据库中。
1.1.2 物品与物品(V-V矩阵)
使用原理:将物品的评价数值抽象为n维用户空间中的列向量 和,使用修正的余弦相似度
算法输入:用户行为日志。
算法输出:基于协同的物品相似度矩阵。
A. 从用户行为日志中获取用户与物品之间的关系数据,即用户对物品的评分数据。
B.对于n个物品,依次计算物品1与其他n-1个物品的相似度;再计算物品2与其他n-2个物品的相似度。
对于其中任意两个物品 i 和 j:
a)查找对物品 i 和 j 共同评价过的用户集;
b)分别计算用户对物品 i 和 j 的平均评价和;
c) 计算物品间相似度,得到物品 i 和 j 的相似度。
C. 将计算得到的相似度结果存储于数据库中。
1.1.3 用户与物品(U-V矩阵)
1.1.4 奇异值分解(SVD)
SVD将给定矩阵分解为3个矩阵的乘积:
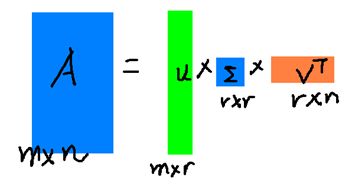
式中,矩阵为对角阵,其对角线上的值 为矩阵M的奇异值,按大小排列,代表着矩阵M的重要特征。将SVD用在推荐系统上,其意义是将一个系数的评分矩阵M分解为表示用户特性的U矩阵,表示物品特性的V矩阵,以及表示用户和物品相关性的矩阵。
1.1.5 主成分分析(PCA)
在推荐系统中,对于有较多属性的物品(物品的信息用向量 表示)可用PCA处理进行降维,将m×n的物品矩阵转化为m×k的新矩阵。
主成分分析(Principal Component Analysis,PCA), 是一种统计方法。通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。
目标:PCA目标是使用使用另一组基去重新描绘得到的数据空间,新的基要尽可能揭示原有数据的关系。
本质:实际上是K-L变换(卡洛南-洛伊(Karhunen-Loeve)变换),又名:最优正交变换
有了K-L变换(最优正交变换 )的知识做铺垫后,接下来提供PCA具体的计算过程
1、数据标准化
为什么要进行数据标准化,最主要的原因是消除量纲(即单位)带来的差异。常见的数据标准化方法有 0-1标准化,最大最小标准化。
2、计算协方差矩阵
设标准化的数据矩阵为X,则协方差矩阵cov(X,X)=1nXTX
3、求取协方差矩阵的特征值和特征向量
在matlab或者python里面都有相应的求特征值和特征向量的函数
4、对特征值从大到小排序,依据主元贡献率贺主元个数得到相应的的特征向量
1.2 基于记忆的协同过滤算法
1.2.1 基于用户的协同过滤算法

举个简单的例子,我们知道樱桃小丸子喜欢葡萄、草莓、西瓜和橘子,而我们通过某种方法了解到小丸子和花伦有相似的喜好,所以我们会把小丸子喜欢的而花伦还未选择的水果(葡萄和橘子)推荐给花伦。
基于用户的协同过滤算法主要包含以下两个步骤:
A. 搜集用户和物品的历史信息,计算用户u和其他用户的相似度,找到和目标用户Ui兴趣相似的用户集合N(u)
B.找到这个集合中用户喜欢的,且目标用户还没有听说过的物品推荐给目标用户。
适用性
由于需计算用户相似度矩阵,基于用户的协同过滤算法适用于用户较少的场合; 由于时效性较强,该方法适用于用户个性化兴趣不太明显的领域。
1.2.2 基于物品的协同过滤算法
基于物品的协同过滤算法是目前业界应用最多的算法。无论是亚马逊网,还是Netflix、Hulu、Youtube,其推荐算法的基础都是该算法。

基于物品的协同过滤算法给用户推荐那些和他们之前喜欢的物品相似的物品。比如,我们知道樱桃小丸子和小玉都喜欢葡萄和西瓜,那么我们就认为葡萄和西瓜有较高的相似度,在花伦选择了西瓜的情况下,我们会把葡萄推荐给花伦。
ItemCF算法并不利用物品的内容属性计算物品之间的相似度,它主要通过分析用户的行为记录计算物品之间的相似度。该算法认为,物品A和物品B具有很大的相似度是因为喜欢物品A的用户大都也喜欢物品B。
基于物品的协同过滤算法主要分为两步:
A.对于目标用户及其待评分的物品,根据用户对物品的历史偏好数据,计算物品与其他已评分物品之间的相似度 Sim(j,i),找到与物品相似度的物品合集N(u);
B. 根据所有物品 N(u) 的评分情况,选出N(u)中目标用户可能喜欢的且没有观看过的推荐给目标用户并预测评分。
适用性
适用于物品数明显小于用户数的场合; 长尾物品丰富,用户个性化需求强烈的领域。
U-CF与I-CF比较

1.3 基于模型的协同过滤算法
1.3.1 基于隐语义模型的协同过滤算法(LFM)
主要用于:填充用户打分矩阵的缺失值
思路来源:应该有一些隐藏的因素(不一定是人可以理解的)影响用户的评分,找到隐藏因子,可以对U和I进行关联;假定隐藏因子的个数小于U和I的数目,,因为如果每个User都关联一个独立的隐藏因子,那就没法预测了;
其实是使用ALS(交替最小二乘法)
隐语义模型的进一步优化(例如y=kx+b比y=kx拥有更好的拟合能力)
离线计算的空间复杂度
基于邻域的方法需要维护一张离线的相关表。在离线计算相关表的过程中,如果用户/物品数很多,将会占据很大的内存。而LFM在建模过程中,可以很好地节省离线计算的内存。
离线计算的时间复杂度
在一般情况下,LFM的时间复杂度要稍微高于UserCF和ItemCF,这主要是因为该算法需要多次迭代。但总体上,这两种算法在时间复杂度上没有质的差别。
在线实时推荐
UserCF和ItemCF在线服务算法需要将相关表缓存在内存中,然后可以在线进行实时的预测。LFM在给用户生成推荐列表时,需要计算用户对所有物品的兴趣权重,然后排名,不太适合用于物品数非常庞大的系统,如果要用,我们也需要一个比较快的算法给用户先计算一个比较小的候选列表,然后再用LFM重新排名。另一方面,LFM在生成一个用户推荐列表时速度太慢,因此不能在线实时计算,而需要离线将所有用户的推荐结果事先计算好存储在数据库中。因此,LFM不能进行在线实时推荐,也就是说,当用户有了新的行为后,他的推荐列表不会发生变化。
推荐解释
ItemCF算法支持很好的推荐解释,它可以利用用户的历史行为解释推荐结果。但LFM无法提供这样的解释,它计算出的隐类虽然在语义上确实代表了一类兴趣和物品,却很难用自然语言描述并生成解释展现给用户。
1.3.2 基于朴素贝叶斯分离的推荐算法
贝叶斯
适用性
朴素贝叶斯分类实现起来比较简单,准确率高,但是分类的时候需要学习全部样本的信息。因此,朴素贝叶斯分类适用于数据量不大,类别较少的分类问题。
2、基于内容的推荐算法(CB)
2.1 基础CB推荐算法
基础CB推荐算法利用物品的基本信息和用户偏好内容的相似性进行物品推荐。通过分析用户已经浏览过的物品内容,生成用户的偏好内容,然后推荐与用户感兴趣的物品内容相似度高的其他物品。
比如,用户近期浏览过冯小刚导演的电影“非诚勿扰”,主演是葛优;那么如果用户没有看过“私人订制”,则可以推荐给用户。因为这两部电影的导演都是冯小刚,主演都有葛优。
算法流程
算法输入:物品信息,用户行为日志。
算法输出:初始推荐结果。
A.物品表示:每个物品使用特征向量表示;
B. 从用户行为日志中,获取该用户所浏览、收藏、评价、分享的物品集合M,根据物品集合M中物品的特征数据,可以学到用户的内容偏好;
C.保存Top-K个物品到初始推荐结果中。
适用场景
适用于基础CB架构的搭建,尤其是对新上线物品会马上被推荐非常有效,被推荐的机会与老的物品是相同的。
2.2 基于TF-IDF的CB推荐算法
TF-IDF在CB推荐算法中的应用于在CF推荐算法中的应用极为相似,唯一不同的是:
CF推荐算法中的KNN是根据用户对物品的评分来计算物品间相似度的,而TF-IDF在CB推荐算法是根据【物品的词语的TF-ID值构成的向量】来计算相似度的;
TF-IDF是自然语言处理领域中计算文档中词或短语的权值的方法,是词频(Term Frequency, TF)和逆转文档频率(Inverse Document Frequency, IDF)的乘积。
TF指的是某一个给定的词语在该文件中出现的次数,IDF是一个词语普遍重要性的度量;
算法原理
TF-IDF算法基于这样一个假设:若一个词语在目标文档中出现的频率高而在其他文档中出现的频率低,那么这个词语就可以用来区分出目标文档。
算法流程
算法输入:物品信息,用户行为日志。
算法输出:初始推荐结果。
A. 物品表示:向量表示 描述物品的词语的TF-IDF值;
B.使用上面的向量计算物品的相似度,保存Top-K个物品到初始推荐结果中;
C. 从用户行为日志中,获取该用户所浏览、收藏、评价、分享的物品集合M,根据物品集合M中物品的特征数据,可以学到用户的内容偏好;
例如:
2.3 基于KNN的CB推荐算法
KNN在CB推荐算法中的应用于在CF推荐算法中的应用极为相似,唯一不同的是:
CF推荐算法中的KNN是根据用户对物品的评分来计算物品间相似度的,而CB推荐算法中KNN是根据物品画像来计算相似度的;
所以对于后者来说,如何通过物品画像来计算物品间的相似度是算法中的关键步骤。
相似度的计算可以使用余弦相似度或Pearson相关系数的计算方法。
2.4 基于Rocchio的CB推荐算法
2.5 基于决策树的CB推荐算法
基于决策树的推荐算法在训练阶段会生成一个显示的决策模型。决策树可以通过训练数据构建并有效判断一个新的物品是否可能受到欢迎。当物品的特征属性较少时,采用决策树算法能够取得不错的效果,另外,决策树学习的思想也比较容易被理解,在物品推荐时的可解释性较好。
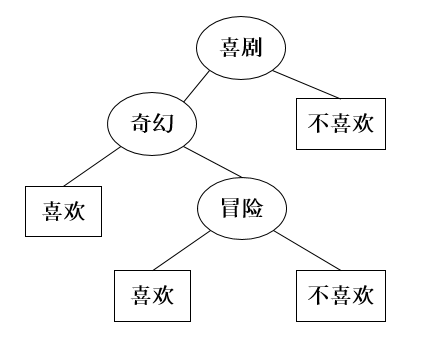
2.6 基于线性分类的CB推荐算法
将基于内容的物品推荐问题视为分类问题时,可以采用多种机器学习方法。从一个更抽象的角度上看,大部分学习方法致力于找到一个可以准确区分用户喜欢和不喜欢的物品的线性分类模型系数。
将物品数据用n维特征向量来表示,线性分类器试图在给定的物品特征空间中找到一个能够将物品正确分类的平面,一类点尽可能在平面的某一边(喜欢),另一类在平面的另一边(不喜欢)。
2.7 基于朴素贝叶斯的CB推荐算法
3、 基于知识的推荐算法
3.1 概述
基于知识(Knowledge-based, KB)的推荐算法,是区别于基于CB和基于CF的常见推荐方法。如果说CB和CF像通用搜索引擎的话,KB好比某个领域的垂直搜索引擎,可以提供该领域的特殊需求,包括专业性的优质特征,帮助提高搜索引擎在特定领域的服务。
基于知识的推荐,也更容易满足主观个性化需求。例如,对于VIP用户,如果配置好了偏好,就可以为其提供更加精准的推荐服务。
3.2 约束知识与约束推荐算法
如今网上购物所能涵盖的物品越来越丰富,人们逐渐发现推荐系统的CF和CB推荐算法并不能很好地适应某些特殊物品的推荐需求。例如,更新换代非常快的而人们又通常不会经常更换的电子产品。对于这些产品来说,其各方面的性能参数在几年间就会有很大变化,代表历史偏好的用户画像并不能很好地反映用户当前的购买需求,于是就需要推荐系统将用户当前的需求作为重要信息参考源。
人们发现可以利用物品的参数特征等属性形成约束知识,再将用户对物品的特定刻画为约束条件,然后经过对物品集合的约束满足问题的求解,就可以得到用户所期望的物品了。
创建推荐任务
推荐任务是以元组(R,I)的形式表示出来,其中用集合 R 表示目标用户对物品的特定需求,即对物品的约束条件,用集合 I 表示一个物品集合。推荐的任务就是从集合 I 中确定出能够满足集合 R 要求的物品。
3.3 关联知识与关联推荐算法
算法原理
关联知识以关联规则为表现形式,用以描述数据库中数据之间关联性的知识。在推荐系统领域,可以通过对用户画像中关联规则的挖掘分析来分析用户的习惯,发现物品之间的关联性,并利用这种关联性指导系统做出推荐。
算法流程
算法输入:n个用户画像。
算法输出:针对目标用户u的Top-N推荐列表。
A. 从系统中的n个用户画像中挖掘出所有的强关联规则,建立集合以表示目标用户u尚未观看但极有可能感兴趣的物品。
B.再次使用置信度对集合中的物品进行高低排序。
C.取出排序列表中的前N个物品构成Top-N推荐列表。
适用场景
由于对系统中全体用户的画像进行规则关联挖掘意义不明显且计算量大,所以基于关联规则的推荐算法常与CF推荐算法混合使用。在这类混合方案中,使用了CF推荐算法中的最近邻算法将用户画像数目n限定在目标用户的最邻近范围内,使得关联规则挖掘算法处理的数据规模被有针对性地限定在一定范围内。
4、 混合推荐算法
各种推荐方法都有优缺点,为了扬长补短,在实际中常常采用混合推荐。
研究和应用最多的是内容推荐和协同过滤推荐的组合。最简单的做法就是分别用基于内容的方法和协同过滤推荐方法去产生一个推荐预测结果,然后用某方法组合其结果。
组合推荐一个最重要原则就是通过组合后要能避免或弥补各自推荐技术的弱点。
4.1 加权式
加权多种推荐技术结果:

4.2 切换式
根据问题背景和实际情况或要求决定变换采用不同的推荐技术。

4.3 混杂式
同时采用多种推荐技术给出多种推荐结果为用户提供参考。

4.4 特征组合


4.5 特征补充
一种技术产生附加的特征信息嵌入到另一种推荐技术的特征输入中。
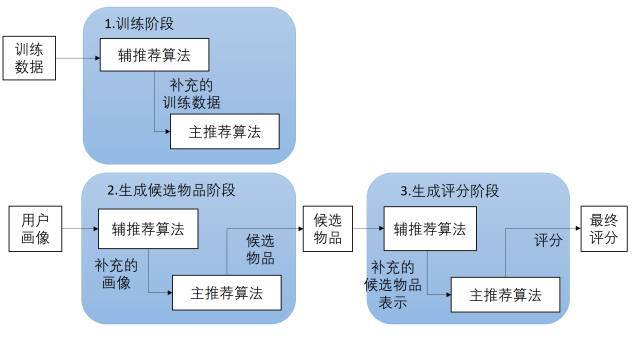
4.6 级联式
