1. 信息的存储
大多数计算机使用 8 位的块,或者字节,作为最小的寻址内存单位,而非访问内存中单独的位,机器级程序将内存视为一个非常大的字节数组,称为 虚拟内存 ,内存的每个字节都用一个唯一的数字标识,称为它的 地址 。以 C 语言的指针为例,指针使用时指向某一个存储块的首字节的 虚拟地址 ,C 编译器将指针和其类型信息结合起来,这样即可以根据指针的类型,生成不同的机器级代码来访问存储在指针所指向位置处的值。每个程序对象可以简单视为一个字节块,而程序本身就是一个字节序列。
1.1 十六进制表示法
一个字节由 8 位组成。用二进制表示即 00000000 ~ 11111111 。十进制表示为 0 ~ 255 。由于两者表示要么过于冗余,要么转换不遍,因此通常使用十六进制来表示一个字节。这几种进制的转换在此就不多说了。
1.2 字数据大小
每台计算机都会有一个字长(此处字长非字节长度),指明 指针数据的标称大小(nominal size),因为虚拟地址是以这样的一个字来进行编码的,所以字长决定的最重要的一个系统参数即是虚拟地址空间的最大大小。 对于一个字长为 w 位的机器而言,虚拟地址的范围为 0 ~ (2 ^w )- 1 ,程序最多访问 2 ^ w 个字节。以 32 位机器为例,32位字长限制虚拟地址空间为 (2 ^32) -1 ,程序最多访问 2 ^ 32 个字节,大约为 4 x 10^9 字节,即4 GB ( 根据 2 ^ 10 (1024) 约等于 10 ^ 3 (1000) ,可以得到 2 ^ 32 = 4 * 2^30 = 4 * 10 ^ 9 ) 。64位机器的限制虚拟地址空间为 16 EB。大约为 1.84 x 10 ^9 。
1.3 寻址和字节顺序
对于跨越多个字节的对象,我们必须建立两个规则:这个对象的地址是什么以及在内存中如何排列这些字节。在几乎所有的机器上,多字节对象都被存储为连续的字节序列,对象的地址为这个字节序列中最小的字节地址。以 int 类型为例,假定int 大小为32 位,有变量 int x = 0x01234567 。若 x 的地址为 0x100 ,则 x 的 4 个字节将被存储在 0x100 , 0x101 , 0x102, 0x103 的位置,此时 4个字节的值分别为 0x01, 0x23, 0x45, 0x67,那么在内存中的排列顺序有如下两种情况,

- 大端法:最高有效字节放在最前面的方式称为大端法,即将一个数字的最高位字节放在最小的字节地址。
- 小端法:最低有效字节放在最前面的方式称为小端法,即将一个数字的最低位字节放在最小的字节地址。
以上面的 x 为例,x 的最高位字节是 0x01 ,将其放在最小的字节地址即 0x100。x 的最低位字节为 0x67 ,将其放在最小的字节地址 0x100 。即大小端对应高低位字节。对于我们来说,机器的字节顺序是完全不可见的,我们大部分情况下也无需关心其字节顺序,但是在不同类型的机器之间通过网络传递二进制数据的时候,如小端法机器传送数据给大端法机器时,接受方接收到的字节序会变成反序,为了避免这种问题的产生,发送方和接收方都需要遵循一个网络规则,发送方将二进制数据转换成网络标准,接收方再将这个网络标准的字节序转换成自己的字节序。此外,我们在阅读机器级代码的时候,可能会出现如下的情况:
![]()
暂时忽略这条指令的意义,可以看到左边6个字节分别为 01 05 43 0b 20 00 ,而右边的指令中的地址为 0x200b43,可以看到从左边的第三个字节开始,43 0b 20 是右边指令地址的倒序,因此在阅读这种机器级代码的时候,也需要注意字节序的问题。此外还存在一种情况。如下图所示。

我们可以看到, show_bytes 这个函数可以打印出 start 指针指向的地址开始的 len 个字节内容,且不受字节序的影响,那么它是如何做到的呢?在 show_int 函数中,可以看到它将 参数 x 的地址强制类型转换为了 byte_pointer , 即 unsigned char * 。通过强制类型转换的 start 指针指向的仍是 x 的最低字节地址,但是其类型改变了,通过其类型编译器会认为该指针指向的对象大小为 1 个字节,此时将该指针进行 ++ 操作可以得到顺延下一个字节的内容,从而得到对应的整个对象的字节序列中每个字节的内容而不受字节序影响。
1.4 字符串
在C语言中,字符串被编码为一个以 null (其值为0 )字符结尾的字符数组。每个字符都有某个标准编码来表示,最常见的则是 ASCII 字符码。假如我们调用 show_bytes("12345", 6),那么会输出 31 32 33 34 35 00 。可以看到最后打印出了一个终止符,所以通常 C 字符串的长度为实际字符串长度 + 1。 在C 标准库中的 strlen 函数可以传入一个字符串得出其长度,这里的长度即是实际长度,不包含终止符。
2. 整数表示
在本章节中,介绍了编码整数的两种不同的方式,一种只能表示非负数,另一种则能够表示负数,正数和零。接下来逐一进行介绍。
2.1 整型数据类型
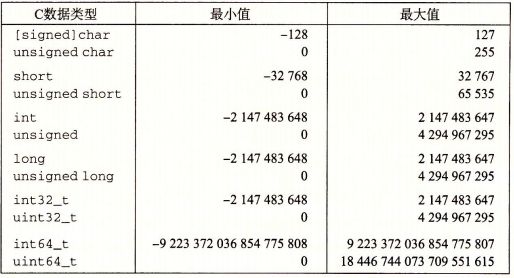
C语言中,整数有多种数据类型,如下图所示,此外可以通过加上 unsigned 符号来限定该数据类型为非负数。这些数据类型有的是根据机器的字长(32位和64位)决定其实际最大值和最小值的范围。我们可以看到,图中最小值和最大值的取值范围是不对称的,负数的取值范围比正数大一,当我们考虑如何表现负数时,会看到为什么会这样。
关于无符号整数的编码,其实与普通的十进制正数转换成二进制没有什么区别,假设字长 w = 32 位,转换后大于 32 位的数字将被舍去。这里主要介绍一下关于有符号数字的编码,通常计算机使用的编码表示方式为 补码 ,在这个表示方式中,将字的最高有效位(即符号位)表示为负权,权重为 - 2^(w-1) ,当 w 位的值为 1 时表示为负数,反之为正数。以 -1 为例,-1 的补码为1111 1111 .... .... 1111 ,即 -2^31 + 2^30 + ... + 2^0 = -1 ,通常我们看到一个负数想要直接将其使用补码表示还是有些不方便的,因此我们可以先使用原码表示,所谓原码和普通的十进制数转二进制数没有区别,只不过最高位用来表示符号位,然后再求其反码,即符号位不变,其余位取反加 1,就可以得到这个负数的补码了,还是以 -1 举例, -1 的原码为 1000 0000 .... 0001 ,其反码的值为 1111 1111 .... 1111 ,与 -1 的补码值是相同的。而正数的补码为其本身,不需要做这种转换。
那么为什么要使用补码这种表示方式呢,首先,二进制补码可以使正负数相加时仍然采用正常加法的逻辑,不需要做特殊的处理,此外,如果不采用补码表示,采用原码的表示方法,那么会出现几个问题,正负零的存在,以及提高了减法的计算复杂度,而补码可以十分简单的计算正负数相加,只需求出两者的补码对其进行加法,更多关于补码的解释可以参考 stackoverflow 。
PS: 为什么正负数补码相加会得到正确的结果,这里个人的见解是:由于补码最高位为负权,而正数与负数补码相加相当于正数去抵消这个负权。比如 -16 的补码为 1111 .... 1111 0000,加上正数 1,由于正数的补码为本身,所以等价于 -16 + 1 == (-2^31 + 2^30 + ... + 2^4 ) + 2^ 0 ,相当于多了一个 2^0 的正权去抵消其最高位的负权。
2.2 有符号数和无符号数之间的转换
C语言允许各种不同的数字类型之间进行强制类型转换, 如 int x= -1 ; unsigned y = (unsigned) x ; 此时会将 x 的值强制类型转换成 unsigned 类型然后赋值给 y ,那么此时 y 的值是多少呢?可以通过打印两者的十六进制值来看有什么区别。下面为 test.c 的代码:
int main()
{
int x = -1;
unsigned y = (unsigned) x;
printf("%x \n", x);
printf("%x \n", x);
return 0;
}
此处为编译后可执行文件的输出结果:
ffffffff
ffffffff
可以看到, x 和 y 的十六进制值是相同的,这也说明了,强制类型转换并不会改变数据底层的位表示,只是改变了解释位模式的方式。我们可以利用 printf 的指示符进一步验证这个结果,使用 %d (有符号十进制), %u (无符号十进制), 来打印 x 和 y 的值。以下是代码:
int main()
{
int x = 1;
unsigned y = (unsigned) x;
printf("x format d = %d , format u = %u \n", x, x);
printf("y format d = %d , format u = %u \n", y, y);
return 0;
}
这是编译后可执行文件的对应输出:
x format d = -1 , format u = 4294967295
y format d = -1 , format u = 4294967295
我们可以看到,我们使用指示符控制了解释这些位的方式,得到的结果是一致的。
2.3 整数运算
关于整数的运算,主要就是加减乘除四种运算,补码的加减乘除都比较简单明了,这里主要说一下除法的舍入问题,首先,我们先确认下 C 语言中的舍入方式,在 C 语言中,浮点数被赋值给整数时,小数位总是被舍去,如
float f = 1.5;
int x = f ;
printf("%d \n ", x);
输出的结果为:
1
当 f 为负数时结果又是如何呢 ?
float f = -1.5 ;
int x = f;
printf("%d \n", x);
输出的结果为:
-1
因此我们可以认为,C语言的舍入方式为向零舍入。接下来看一下除法的舍入问题。此处先以除以 2 的幂的无符号除法为例,

上图表示 12340 / 2^k 的时候二进制与对应的十进制的表示,此时的舍入是完全没有问题的。接下来看下除以 2 的幂的有符号除法。

当k = 4 的时候,-12340 / 2^ 4 == -771.25,此时的正确舍入值应该为 -771,但是其却舍入成了 -772。这是因为,如果我们单纯使用右移来进行除法的时候,其舍入方式为向下舍入,即总是往更小值的方向舍入,在没有小数位的情况下是正确的,但是如果有小数位的时候,如 -771.25 舍入为 -772, 771.25 舍入为 771。而C语言的舍入方式为向零舍入,即总是往靠近零的值舍入,如 771.25 舍入为 771, -771.25 舍入为 -771。那么如何实现这种舍入方式呢。当被除数为负数时,我们可以通过加上一个偏置值来纠正这种不正确的舍入方式。
我们可以观察一下上图的有符号除法例子,可以发现,当右移的 k 位单独拿出来,不为 0 的时候,会导致舍入结果不正确,这是因为,k 位的值不为 0 的时候,表示该结果有小数,所以可以通过 (x + (1 << k) - 1) >> k 得到正确的结果, (1 << k) - 1 可以获得 k 个 1,x 加上 k 个 1 可以使舍去的 k 位不为 0 时产生进位,x >> k 的结果加一,从而使舍入正确。
关于整数的表示和运算,个人觉得有几个需要关注的点,一是溢出问题,由于使用有限的位来表示整数,所以当数字过大的时候可能会产生溢出,溢出的位会被舍去,但是有符号数的溢出可能会使符号位被置反,如 0111 1111 .... 1111 + 1 = 1000 0000 .... 0000,0111 1111 .... 1111 为 INT_MAX , INT_MAX + 1 会得到 INT_MIN。此外,无符号数与有符号数进行比较的时候,会使有符号数强制转换为无符号数,如果有以下循环代码:
for(size_t i = 10; i >= 0 ; i--);
由于 i 为无符号数,当 i == 0 的时候,判断还会继续循环下去, 0 - 1 = -1 , -1 的补码表示为 1111 1111 .... 1111 , 刚好是无符号数的最大值,会导致死循环。因此也需要注意一切与无符号类型数据的运算,以及强制类型转换可能出现的问题。
3. 浮点数
终于来到了这一章的重点内容之一(其实感觉这本书哪里都挺重要的),这里主要介绍浮点数是如何表示的,并且介绍浮点数舍入的问题(和上面讲到的舍入不大一样),浮点数的表示及其运算标准称为 IEEE754 标准,初看可能会让你觉得有些晦涩难懂,但是理解之后会觉得设计的十分巧妙。
3.1 定点表示法
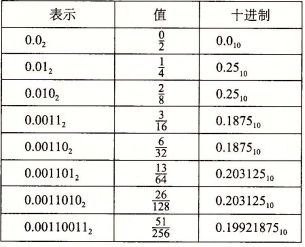
首先让我们先看下十进制的浮点数是如何表示的,浮点数的定义与小数点息息相关,定义在小数点左边的数字的权是 10 的正幂,右边的数字为 10 的负幂,如 12.34 表示 1 * 10^ 1 + 2 * 10^0 + 3 * 10 ^-1 + 4 * 10 ^ -2 = 12又34/100,同理可以得到二进制的浮点数表示,即定义在小数点左边的数字的权是 2 的正幂,右边的数字为 2 的负幂,如 101.11 = 1 * 2^2 + 0 * 2^1 + 1 * 2^0 + 1 * 2^-1 + 1 * 2^-2 。这种浮点数的表示方法是有缺陷的,无法精准的表示特定的数字,以 1/5 为例,可以用 十进制数字 0.2 表示,但是我们无法用二进制数字表示它,只能近似的表示它,通过增加二进制表示的长度可以提升表示的精度。如下图所示。
3.2 IEEE754标准
在前面谈到的定点表示法不能有效的表示一个比较大的数字,例如 5 x 2^100 是用 101 后面跟随 100 个零的位模式,我们希望能够通过给定 x 和 y 的值来表示如 x * 2 ^y 的数字。IEEE754 标准使用 V = ( - 1)^S * M * 2^E 的形式来表示一个数。
- 符号(Sign): S 决定这个数是负数(S = 1 )还是正数 (S = 0), 对于数值为 0 的符号位做特殊解释。
- 尾数(Significand): M 是一个二进制小数,范围为 1 ~ 2 - e , 或者是 0 ~ 1 - e 。
- 阶码(Exponent): E 的作用是对浮点数进行加权,这个权重是 2 的 E 次幂(E 可能为负数)。
通过将浮点数的位划分为三个字段,分别对这些值进行编码:
- 一个单独的符号位 S 。
- k 位的阶码字段 ,exp = e(0) e(1) e(2) ... e(k-1) ,exp 用来编码阶码 E。
- n 位的小数字段 , frac = f(n-1) ... f(1) f(0) ,frac 用来编码尾数 M。
下图是该标准下封装到字中的两种最常见的格式。

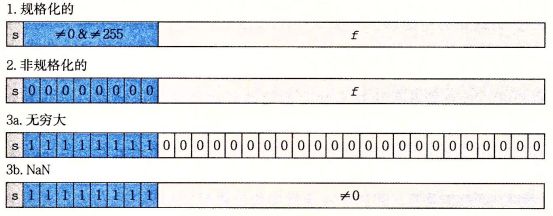
此外,根据阶码值(exp),被编码的值可以分为下图几种情况(阶码值全为 0 ,阶码值全为 1 , 阶码值不全为 0 也不全为 1):
接下来对这几种格式进行一一介绍~:
- 规格化浮点数 : 这是最普遍的情况,当 exp 的值不全为 0 也不全为 1 时,就属于这种情况,这种情况下,阶码值 E = e - bias ,其中 e 为无符号数,即 exp 的值,而 bias 是一个 2^(k-1) - 1 的偏置值(单精度为 127,双精度为 1023),而小数字段 frac 被解释为描述小数值 f ,其中 0 <= f < 1,其二进制表示为 0.f(n-1)...f(1)f(0) 的数字,也就是二进制小数点在最高有效位的左边的形式。尾数定义为 M = 1 + f 。 有时候这种方式也叫做 隐含 1 开头的表示(implied leading 1),因为这种定义我们可以把 M 看成一个二进制表示为 1.f(n-1) ... f(1)f(0) 的数字。既然我们总是能调整阶码 E ,使得尾数 M 在范围 1 <= M < 2 之中(假设没有溢出),那么这样可以节约一个位,因为第一位总是为 1 。
- 非规格化浮点数 : 当 exp 的值全为 0 的时候,所表示的浮点数为非规格化类型,E = 1 - bias ,而尾数的值为 M = f 。不含开头的 1 。非规格化有两种用途,首先它提供了表示 0 的方法,因为规格化数使得 M >= 1,所以不能表示 0 ,另外非规格化数另一个功能则是表示那些非常接近于 0.0 的数,他们提供了一种属性,称为逐渐溢出,其中,可能的数值均匀分布接近于 0.0 。
- 特殊值 : 最后一类数值是指当阶码全为 1 的时候出现的。当小数域全为 0 时,表示为无穷大/小,当我们将两个非常大的数相乘时,或者除以零时,无穷能够表示溢出的结果。当小数域为非 0 时,结果为 NaN(Not a Number),一些运算的结果不能为实数或者无穷时,会返回 NaN,比如 根号 -1 ,或者 无穷减无穷。此外,在某些应用中也可以用来表示未初始化的数值。
首先,通过一个字长为 8 位的例子,来看一下IEEE754标准实际上使用时是如何表示的 :
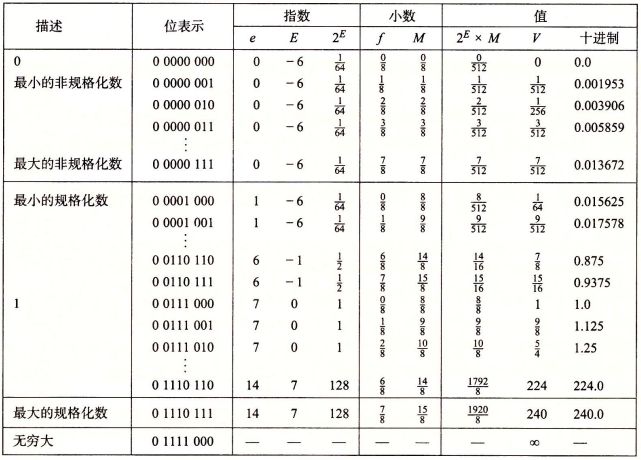
上图为展示了假定 w = 8 的字长,k = 4 的阶码位以及 n = 3 的小数位。偏移量为 2 ^ ( k -1 ) -1 = (2 ^ 3) - 1 = 7。图中分别展示了非规格化数,规格化数以及特殊值是如何编码的,以及如何结合在一起表示 V = (2^E) * M。我们可以看到,从最大非规格化数到最小规格化数,其值的转变十分平滑,从 7/512 到 8/512 。这得益于非规格化数的 E 定义为 1 - bias ,最大的非规格化数的阶码值 E 与最小的规格化数的阶码值 E 是相等的,两者唯一的区别在于 M 值,规格化数尾数 M = 1 + f ,而非规格化的尾数 M = f ,因为非规格化值是用于表示 [0, 1] 区间的小数的,当 f 达到最大值时, f 接近于 1 ,此时最大的非规格化数再进一位,小数 M 只能表示为 1 ,因为此时限制于 f 的位数,没有比 f 大又比 1 小的小数值 ,进位后转换成了规格化数,此时 f = 0 , 在阶码值 E 相等的情况下,让规格化的 M = 1 + f 恰好可以使两者进行平滑的转换。
假如我们使非规格化数的 E = 0 - bias = -7 ,那么会导致最大非规格化数和最小规格化数的粒度过大,两者的值分别为 7/1024 和 8/512 。这种定义可以弥补非规格化数的尾数没有隐含的 1 。通过上述的例子,我们可以发现 ,假如我们把上述的例子按无符号整数表示的话,会发现它的值是有序上升的,这不是偶然的,IEEE 格式如此设计就是为了浮点数能够使用整数排序函数进行排序。
通过练习将整数值转换为浮点数值形式对理解浮点数很有用,以 12345(十进制) 为例,其二进制表示为 1100 0000 1110 01 . 0 ,通过将小数点左移 13 位得到 1.1000000111001 * 2^13 ,我们丢弃开头的 1 (这里的 1 就是规格化数隐含的 1),构造小数字段,当 f 不足 23 位的时候,往后填充 0 ,即 M = 1 + f = 1 + 1000 0001 1100 1000 0000 000 ,当 f 大于 23 位的时候,f 多出的位会被舍弃(这里可以看出浮点数的两个性质,以 int 类型和 float 类型举例,当 int 值 大于 2^24 的时候,int 转换成 float 两者很有可能值会不相等,因为多出的部分被舍弃了,二是 float 可以表示的数值远远大于 int 类型,V = (-1 ^ S) * M * 2^E ,E 最高可以等于 127 ,float 的最大值为 (2^127) * (1 + f),而 int 最大值为 (2^31) -1。
3.3 舍入
浮点数的舍入方式有四种,分别是向上舍入,向下舍入,向零舍入,向偶数舍入。下图是几种舍入方式的例子 :

偶数舍入是浮点数默认的舍入方式,可以看到,向偶数舍入时,当小数值为中间值时,会使最低有效数字总为偶数,如 2.5 和 1.5 都舍入为 2 。为什么使用向偶数舍入呢,假设我们采用向上舍入,用这种方法舍入一组数值,会在计算这些值的平均值中引入统计偏差。我们采用这种方式舍入得到的平均值总是比这些数本身的平均值要略高一些,反之向下舍入亦然,向偶数舍入则可以使在 50% 的时间内向上舍入,50% 的时间内向下舍入。
4. 小结
- 计算机将信息编码为位(bit),通常组织成字节序列,有不同的编码方式来表示整数,实数和字符串。不同的计算机模型在编码数字和多字节数据中的字节顺序时使用不同的约定。
- 绝大部分机器使用补码来编码整数。对于浮点数使用 IEEE754 标准来编码。
- 在进行对无符号和有符号整数进行强制类型转换时,底层的位模式是不变的。(浮点数与整数转换则会进行 改变,如 float f = 1.25; int x = f; 此时打印两者的十六进制值,可以分别输出为 f = 92463258 ,x = 1 )
- 由于编码的长度有限,当超出表示范围时,有限长度会引起数值溢出,如 x * x 可能会得到负数。当浮点数非常接近于 0.0 时,转换成 0 时也会产生下溢。
- 使用补码运算 ~x + 1 = -x (不适用于 INT_MIN) 。可以通过 (2^k) - 1 生成一个 k 位的掩码。
- 浮点数不具备结合率,因为可能发生溢出或者舍入,从而失去精度。如(le20 * le20) * le-20 = 正无穷,而 le20 * (le20 * le-20) = le20 。此外也不具备分配性,如 le20 * (le20 - le20) = 0.0 ,而 le20 * le20 - le20 * le20 = NaN。