CVPR2020 | MAL:联合解决目标检测中的定位与分类问题,自动选择最佳anchor
点击上方“AI算法修炼营”,选择“星标”公众号
精选作品,第一时间送达

本文是收录于CVPR2020的工作,其实文章在去年就挂在了网上,整体思路还算不错。具体来说,本文提出Multiple Anchor Learning(MAL),是一种可以自动学习anchor的方法用于解决分类和定位置信度之间的不匹配问题,通过anchor-object匹配来联合优化分类和定位。其中对抗方法获得最优解的方法,可以重点学习。
论文地址:https://arxiv.org/pdf/1912.02252.pdf
代码地址:https://github.com/KevinKecc/MAL
分类和定位是视觉目标检测器的两个最重要的环节。但是,在基于CNN的目标检测器中,这两个模块通常在一组固定的候选(或anchor)边界框下进行优化。这种配置大大限制了联合优化分类和定位的可能性。另外,在基于anchor的目标检测方法中,检测器利用目标与anchor之间的IoU作为分配anchor的标准,每个被分配的anchor独立地监督网络学习,以进行分类与定位。也就是说,分类与定位之间是没有交互的,如果一个检测结果的定位精度较高但分类置信度较低,那么它有可能在NMS操作中被过滤掉。
在本文中,提出了一种Multiple Anchor Learning(MAL)方法,该方法自动选择anchor并共同优化分类和定位两个模块,通过IoU构造了anchor bags并从每个bag中选择分类分数和定位分数同时达到最高的anchor。但是这样的迭代选择过程可能难以优化,为了解决这个问题,本文提出一种selection-depression优化策略,通过对所选的最优的anchor的相应特征增加扰动来反复降低其置信度,保证最终选择的anchor是最优的。实验表明,MAL改善了baseline RetinaNet的性能,与常用的MS-COCO目标检测baseline相比有显着提高。
简介
目标检测算法一般利用目标与anchor之间的IoU作为分配anchor的标准,每个被分配的anchor独立地监督网络学习,以进行分类与定位。因此,分类和定位任务通常是分开独立的,同时,目标检测中的anchor的选取大大限制了联合优化分类和定位的可能性。在训练过程中,如果没有对分类和定位两个任务进行同时优化,则准确定位的目标可能具有较低的分类置信度,并且会被非极大抑制算法(NMS)过滤(请参见图1)。
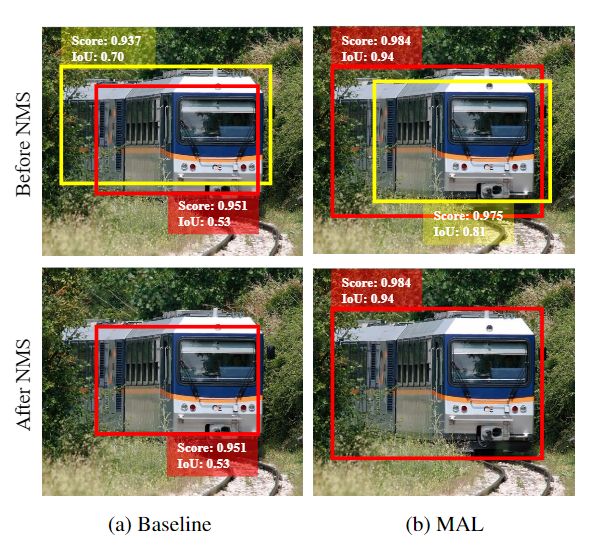
图1 baseline检测器(RetinaNet)和MAL检测器在使用NMS之前和之后对比输出。baseline检测器可能会生成具有低分类分数、高定位分数的IoU的边界框(黄色bbox)或具有高分类分数、低定位分数的IoU的边界框(红色bbox),这会导致进行NMS后出现次优结果。MAL产生具有同时具有较高分类分数和定位分数的边界框,从而在NMS之后获得更好的检测结果。
针对该问题的最新研究包括IoU-Net 和FreeAnchor,但是,在训练过程中仍然使用独立的分类和定位分支进行置信度计算。FreeAnchor根据分类和定位上的联合概率来选择anchor。但是,考虑到问题的非凸性,基于最大似然估计(MLE)的匹配过程并不是最佳的。
在本文中,提出的Multiple Anchor Learning(MAL)可以看作是一种可以自动学习anchor的方法,通过anchor-目标的匹配来联合优化分类和定位。在训练时,根据anchor与目标bbox之间的IoU进行排序,选择IoU位于前面的anchor,用它们构建一个属于该目标的anchor bag,然后MAL通过结合分类与定位分数,评估出每个anchor bag中的positive anchor。在每次迭代过程中,MAL使用所有的positive anchor来优化训练损失,选出分数最高的anchor作为最终的选择。这样一来,分类分数和定位分数就能同时达到最高。
MAL是在多实例学习(MIL)基础上对anchor selection loss进行优化的。但是,常规的MIL的迭代选择过程可能难以优化。在每次迭代中选择分数最高的anchor可能并不会达到最好的结果,比如目标的一部分被错误地定位,但由于分类分数较高,因此总分数也较高。为了解决这个问题,本文还提出一种selection-depression优化策略,通过扰动分数较高的anchor的特征,来反复降低该anchor的置信度,从而保证最终所选择的anchor是最优的。
主要贡献:
(1)提出了一种多锚学习(MAL)方法,通过评估和选择anchor来共同优化用于目标检测的分类和定位模块。
(2)提出了一种selection-depression优化策略,提供了一种优雅且有效的方法来防止MAL在训练期间陷入检测器的次优解决方案。
baseline:RetinaNet
RetinaNet的框架整体是ResNet+FPN+FCN,它使用ResNet作为backbone来提取图像特征,然后从中抽取5层特征层来构建特征金字塔网络(FPN: feature pyramid network),最后接两个独立的全卷积网络(FCN: full convolution network)分别得到物体的类别信息和位置框信息。
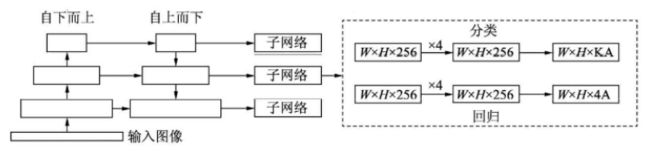
△ RetinaNet框架
对于RetinaNet的网络结构,有以下5个细节:
(1)在Backbone部分,RetinaNet利用ResNet与FPN构建了一个多尺度特征的特征金字塔。
(2)RetinaNet使用了类似于Anchor的预选框,在每一个金字塔层,使用了9个大小不同的预选框。
(3)分类子网络:分类子网络为每一个预选框预测其类别,因此其输出特征大小为KA×W×H, A默认为9, K代表类别数。中间使用全卷积网络与ReLU激活函数,最后利用Sigmoid函数输出预测值。
(4)回归子网络:回归子网络与分类子网络平行,预测每一个预选框的偏移量,最终输出特征大小为4A×W×W。与当前主流工作不同的是,两个子网络没有权重的共享。
(5)Focal Loss:与OHEM等方法不同,Focal Loss在训练时作用到所有的预选框上。对于两个超参数,通常来讲,当γ增大时,α应当适当减小。实验中γ取2、α取0.25时效果最好。
本文方法:Multiple Anchor Learning

图2.MAL的主要思想。在特征金字塔网络中,为每个目标对象bi构造一个anchor bag 。结合网络参数学习(即反向传播),MAL评估了每个anchor在ai中的联合分类和定位置信度。这样的置信度用于anchor选择,并表示了在网络参数变化过程中chor的重要性。
MAL是基于RetinaNet 网络体系结构实现的。MAL通过找到用于分类和定位的anchor/feature的最佳选择来优化RetinaNet。图2是MAL的整体思想,在每次迭代过程中,MAL选出anchor bag中得分较高的anchor以更新模型,更新后的模型为每个anchor评估新的置信度。通过一次次的anchor选择和模型学习以实现最终的优化。
1、 Multiple Anchor Learning(MAL)
在每次学习迭代中,MAL选择anchor bags中的得分高的anchor来更新模型。更新后,模型会评估每个具有新置信度的anchor。模型学习和anchor选择迭代地朝着最终优化的方向执行。具体步骤为:首先为第i个目标构建一个anchor bag Ai ,也就是根据anchor与gt之间的IoU,选出前k个anchor 放入Ai 中。然后在网络参数的学习过程中,MAL为Ai 中的anchor评估出它们的分类和定位置信度,这些置信度用于之后anchor的选择以及说明每个anchor的重要性。这里仅考虑对positive anchor的计算,MAL有如下目标函数:

其中fθ(⋅)和gθ(⋅) 分别计算分类和定位置信度,β是正则化因子,最终是要为目标i选出最优的positive anchor,同时学习网络参数θ∗ 。
在构建Ai 之后,MAL评估出Ai 中每个anchor的分类和定位置信度,利用式(3)选出分数较高的anchor来更新模型参数,再使用更新后的模型重新评估anchor的分类和定位置信度,经过一次次这样的迭代过程,最终选出最优的anchor,以及计算出最优的模型参数。
可以将MAL的目标函数改写为:

其中Ldet和Lcls分别表示定位和分类损失与RetinaNet上一致。
2、 Selection-Depression Optimization

随机梯度下降(SGD)优化方法是一个非凸问题,它可能会导致anchor选择不理想。为了缓解该问题并选择最佳anchor,本文通过扰动相应特征来反复降低选定anchor的置信度。
Anchor Selection
常规的MIL算法倾向于选择得分最高的anchor。但是,在物体检测的情况下,很难从每个anchor bag中选择得分最高的锚点。因此本文提出"All-to-Top-1"anchor 选择策略,在学习过程中,线性降低Ai 中的anchor数量直到降为1。设λ=t/T ,t 和T分别是当前和总的迭代次数,然后设ϕ(λ) 表示排名前几位的anchor的索引,∣ϕ(λ)∣=∣Ai∣∗(1−λ)+1 ,那么式(3)可以被改写为:

沿着这一pipline,MAL利用目标区域内的多个anchor/feature在早期训练epoch中学习检测模型,并在最后一个epoch得到最佳的anchor。
Anchor Depression
受nverted attentionnetwork 的启发,anchor depression模块其实就是给未被选择的anchor更多的机会以参与训练。设feature map和attention map分别是U 和M ,![]() 其中w 是U 的全局平均池化,l 是U 的通道索引。然后通过将较高的值骤降为0,生成新的depressed attention map
其中w 是U 的全局平均池化,l 是U 的通道索引。然后通过将较高的值骤降为0,生成新的depressed attention map ![]() ,那么被扰动后的feature map V 为:
,那么被扰动后的feature map V 为:


其中ψ(λ) 表示有多少个像素被扰动。
3、Optimization Analysis
selection-depression策略其实是一个对抗的过程。selection找出得分较高的anchor从而最小化检测损失Ldet 而depression通过扰动这些被选择的anchor的特征,降低这些anchor的置信度,从而Ldet又再一次上升。如下图所示,在第一个弯道中,MAL选择次优的anchor并且陷入损失函数的局部最小值;然后在第二个弯道中,anchor depression增加了损失,使得局部最小值被"填满",从而MAL能够继续这个优化过程。通过这种方式,在最终收敛的时候,MAL能有更好的机会找到最优解。

实验与结果
数据集:COCO benchmark
评价指标:在所有类别中,AP根据十个不同的IoU阈值(即0.5:0.05:0.95)计算得到。
1、消融实验
首先,在特征激活图上可视化了图5中MAL的有效性。MAL与RetinaNet相比,MAL可以激活物体上的更多部分并在后处理环节抑制更多部分,这表明MAL改进了功能以实现更好的目标检测。



2、对比实验

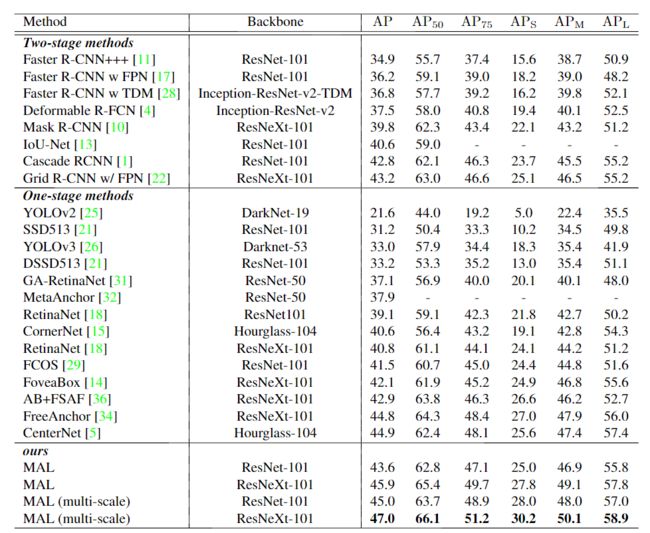
更多实验细节,可以参考原文。
参考
https://blog.csdn.net/qq_30146937/article/details/105725804

