Python函数部分1——函数及函数使用
阅读目录:
一、前言
二、函数定义
三、函数调用 --当做参数传给另外一个函数
四、函数传参
五、函数的参数分为两大类:形参与实参
六、可变长参数 (什么是可变长参数? --在调用函数时,可以传入多个实参)
七、函数调用 --在一个函数定调用另外一个函数
八、函数的递归调用
九、递归的使用 -- 二分法
一、前言
1、什么是函数
1.1、具备某一功能的工具就是程序的函数
1.2、事先准备工具的过程称之为函数的定义
1.3、遇到应用场景"拿来就用"就是函数的调用
2、为什么要用函数
2.1、程序组织结构不清晰,可读性差
2.2、代码冗余(调用一个相同的功能需要写重复的代码)
2.3、程序的可扩展性差(一个登陆接口被使用多次,如果登陆接口修改后,那么需要对所有的登陆接口做修改)
3、怎么用函数
3.1、函数的语法:
def 函数名(参数1,参数2,...):
"""
函数的文档注释
:param 参数1: 参数1的作用
:param 参数2: 参数1的作用
:return: 返回值的描述
"""
代码1
代码2
代码3
....
return 返回值二、函数定义:def name():
def auth(): #定义一个函数,函数内容使用同一缩进,那么函数名为auth,函数的内容为同一缩进的所有值
name_a='sudada'
passwd_a='123'
name=input('pls input you name >>: ')
psd=input('pls input you passwd >>: ')
if name == name_a and psd == passwd_a:
print('login sucessfull')
else:
print('用户名或密码错误')
auth() #调用函数,即函数名加上()小括号2.1、函数的使用必须遵循:先定义,后调用
定义函数:就相当于定义了一个变量,没有事先定义函数,而直接使用,就相当于在引用一个不存在的变量名
在函数定定义阶段只检测语法,不执行代码
def foo():
# xxxxxxx
if定义阶段1:定义一个函数,然后调用这个函数
def foo():
print('from foo')
bar()
foo() #调用阶段定义阶段2:在定义函数的过程中,调用一个函数
def foo():
print('from foo')
bar() #调用的这个函数"bar()"没有按顺序排列,但是在函数调用时只检测语法,不管调用是否成功
def bar():
print('from bar')
foo() #调用阶段
#输出:
>>:from foo
>>:from bar调用阶段:函数名如果不加()的话,那么这个函数只是一个内存地址形式,加()后才会执行这个函数
def foo(): #定义一个函数
print(foo) #如果函数foo不加()的话,那么foo就是一个内存地址形式
#
foo() #函数foo+(),用来执行函数foo 三、函数调用 --一个函数可以当做参数传给另外一个函数
def max2(x,y):
if x > y:
return x
else:
return y
max2(3,2)
res=max2(max2(3,2),4) #函数"max2(3,2)"运行后的值为"3",那么此处就把函数"max2(3,2)"的返回值"3"传给了max2(3,4).
print(res)
>>:4def foo():
print('from foo')
print(foo)
def bar(func): #func=foo
print(func) #打印func就相等于打印函数foo的内存地址
func() #func()就等于执行函数foo()[得到的值是一样的]
bar(foo) #执行函数bar时传参数为"foo(foo为函数),那么func接收到的值就为函数'foo'的内存地址"
>>: #这是执行print(func) 得到的
>>:from foo #这是执行func() 得到的,运行func()就相当于运行了foo()
>>: #这是执行print(foo)得到的
四、函数传参
4.1、无参 (什么时候定义无参函数? 函数内的功能被写死了,函数体的逻辑不依赖于参数传进来的值(也就是不需要传参))
def psy():
print('from pay') #函数内定义的值
def check():
print('from check') #函数内定义的值
def transfer():
print('from transfer') #函数内定义的值
def run():
print(""" #以下全部为函数内定义的值
1 支付
2 查询
3 转账
""")
choic=input('pls input you number >>: ').strip()
if choic == '1':
psy() #调用函数psy
elif choic == '2':
check() #调用函数check
elif choic == '3':
transfer() #调用函数transfer
run() 4.2、有参 (什么时候定义有参函数? 函数代码的逻辑需要外部传参来做判断)
def max2(x,y):
if x > y:
print(x)
else:
print(y)
max2(30,20) #这一步是执行函数,也就是把参数传进了函数内并执行函数,得到值
>>:30 #得到30,因为30比20大4.3、pass 空函数
def login():
pass #返回空值,即即使运行这个函数也不会报错
5、return 函数返回值 函数调用--语句形式
def max2(x,y):
if x > y:
return x
else:
return y
print(max2(3,5)) #这里获取return的返回值
#输出
>>:5return 例子: 函数调用---表达式形式
def max2(x,y):
if x > y:
return x
else:
return y
max2(3,2) #这里取出函数内经过比较之后的值"3",那么函数"max2(3,2)"实际上就为"3"
res=max2(3,2) * 12 #给取出的值定义一个变量.然后对这个值做运算
print(res)
>>:36return 返回值没有类型限制
def foo():
return 1,2,'aaa',{'x':3}
res=foo()
print(res)
>>:(1, 2, 'aaa', {'x': 3}) #返回值的类型是"元组"return 返回值没有个数限制,可以一次返回多个值,用逗号隔开
def foo():
return 2,'aaa',{'x':3}
x,y,z=foo()
print(x,y,z)
>>:2 aaa {'x': 3}函数内 没有return 时,默认返回值为"None"
def foo():
print('---------------> ')
res=foo()
print(res)
>>:--------------->
>>:Nonereturn 注意点:
1、return 会立刻结束函数
2、 函数内可以写多个return,但是只要执行了一个return,那么函数就会结束,并且会把return后面的返回值当做这个本次函数调用的返回值
3、return 返回值没有类型限制
4、return 返回值没有个数限制,可以一次返回多个值,用逗号隔开
5、函数内 没有return 时,默认返回值为"None"
五、函数的参数分为两大类:形参与实参
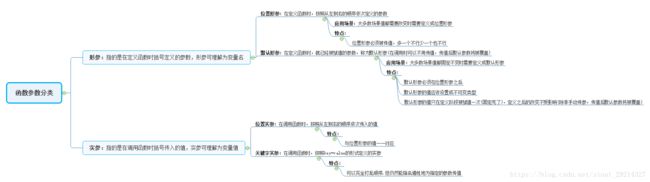
1.形参:指的是在定义函数时括号定义的参数,形参可理解为变量名
形参的种类:
1.位置形参
2.默认形参
2.实参:指的是在调用函数时括号传入的值,实参可理解为变量值
实参的种类:
1.位置实参
2.关键字实参
6.1、位置参数
1.位置实参
2.位置形参
位置形参:在定义函数时,按照从左到右的顺序依次定义的参数
特性:位置形参必须被传值,多一个不行少一个也不行
位置实参:在调用函数时,按照从左到右的顺序依次传入的值
特点:与形参一一对应
def foo(x,y,z) #位置形参必须被传值,多一个或少一个都不行
print(x,y,z)
foo(1,2,3) #位置实参-在调用函数时与形参一一对应缺点:在调用函数时,必须记住形参的位置,必须一一对应,否则容易混乱
6.2、关键字参数
1.关键字实参
关键字实参:在调用函数时,按照key=value的形式定义的实参,称为关键字实参
特点:可以完全打乱顺序,但仍然能指名道姓地为指定的参数传值
def foo(x,y,z)
print(x,y,z)
foo(y=2, x=1, z=3) #把实参指定给某一个形参
6.3、位置参数与关键字参数混合应用 #位置实参必须在关键字实参之前
def foo(x,y,z):
print(x,y,z)
foo(1, y=2, z=3) #位置实参必须在关键字实参之前
>>:1 2 3
foo(y=2,1,z=3) #报错,位置实参必须要在关键字实参的前面
foo(1,y=2,z=3,z=5) #报错,形参不能重复赋值(同一个形参只能被赋值一次)
6.4、默认参数(指的是形参)-在定义函数时,就已经被赋值的参数,称为默认形参(在调用时可以不用传值,传值后默认参数将被覆盖)
def foo(x,y=10): #函数默认指定了参数时
print(x,y)
foo(1) #在定义阶段只为x传值就可以了(y可以不用传值)
>>:1 10
foo(1,100) #当然也可以为y重新传值,这里为y重新传值为100,那么执行函数得到y=100
>>:1 100
6.5、位置形参与默认形参的应用:
1、大多数场景值都固定不变时需要定义成默认形参
def foo(user,passwd,gender='male'): #在这里定义一个默认参数gender='male'
print(user)
print(passwd)
print(gender)
foo('aaa','123')
foo('bbb','123')
foo('ccc','123',female) #那么ccc的性别不为male时,才需要重新定义(大多数场景都为male)2、大多数场景值都需要改变时需要定义成位置形参
3、默认形参必须跟在位置形参的后面
def foo(x=10,y): #默认形参必须跟在位置形参的后面,否则报错
#def foo(x,y=10): #正确写法
print(x)
print(y)
foo(10,11)4、默认形参的值只在定义阶段被赋值一次(固定死了),定义之后的改变不受影响(除非手动传参,传值后默认参数将被覆盖)
m=10
def foo(x,y=m): #在函数的定义阶段时y=m,那么y就被赋值了一次
print(x)
print(y)
m=111111111111 #m=11111111111111时,y的值不会改变,因为y只能被赋值一次
foo(1) #如果在调用函数的时候传值,那么默认参数将会被替换
>>:1
>>:105、默认形参的值应该设置成不可变类型
def func(name,hobby,l=None): #这里 l=None,通过判断用户是否传值来定义hobby
if l is None: #如果传值的话,那么就把对应的值加到hobby里面
l=[]
l.append(hobby)
print(name,l)
func('sudada','w') #定义一个爱好,那么就保存一个爱好
func('sudada','read',['aa','bbb','ccc']) #定义一个爱好后,在追加多个爱好,那么所有的爱好都将被保存
>>:sudada ['w']
>>:sudada ['aa', 'bbb', 'ccc']
六、可变长参数 (什么是可变长参数? --在调用函数时,可以传入多个实参)
而实参的两种形式:1 位置实参 2 关键字实参
所以对应的,形参也必须对应两种解决方案,专门用于接收溢出位置实参和溢出的关键字实参
6.1、* 表示:接收溢出的位置实参,并存成元组的形式,然后赋值给*后面跟的那个变量名。
用法1:在形参中用*
def foo(x,y,*z): *=(3, 4, 5),*会把值赋值给z,那么z=(3, 4, 5)
print(x,y)
print(z)
foo(1,2,3,4,5)
>>:1 2
>>:(3, 4, 5) # z的值为(3, 4, 5)用法2:在实参中用* 打散<==>把*号内的值都转换成位置实参
def foo(x,y,*z):
print(x,y)
print(z)
foo(1,2,*(3,4,5,6)) #foo(1,2,*(3,4,5,6))打散后foo(1,2,3,4,5,6)
>>:1 2 #x y 的值分别为:1 2
>>:(3, 4, 5, 6) #z 的值为(3, 4, 5, 6)
foo(1,2,*'hello') #foo(1,2,*'hello')打散后foo(1,2,'h','e','l','l','o')
>>:1 2 #x y 的值分别为:1 2
>>:('h', 'e', 'l', 'l', 'o') #z 的值为('h', 'e', 'l', 'l', 'o') 注意点:*号在实参时,不管是什么样的类型都需要打散然后在处理(如下例子)
def foo(x,y)
print(x)
print(y)
foo(1,*(2,3,4,5)) #打散后为foo(1,2,3,4,5),因为形参只有x,y,而实参有1,2,3,4,5,传入的值太多报错
foo(1,(2,3,4,5)) #这样就没毛病,1是一个参数,(2,3,4,5)是一个参数
小应用:求和函数
def my_sum(*args):
res=0
for n in args:
# res=res+n
res+=n
return res
res1=my_sum(1,2,3,4,5)
print(res1)
>>:15
6.2、**表示:接收溢出关键字实参 以 {key:value} 的形式
用法1:在形参中用**
def foo(x,y,**z):
print(x)
print(y)
print(z)
foo(1,2,a=1,b=2,c=3,d=4) #1赋值给x,2赋值给y,"a=1,b=2,c=3,d=4"赋值给**
>>:1 #x=1
>>:2 #y=2
>>:{'a': 1, 'b': 2, 'c': 3, 'd': 4} #由于"a=1,b=2,c=3,d=4"赋值给**,那么z={'a': 1, 'b': 2, 'c': 3, 'd': 4}用法2:在实参中用**
def foo(x,y,**z):
print(x)
print(y)
print(z)
foo(1,2,**{'a':1,'b':2,'c':3,'d':4}) #1赋值给x,2赋值给y,{'a':1,'b':2,'c':3,'d':4}赋值给**
>>:1 #x=1
>>:2 #y=2
>>:{'a': 1, 'b': 2, 'c': 3, 'd': 4} #z={'a': 1, 'b': 2, 'c': 3, 'd': 4}
foo(1,**{'a':1,'b':2,'c':3,'d':4},y=5) #打散后得到foo(1,a=1,b=2,c=3,d=4,y=5),其中1赋值给x,y=5,剩下的值都赋值给**
>>:1 #x=1
>>:5 #y=2
>>:{'a': 1, 'b': 2, 'c': 3, 'd': 4} #z={'a': 1, 'b': 2, 'c': 3, 'd': 4}
小例子:把字典d的值一次传给x,y,z
def foo(x,y,z):
print(x)
print(y)
print(z)
d={'x':1,'y':2,'z':3}
foo(**d) #打散后foo(x=1,y=2,z=3) 相当于: foo(**{'x':1,'y':2,'z':3})
>>:1
>>:2
>>:36.3、*(接收溢出的位置实参)与**(接收溢出的关键字实参)的混合用法:
def foo(*x,**y):
print(x)
print(y)
foo(1,2,3,4,5,a=111,b=222,c=333) #1,2,3,4,5转换成元组的形式赋值给了x,a=111,b=222,c=333被转换成字典的形式赋值给了y
>>:(1, 2, 3, 4, 5) #x=(1, 2, 3, 4, 5)
>>:{'a': 111, 'b': 222, 'c': 333} #y={'a': 111, 'b': 222, 'c': 333}小例子: 通过给wrapper函数传参,并把传参的值转嫁与函数wrapper内的index函数。
wrapper函数的格式为:def wrapper(*args,**kwargs):
wrapper内部函数index想要原封不动的接收到wrapper函数的参数形式,index函数的格式也得为:index(*args,**kwargs):
def index(name,sex):
print('welcome %s age is %s' %(name,sex))
def wrapper(*args,**kwargs): #args=(1,2,3),kwargs={'a':1,'b':2}
index(*args,**kwargs) #index(1,2,3,a=1,b=2)
wrapper((1,2,3),{'a':1,'b':2}) #给函数wrapper传参,原封不动的给了函数index,就相当于给函数index传参
升级版:args表示:接收溢出的位置实参,kwargs表示:接收溢出的关键字实参
def index(name,gender): #位置形参有2个值
print('welecom %s gender is %s' %(name,gender))
def wrapper(*args,**kwargs): #wrapper函数可以接受任意值 #args=('alex','male') kwargs={}
index(*args,**kwargs) #index接受wrapper函数的值 #index(*('alex','male'),**{}) #index('alex','male')
wrapper('alex','male')
>>:welecom alex gender is male #得到的值就是wrapper函数传参的值。wrapper函数传参时必须遵循index函数的格式七、函数调用
7.1、函数的嵌套调用(在一个函数定调用另外一个函数) --例子:比较三个数的大小
def max2(x,y): #比较2个数大小的函数
if x > y:
return x
else:
return y
def max3(x,y,m): #比较3个数大小的函数
res1=max2(x,y) #在max3函数内调用函数max2
res2=max2(res1,m)
return res2
print(max3(111,45,99))
>>:1117.2、函数的嵌套定义(在一个函数内定义另外一个函数)
def func1():
print('from func1')
def func2(): #在函数func1内定义函数func2
print('from func2')
print(func2)
func2()
func1()
>>:from func1 #调用函数func1
>>:.func2 at 0x000002410F5FA8C8> #函数func2的内存地址
>>:from func2 #调用函数func2 小例子:比较3个数的大小
def max(x,y):
if x > y:
return x
else:
return y
def max2(x,y,z):
res1=max(x,y)
res2=max(res1,z)
return res2
rrr=max2(1,222,33)
print(rrr)
>>>:222
八、函数的递归调用
指的是在调用一个函数的过程,又直接或者间接地调用该函数本身,称之为函数的递归调用。
递归的本质就是一个重复的过程,但是每进入下一次递归调用时,问题的规模都应该有所减少。
8.1、递归的2个阶段:
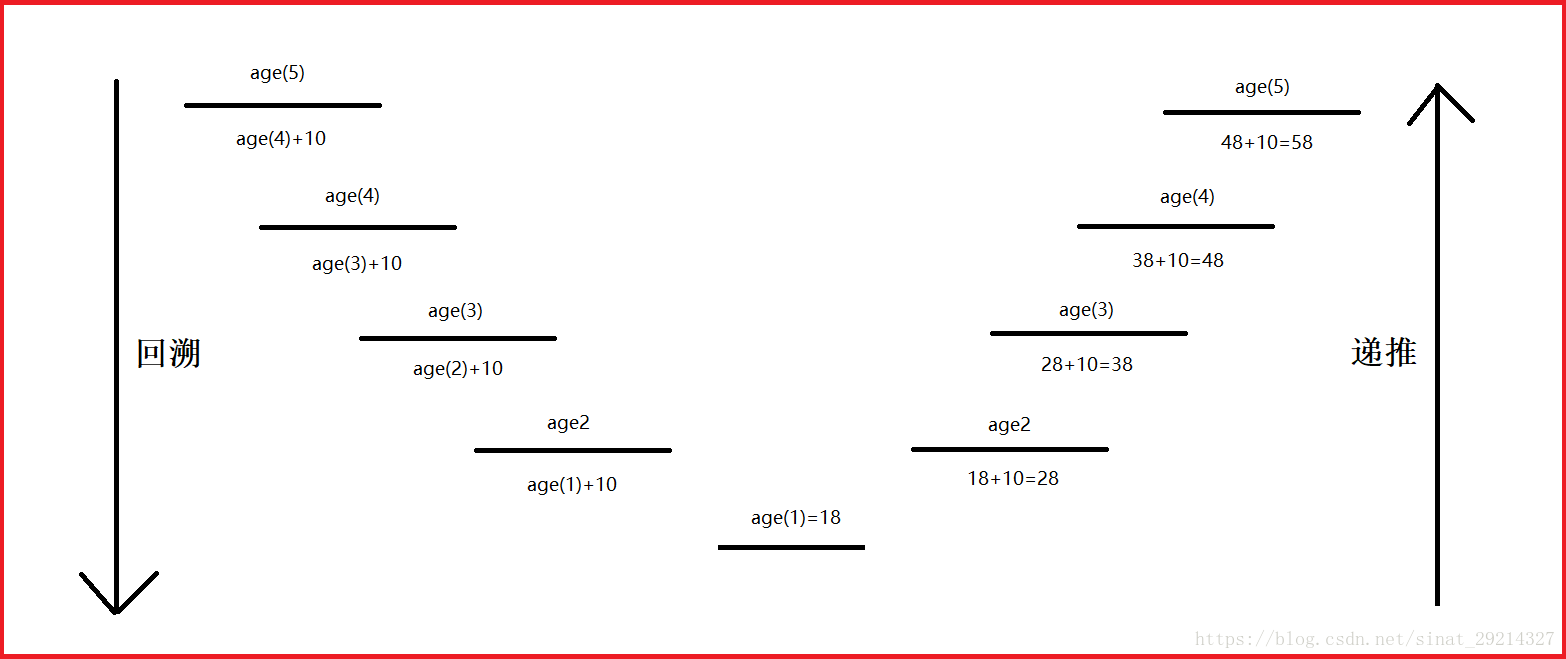
回溯:一层一层的调用下去,回溯阶段一定要有一个明确的结束条件 。
回溯阶段一定要有一个明确的结束条件,并且每一次回溯问题的规模都应该减少(否则就变成了单纯的重复,没有任何意义)
回溯阶段举例:
a=b+1
b=c+1
c=d+1
d=e+1
e=5递推:结束当前层的调用,进而往前一层一层的结束。
递推阶段举例:由例1反推得到
e=5
d=e+1 = 5+1=6
c=d+1 = 6+1=7
b=c+1 = 7+1=8
a=b+1 = 8+1=9
例子:回溯与递归的使用,拿到第5个人的年龄
思路是:
当n>1时: age(n)=age(n-1)+10
当n=1时: age(n)=18
def age(n):
if n == 1:
return 18
if n > 1:
return age(n-1)+10 # 重复调用函数age(n),当n为5时:+10, 当n为4时:+10, 当n为3时:+10, 当n为2时:+10,当n为1时:=18
print(age(5))过程分析:
例子:将列表里面的值依次取出
思路1:
l=[1,[2,[3,[4,[5,[6,[7,[8,[9,]]]]]]]]]
for n in l:
print(n)
>>: 1
>>: [2, [3, [4, [5, [6, [7, [8, [9]]]]]]]]
由于l的值为列表里面包含列表,所有for循环无法一步循环拿到所有值!
思路2:在思路1的基础上~
l=[1,[2,[3,[4,[5,[6,[7,[8,[9,]]]]]]]]]
def tell(l):
for item in l:
if type(item) is not list: # 通过判断拿到的值是否为list类型
print(item) # 如果不是列表的话,那就取出值
else:
tell(item) # 如果还是列表的话,那就继续循环。
tell(l)
1
2
3
4
5
6
7
8
9
九、递归的使用 -- 二分法
二分法:把列表从中间拆分为2段[左边,右边],然后判断,如果不符合要求,在[左边,右边]拆分为2段,然后再次判断
需求:给出一个数字,判断这个数字是否存在列表里面(列表的数字是从小到大依次排列的)
l=[1,11,57,89,90,99,100,123,155,188,199,230,255]
def search(num,list):
print(list)
mid_index=len(list) // 2 #把列表长度除以2
if num > list[mid_index]: #list[mid_index]按索引取值,取到的值为列表的中间的一个值,如果num大于这个值,那么num的值一定在中间值的右边
#in the right
list=list[mid_index+1:] #把中间值往右~~最后的值,这一段数字放在一个列表里面[右边列表]
search(num,list) #然后再次把值传入,判断num是否在"右边的列表"里
elif num < list[mid_index]:
#in the left
list=list[:mid_index] #把中间值往左~~第一个值,这一段数字放在一个列表里面[左边列表]
search(num,list) #然后再次把值传入,判断num是否在"左边的列表"里
else:
print('find it:',list)
search(123,l)
# 这里可以看到,一共查找了4次,就找到了123这个数字
[1, 11, 57, 89, 90, 99, 100, 123, 155, 188, 199, 230, 255]
[123, 155, 188, 199, 230, 255]
[123, 155, 188]
[123]
find it: [123]
十、max函数,取一组数字或者字符里面的最大值 -- 能被for循环循环的类型同样也能被max()循环
max的本质原理就是通过next(g)的方式不断取值,然后拿到最大值。
一、元组:
res=max((1,2,3,4,5))
print(res)
5
二、列表
res1=max(['s','b','c','d'])
print(res1)
s
三、字典取值,比较key的大小
dic={
'aaa':111,
'bbb':222,
'ccc':333,
}
print(max(dic))
ccc
3.1、字典取值,如何比较value的大小?
dic={
'aaa':1111,
'bbb':222,
'ccc':333,
}
def func(k):
return dic[k]
print(max(dic,key=func))
aaa
max函数本质是通过next()的方式取值,默认针对字典的取值是字典的"key",如何改变针对字典的默认取值呢?
1、通过添加参数"key"的方式(key对应的值是一个功能):参数"key"决定了next()这个功能的比较依据。
max(dic,key=func)代码过程分析:
1、先next(dic)取到字典的一个key("aaa"),然后把这个key("aaa")当做一个实参传值给函数func,然后执行函数func的代码。
2、将函数func的返回值作为比较依据。
3、max函数就会把"函数func的返回值"最为比较依据,然后比较大小。
4、最后不会打印出最大的那个值(value),而是打印出"value"对应的"key"。
3.2、或者使用匿名函数的方式取出字典里面value最大值对应的key
print(max(dic,key=lambda x:dic[x]))
aaa小例子:求a.txt文件里面最长行的长度 -- 方法:先求出每一行的长度,然后使用max()函数比较大小
with open('a.txt','r',encoding='utf-8') as f:
num=(len(line) for line in f)
print(max(num)) # 这里的num就相当于一个迭代器,使用max(num)就相当于使用for循环取最大值
28
# 简写方法:
# with open('a.txt','r',encoding='utf-8') as f:
# print(max([len(line) for line in f]))
十一、匿名函数 lambda ,匿名函数一般只使用一次
1、匿名函数不会单独使用,会与其他函数配合使用
2、匿名函数的精髓在于没有名字,如果没有名字,那么意味着用一次就立即回收,所以匿名函数的应用场景仅用于只是用一次的场景。
匿名函数的例子:
普通函数写法:
def func(x,y):
return x+y
匿名函数写法:
res=(lambda x,y:x+y)(1,2)
print(res)
3注释说明: lambda x,y:x+y
lambda #固定写法
x,y #就相当于def func(x,y),接收2个传参
:x+y #就相当于return x+y,匿名函数拿到的就是一个返回值
10.1、匿名函数的使用 -- 配合使用的内置函数,max,min,sorted,filter,map
1、求出一个字典里面value值最大的一个key --- 取最大值用max,取最小值用min
思考:我们已经知道如何求出一个字典里面key的最大值(max函数),那么如何取出一个字典里面value值最大的一个key呢?
dic={
'aaa':1111,
'bbb':222,
'ccc':333,
}
# 使用普通函数的方式
def func(k):
return dic[k]
print(max(dic,key=func))
aaa
# 使用匿名函数的方式
print(max(dic,key=lambda x:dic[x]))
aaa
2、sorted 排序功能,默认从小到大排序
比较列表里字符值的大小,然后从小到大排序
print(sorted([1,9,7,5]))
[1, 5, 7, 9]
根据字典里面value值的大小比较来排序对应的key
dic={
'aaa':1111,
'bbb':222,
'ccc':333,
}
print(sorted(dic,key=lambda x:dic[x]))
['bbb', 'ccc', 'aaa']
# 反过来比较,加一个reverse=True
print(sorted(dic,key=lambda x:dic[x],reverse=True))
['aaa', 'ccc', 'bbb']
3、map映射
需求,将列表里面的每个元素的后面都加上字符"_sb"
name=['aaa','bbb','ccc'] # name是一个可迭代对象
res=map(lambda x:x+'_sb',name) # map(lambda x:x+'_sb',name) 拿到一个迭代器对象
print(list(res)) # 使用list(res)实际上就是使用迭代取值的方式把res里面的值全部都取出来
['aaa_sb', 'bbb_sb', 'ccc_sb']
# 这样修改列表里面的值,不会占用内存空间。
方法2:使用for循环的方式取值
l=[n+"_sb" for n in name]
print(l)
['aaa_sb', 'bbb_sb', 'ccc_sb']
4、filter
需求:将列表内字符不包含"_sb"结尾的值取出
name=['aaa_sb','bbb_sb','ccc','ddd_sb']
res=filter(lambda x:x.endswith('sb'),name) # filter 会得到name的迭代器对象obj,然后next(obj),将得到的值传给filter第一个参数指定的函数,并且将函数返回值为True的那个值留下
print(list(res))
['aaa_sb', 'bbb_sb', 'ddd_sb']
方法2:使用for+if判断的方式取值
l=[n for n in name if n.endswith('sb')]
print(l)
['aaa_sb', 'bbb_sb', 'ddd_sb']