自然语言处理:序列标注(BiLSTM-CRF)
文章目录
- Tagging Scheme
- Bidirectional LSTM Networks
- Why use the CRF Networks?
- CRF Networks
- BiLSTM-CRF networks
- Emission score
- Transition score
- Decoding
- Loss function
- Bi-LSTM-CRF Networks
Reference:
1. Bidirectional LSTM-CRF Models for Sequence Tagging
2. Neural Architectures for Named Entity Recognition
3. Character-based BiLSTM-CRF Incorporating POS and Dictionaries for Chinese Opinion Target Extraction
4. CRF Layer on the Top of BiLSTM
5. Bi-LSTM + CRF with character embeddings for NER and POS
Tagging Scheme
IOBES: Inside, Outside, Beginning, End, Single
Bidirectional LSTM Networks

By utilize bidirectional LSTM, we can efficiently make use of past features (via forward states) and future features (via backward states) for a specific time frame.
We train the bidirectional LSTM networks using BPTT, and specially treat at the beginning and the end of the data points. Such as reset the hidden states to 0 at the begging of each sentence.
At time t t t for NER task:
- the input layer represents features could be one-hot-encoding for word feature, dense vector features, or sparse features.
- the output layer represents a probability distribution (distributed by softmax) over labels. It has the same dimensionality as size of labels. Using the label with the max probability as output of timestep t t t.
Why use the CRF Networks?
Despite use the h t \boldsymbol h_t ht as features to make independent tagging decisions for each output y t y_t yt is success in POS tagging, the independent classification decisions are limiting when there are strong dependencies across output labels.
As the NER task, since the “grammar” that characterizes interpretable sequences of tags imposes several hard constraints (e.g. I-PER cannot follow B-LOC) that would be impossible to model with independence assumptions.
The first way is to predict a distribution of tags of each time step and then use beam-like decoding to find optimal tag sequences, such as Maximum entropy classifier (Ratnaparkhi, 1996) and Maximum entropy Markov models (McCallum etal., 2000).
The second way is to focus on sentence level instead of individual positions, thus leading to Conditional Random Fields (CRF) models that the inputs and outputs are directly connected, as opposed to LSTM networks where memory cells/recurrent components are employed.
如下最右侧图,若不考虑不同位置词标注之间的关系,会出现错误的标注。
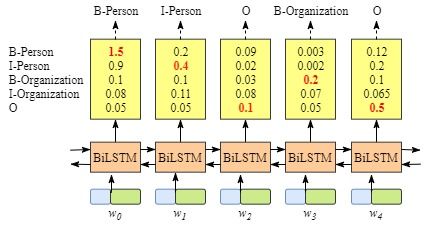

对于序列标注任务,输入词序列为观测序列,带标注的序列为隐藏状态序列。基于状态独立假设的序列标注模型,无法处理不同状态间的硬性约束,MRMM、CRF擅长解决此类问题。
MEMM假设当前状态仅与上一状态有关(马尔可夫性假设),CRF没有马尔可夫性假设,预测每个状态时考虑全局状态信息。
HMM(马尔可夫性假设、观测独立性假设) -> MEMM(马尔可夫性假设)-> CRF
CRF Networks
BiLSTM-CRF networks
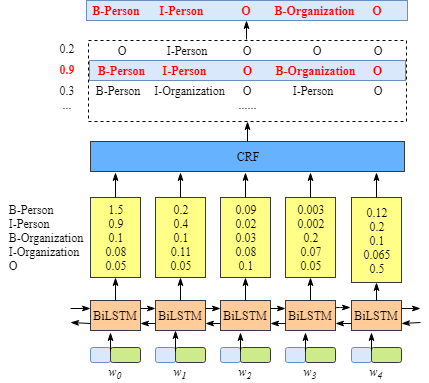
Given x = ( x 1 , x 2 , ⋯ , x n ) \boldsymbol x=(x_1,x_2,\cdots,x_n) x=(x1,x2,⋯,xn) and y = ( y 1 , y 2 , ⋯ , y n ) \boldsymbol y=(y_1,y_2,\cdots,y_n) y=(y1,y2,⋯,yn) to represent an input sequence and a sequence of predicted tags respectively, where n n n is the length of the input sentence.
Emission score
We consider P ∈ R n × k \boldsymbol P\in\R^{n\times k} P∈Rn×k to be the matrix of scores output by the BiLSTM network, where k k k is the number of distinct tags, the element P [ i , j ] P[i,j] P[i,j] corresponds to the score of the j j j-th tag of the i i i-th word in a sentence.
In BiLSTM-CRF networks, emission scores come from the BiLSTM layer. For instance, according the above figure, the score of w 0 w_0 w0 labeled as B-Person is 1.5.
对于长度为 n n n的句子,发射矩阵 P P P包含 n n n个 k k k维的隐藏状态.
Transition score
CRF introduces a transition matrix A ∈ R ( k + 2 ) × ( k + 2 ) \boldsymbol A\in\R^{(k+2)\times(k+2)} A∈R(k+2)×(k+2), that is position independent, which measure the score from i i i-th tag to j j j-th tag by the element A [ i , j ] A[i,j] A[i,j].
In order to make the transition score matrix more robust, we will add the START and the END tags of a sentence to the set of possible tags. A \boldsymbol A A is therefore a square matrix of size k + 2 k+2 k+2.
Here is an example of the transition matrix score including the extra added START and END labels.
| Transition Matrix | START | B-Person | I-Person | B-Organization | I-Organization | O | END |
|---|---|---|---|---|---|---|---|
| START | 0 | 0.8 | 0.007 | 0.7 | 0.0008 | 0.9 | 0.08 |
| B-Person | 0 | 0.6 | 0.9 | 0.2 | 0.0006 | 0.6 | 0.009 |
| I-Person | -1 | 0.5 | 0.53 | 0.55 | 0.0003 | 0.85 | 0.008 |
| B-Organization | 0.9 | 0.5 | 0.0003 | 0.25 | 0.8 | 0.77 | 0.006 |
| I-Organization | -0.9 | 0.45 | 0.007 | 0.7 | 0.65 | 0.76 | 0.2 |
| O | 0 | 0.65 | 0.0007 | 0.7 | 0.0008 | 0.9 | 0.08 |
| END | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
As shown in the table above, we can find that the transition matrix has learned some useful constraints.
- The label of first word in a sentence should start with “B-” or “O”, not “I-”.
- etc.
Where or how to get the transition matrix?
Transition matrix is a parameter of CRF layer. It’s initialization with random value, that will be more and more reasonable gradually with increasing training iterations.
Decoding
For a sentence has 5 words: x 1 , x 2 , x 3 , x 4 , x 5 x_1,x_2,x_3,x_4,x_5 x1,x2,x3,x4,x5, the real tags y \boldsymbol y y is:
Here, we add two more extra words which denote the start and the end of sentence: x 0 , x 6 x_0,x_6 x0,x6.
A linear-chain CRF defines a global score s ( x , y ) s(\boldsymbol x,\boldsymbol y) s(x,y) consists of 2 parts, such that:
s ( x , y ) = s e ( x , y ) + s t ( y ) = ∑ i = 1 n P [ x i , y i ] + ∑ i = 0 n A [ y i , y i + 1 ] s(\boldsymbol x,\boldsymbol y)=s_e(\boldsymbol x,\boldsymbol y)+ s_t(\boldsymbol y) =\sum_{i=1}^nP[x_i,y_i]+\sum_{i=0}^{n}A[y_{i},y_{i+1}] s(x,y)=se(x,y)+st(y)=i=1∑nP[xi,yi]+i=0∑nA[yi,yi+1]
Emission Score
s e ( x , y ) = P [ x 0 , START ] + P [ x 1 , B-Person ] + ⋯ + P [ x 6 , END ] s_e(\boldsymbol x,\boldsymbol y)=P[x_0,\text{START}]+P[x_1,\text{B-Person}]+\cdots+P[x_6,\text{END}] se(x,y)=P[x0,START]+P[x1,B-Person]+⋯+P[x6,END]
where P 0 P_0 P0 and P 6 P_6 P6 just set them zeros, P 1 ⋯ P 5 P_1\cdots P_5 P1⋯P5 are from the previous BiLSTM.
Transition Score
s t ( y ) = A [ START , B-Person ] + A [ B-Person , I-Person ] + ⋯ + A [ O , END ] s_t(\boldsymbol y)=A[\text{START},\text{B-Person}] + A[\text{B-Person},\text{I-Person}] + \cdots + A[\text{O},\text{END}] st(y)=A[START,B-Person]+A[B-Person,I-Person]+⋯+A[O,END]
these score are actually the parameters of CRF layer.
Illustration of the scoring of a sentence with linear-chain CRF:

1 + 10 + 4 + 3 + 2 + 11 + 0 = 31 |
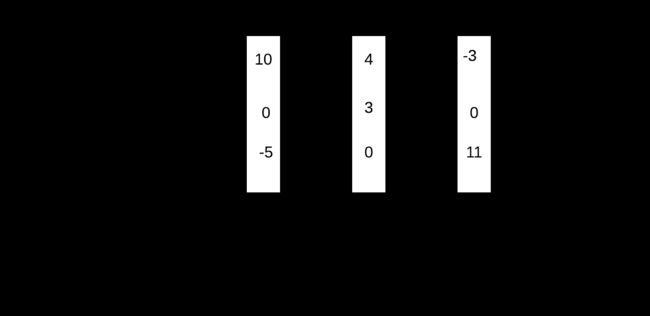
1 + 10 + 2 + 4 - 2 + 11 + 0 = 26 |
Now that we understand the scoring function of the CRF, we need to do 2 things:
- Find the sequence of tags with the best score.
- Compute a probability distribution over all the sequence of tags (total score).
The simplest way to measure the total score is that: enumerating all the possible paths and sum their scores. However, it is very inefficient, with n k n^k nk complexity. The recurrent nature of our formula makes it the perfect candidates to apply dynamic programming.
维特比算法求解最优路径
Let’s suppose that c t ( y t , x ) c_t(y_t,\boldsymbol x) ct(yt,x) is the solution for time steps t , ⋯ , n t,\cdots,n t,⋯,n for sequences that start with y t y_t yt:
c t ( y t , x ) = arg max y t , ⋯ , y n s ( y t , ⋯ y n , x ) = arg max y t , ⋯ , y n P [ x t , y t ] + A [ y t , y t + 1 ] + s ( y t + 1 , ⋯ , y n , x ) = arg max y t + 1 P [ x t , y t ] + A [ y t , y t + 1 ] + c t + 1 ( y t + 1 , x ) \begin{aligned} c_t(y_t,\boldsymbol x) &={\arg\max}_{y_t,\cdots, y_n}s(y_t,\cdots y_n,\boldsymbol x)\\[1ex] &={\arg\max}_{y_t,\cdots, y_n}P[x_t,y_t]+A[y_t,y_{t+1}]+s(y_{t+1},\cdots,y_n,\boldsymbol x)\\[1ex] &=\arg\max\nolimits_{y_{t+1}}P[x_t,y_t]+A[y_t,y_{t+1}]+c_{t+1}(y_{t+1},\boldsymbol x) \end{aligned} ct(yt,x)=argmaxyt,⋯,yns(yt,⋯yn,x)=argmaxyt,⋯,ynP[xt,yt]+A[yt,yt+1]+s(yt+1,⋯,yn,x)=argmaxyt+1P[xt,yt]+A[yt,yt+1]+ct+1(yt+1,x)
The best score and path are:
s ( x , y ∗ ) = c 0 ( y 0 = START , x ) , y ∗ = arg max y ~ ∈ Y s ( x , y ~ ) s(\boldsymbol x,\boldsymbol y^*)=c_0(y_0=\text{START},\boldsymbol x),\quad\boldsymbol y^*=\arg\max_{\tilde{\boldsymbol y}\in Y} s(\boldsymbol x,\tilde{\boldsymbol y}) s(x,y∗)=c0(y0=START,x),y∗=argy~∈Ymaxs(x,y~)
As we perform n n n step, final cost is O ( n k 2 ) O(nk^2) O(nk2), much less than O ( k n ) O(k^n) O(kn).
类似于CRF解码(已知模型、观测求最可能的状态序列)的维特比算法
动态规划求解归一化因子
模型的优化目标是最大化目标标注序列的概率,一般使用softmax将分数转化为概率,softmax分母项需求解所有可能标注序列的分数和 Z Z Z,也称为归一化因子,下面介绍基于前向递推动态规划的优化求解算法。
p ( y ∣ x ) = 1 Z exp ( s ( x , y ) ) , Z = ∑ y ~ exp ( s ( x , y ~ ) ) p(\boldsymbol y|\boldsymbol x)=\frac{1}{Z}\exp(s(\boldsymbol x,\boldsymbol y)),\quad Z=\sum_{\tilde{\boldsymbol y}}\exp(s(\boldsymbol x, \tilde{\boldsymbol y})) p(y∣x)=Z1exp(s(x,y)),Z=y~∑exp(s(x,y~))
假定已知时刻 t t t以 y t y_t yt为标注结尾的所有可能标注序列的总分数为 Z t ( y t ) Z_t(y_t) Zt(yt),即
Z t ( y t ) = ∑ y 1 , ⋯ , y t − 1 exp ( s ( y 1 , ⋯ , y t , x ) ) = ∑ y t − 1 exp ( P [ x t , y t ] + A [ y t − 1 , y t ] ) ∑ y 1 , ⋯ , y t − 2 exp ( s ( y 1 , ⋯ , y t − 1 ) ) = ∑ y t − 1 exp ( P [ x t , y t ] + A [ y t − 1 , y t ] ) ⋅ Z t − 1 ( y t − 1 ) \begin{aligned} Z_t(y_t) &=\sum_{y_1,\cdots,y_{t-1}}\exp({s(y_1,\cdots,y_t,\boldsymbol x)})\\[.5ex] &=\sum_{y_{t-1}}\exp(P[x_t,y_t]+A[y_{t-1},y_t])\sum_{y_1,\cdots,y_{t-2}}\exp(s(y_1,\cdots,y_{t-1}))\\ &=\sum_{y_{t-1}}\exp({P[x_t,y_t]+A[y_{t-1},y_t]})\cdot Z_{t-1}(y_{t-1}) \end{aligned} Zt(yt)=y1,⋯,yt−1∑exp(s(y1,⋯,yt,x))=yt−1∑exp(P[xt,yt]+A[yt−1,yt])y1,⋯,yt−2∑exp(s(y1,⋯,yt−1))=yt−1∑exp(P[xt,yt]+A[yt−1,yt])⋅Zt−1(yt−1)
对于总时间步为 n n n的序列,所有可能标注序列的总分数为
Z = ∑ y n Z n ( y n ) Z = \sum_{y_n}Z_n(y_n) Z=yn∑Zn(yn)
动态规划求解对数归一化因子
归一化因子需对n条路径求指数和,很容易造成浮点数溢出,实际优化函数也是极大化目标序列的对数似然
log p ( y ∣ x ) = s ( x , y ) − log ∑ y ~ exp ( s ( x , y ~ ) ) \log p(\boldsymbol y|\boldsymbol x) =s(\boldsymbol x,\boldsymbol y)- \log\sum_{\tilde{\boldsymbol y}}\exp(s(\boldsymbol x, \tilde{\boldsymbol y})) logp(y∣x)=s(x,y)−logy~∑exp(s(x,y~))
令 Z t ( y t ) Z_t(y_t) Zt(yt)表示时刻 t t t以 y t y_t yt结尾的所有可能序列分数的logsumexp,则前向递归公式为(这边文章用实例说明的很好)
Z t ( y t ) = log ∑ y 1 ⋯ y t − 1 e s ( x , y 1 ⋯ y t ) = log ∑ y t − 1 e P [ x t , y t ] + A [ y t − 1 , y t ] ∑ y 1 ⋯ y t − 2 e s ( x , y 1 ⋯ y t − 1 ) = log ∑ y t − 1 e P [ x t , y t ] + A [ y t − 1 , y t ] e Z t − 1 ( y t − 1 ) = log ∑ y t − 1 e P [ x t , y t ] + A [ y t − 1 , y t ] + Z t − 1 ( y t − 1 ) \begin{aligned} Z_t(y_t) &=\log\sum_{y_1\cdots y_{t-1}}e^{s(\boldsymbol x,y_1\cdots y_t)}\\ &=\log\sum_{y_{t-1}}e^{P[x_t,y_t]+A[y_{t-1},y_t]}\sum_{y_1\cdots y_{t-2}}e^{s(\boldsymbol x, y_1\cdots y_{t-1})}\\ &=\log\sum_{y_{t-1}}e^{P[x_t,y_t]+A[y_{t-1},y_t]}e^{Z_{t-1}(y_{t-1})}\\ &=\log\sum_{y_{t-1}}e^{P[x_t,y_t]+A[y_{t-1},y_t]+Z_{t-1}(y_{t-1})} \end{aligned} Zt(yt)=logy1⋯yt−1∑es(x,y1⋯yt)=logyt−1∑eP[xt,yt]+A[yt−1,yt]y1⋯yt−2∑es(x,y1⋯yt−1)=logyt−1∑eP[xt,yt]+A[yt−1,yt]eZt−1(yt−1)=logyt−1∑eP[xt,yt]+A[yt−1,yt]+Zt−1(yt−1)
任意时刻 t t t对所有的 Z t ( y t ) Z_t(y_t) Zt(yt)再进行一次logsumexp,得到该时刻总分数的对数归一化因子
Z t = log ∑ y t e Z t ( y t ) = log ∑ y 1 ⋯ y t e s ( x , y 1 ⋯ y t ) Z_t = \log\sum_{y_t}e^{Z_t(y_t)}=\log\sum_{y_1\cdots y_t}e^{s(\boldsymbol x, y_1\cdots y_t)} Zt=logyt∑eZt(yt)=logy1⋯yt∑es(x,y1⋯yt)
神奇的公式
很多文献、博客中介绍归一化因子对数形式的递推公式时,引入公式
log ∑ e log ( ∑ e x ) + y = log ∑ ∑ e x + y \log\sum e^{\log(\sum e^x)+y}=\log\sum\sum e^{x+y} log∑elog(∑ex)+y=log∑∑ex+y
这个公式很难理解,为什么可以根据这个公式就能得到对应归一化因子的递推公式?
不难发现,本文中的 Z t ( y t ) Z_t(y_t) Zt(yt)的递推公式中的第4、2行分别对应这个公式左右两个方程,其中
y = P [ x t , y t ] + A [ y t − 1 , y t ] , x = s ( x , y 1 ⋯ y t − 1 ) , Z t − 1 ( y t − 1 ) = log ∑ e x y=P[x_t,y_t]+A[y_{t-1},y_t],\quad x=s(x,y_1\cdots y_{t-1}),\quad Z_{t-1}(y_{t-1})=\log\sum e^x y=P[xt,yt]+A[yt−1,yt],x=s(x,y1⋯yt−1),Zt−1(yt−1)=log∑ex
logsumexp防止溢出性
很容易证明,以下等式成立
log ∑ x e x = a + log ∑ x e x − a \log\sum_x e^x=a+\log\sum_x e^{x-a} logx∑ex=a+logx∑ex−a
令 a = max x a=\max x a=maxx 就不会造成数据上溢出,softmax函数多采用这种处理。
Loss function
CRF loss function is consist of the real path score and the total score of all the possible paths. The real path should having the highest score among those of all possible paths.
The loss function of CRF model as below (minimize loss function):
L ( θ ) = − log p ( y ∣ x ) = − s ( x , y ) + logadd y ~ ∈ Y s ( x , y ~ ) L(\theta)=-\log p(\boldsymbol y|\boldsymbol x) =-s(\boldsymbol x,\boldsymbol y) + \text{logadd}_{\tilde{\boldsymbol y}\in Y}\ s(\boldsymbol x,\tilde{\boldsymbol y}) L(θ)=−logp(y∣x)=−s(x,y)+logaddy~∈Y s(x,y~)
where the score s ( x , y ) s(\boldsymbol x,\boldsymbol y) s(x,y) of real path should be the one with largest percentage in all the scores, Y Y Y represents all possible tag sequences, even those that do not verify the IOB format for a sentence x \boldsymbol x x.
During the training process, the parameter values of our BiLSTM-CRF model will be updated again and again to keep increasing the percentage of the score of the real path.
Bi-LSTM-CRF Networks
Combine a Bi-LSTM network and a CRF network to form a Bi-LSTM-CRF model. This network can efficiently use past input features via a Bi-LSTM layer and sentence level tag information via a CRF layer.
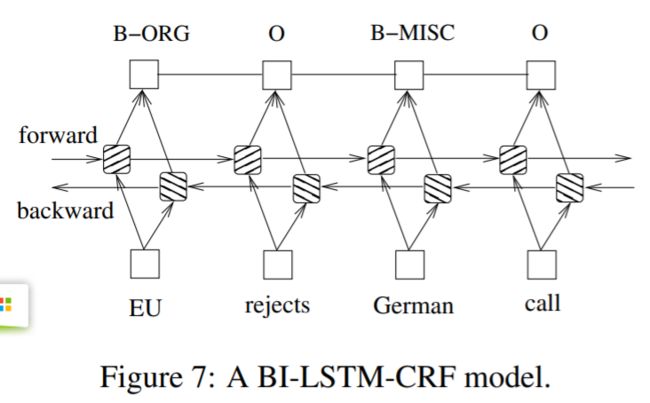
We construct our neural network by using hidden state of Bi-LSTM layer as input sequence of CRF layer. We can use the concatenation hidden states (forward + backward), denoted as h t \boldsymbol h_t ht of x t x_t xt to predict the tag of corrected x t x_t xt directly, since it contains the context information.
We feed those hidden states h = ( h 1 , h 2 , ⋯ , h n ) \boldsymbol h=(\boldsymbol h_1,\boldsymbol h_2,\cdots,\boldsymbol h_n) h=(h1,h2,⋯,hn) into CRF layer:
P = W s h + b s \boldsymbol P=\boldsymbol W_s\boldsymbol h + \boldsymbol b_s P=Wsh+bs
where W s \boldsymbol W_s Ws and b s \boldsymbol b_s bs are the parameters.