逆向协议分析
目录
分析1:协议分析
一、数据链路层(Ethernet)
二、网络层
三、传输层
四、应用层
分析2:Scapy编程
分析3:算法逆向破解
分析1:协议分析
访问网址https://malware-traffic-analysis.net/ ,下载其中的一个协议包,给出详细分析过程。
如图为网址中下载的pcap文件,我们分析No.3的协议包。
No.3数据包的协议类型为DNS协议。DNS协议即域名服务协议,它主要用于域名和IP地址之间的相互转换,以及控制控制因特网的电子邮件的发送。 通过数据包详情窗口看到,该DNS数据包有四层数据数据内容,数据链路层(Ethernet)、网络层、传输层、应用层。
一、数据链路层(Ethernet)
EthernetII 帧(又称DIX帧)是目前使用最广的以太帧,如图为Ethernet II的帧结构: 以太类型值为0x0800指示了该帧包含了IPv4数据报,0x0806表明指示了该帧包含了ARP帧,0x8100指示了该帧包含了IEEE 802.1Q帧。
以太类型值为0x0800指示了该帧包含了IPv4数据报,0x0806表明指示了该帧包含了ARP帧,0x8100指示了该帧包含了IEEE 802.1Q帧。
如图为该DNS数据包的EthernetII 帧数据内容: 从图中可以看出,该数据包中的目的MAC地址为:a4:1f:72:c2:09:6a,源MAC地址为:00:1d:60:b5:5e:94,以太类型为:0x0800,表示是IPv4数据包。
从图中可以看出,该数据包中的目的MAC地址为:a4:1f:72:c2:09:6a,源MAC地址为:00:1d:60:b5:5e:94,以太类型为:0x0800,表示是IPv4数据包。
二、网络层
IP数据报的格式如图所示:
该DNS数据包的IP数据内容如下: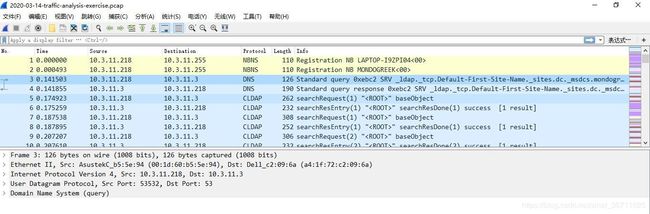
版本:占4位,表示版本信息。该数据包中的内容为4,表示为IPv4数据报
首部长度:占4位,因此最大值为15。值为1表示的是1个32位字的长度,也就是4字节。该数据包中的内容为5,表示为首部长度为20字节。
区分服务:用来获得更好的服务,一般情况下不使用。该数据包中的内容为0x00。
总长度:包括首部长度和数据部分长度。该数据包内容为:0x0070(112字节)。
标识 : 在数据报长度过长从而发生分片的情况下,相同数据报的不同分片具有相同的标识符。该数据包的内容为:0x0000fbea。
标志:占3位。但目前只有2位有意义。标志字段中的最低位记为 MF (More Fragment)。MF=1即表示后面“还有分片”的数据报。MF=0表示这已是若干数据报片中的最后一个。标志字段中间的一位记为 DF(Don't Fragment),意思是“不能分片”。只有当 DF=0时才允许分片。MF=1即表示后面“还有分片”的数据报。MF=0表示这已是若干数据报片中的最后一个。该数据包的标志位内容为:000。表示该数据包不分片。
片偏移 : 和标识符一起,用于发生分片的情况。片偏移占13位。该数据包的内容为:0000000000000。
生存时间 :TTL,它的存在是为了防止无法交付的数据报在互联网中不断兜圈子。以路由器跳数为单位,当TTL为0时就丢弃数据报。该数据包的字段内容为:0x80(128跳)。
协议 :指出携带的数据应该上交给哪个协议进行处理,例如 ICMP(1)、TCP(6)、UDP(17)等。该数据包字段内容为:0x11(17),表示ip数据报使用的是UDP协议。
首部检验和 :首部检验和:占16位。这个字段只检验数据报的首部,但不包括数据部分。这是因为数据报每经过一个路由器,都要重新计算一下首都检验和 (一些字段,如生存时间、标志、片偏移等都可能发生变化)。不检验数据部分可减少计算的工作量。该数据包的字段内容为:0x13b0。
源地址:占32位。该数据包此字段内容为:10.3.11.218,对应二进制数据为:0x0a030bda。
目的地址:占32位。该数据包此字段内容为:10.3.11.3,对应二进制数据为:0x0a030b03。
三、传输层
传输层协议有TCP和UDP两种,以下为TCP和UDP的报文格式:

如图为该DNS数据包的传输层协议(UDP协议)内容:
源端口号:占16位。此字段内容为:53532,对应的二进制数据为:0xd11c。该端口为用户端口,每次都会改变。
目的端口号:占16位。此字段内容为:53(DNS服务),对应的二进制数据为:0x0035。该端口是指定服务所定义好的,由ICANN来管理的。
UDP长度:占16位,UDP报文的字节长度(包括首部和数据)。此字段内容为:92字节,对应的二进制数据为:0x005c。
UDP校验和:占16位,检验UDP首部和数据部分的正确性。此字段内容为:0x2c72。
四、应用层
由传输层可知,应用层服务为DNS服务。DNS协议报文格式如下图所示:
如图为该数据包应用层DNS协议的数据内容: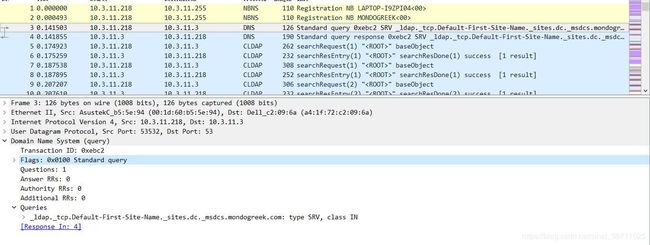
会话标识(2字节):是DNS报文的ID标识,对于请求报文和其对应的应答报文,这个字段是相同的,通过它可以区分DNS应答报文是哪个请求的响应。此字段内容为:0xebc2。
标志(2字节):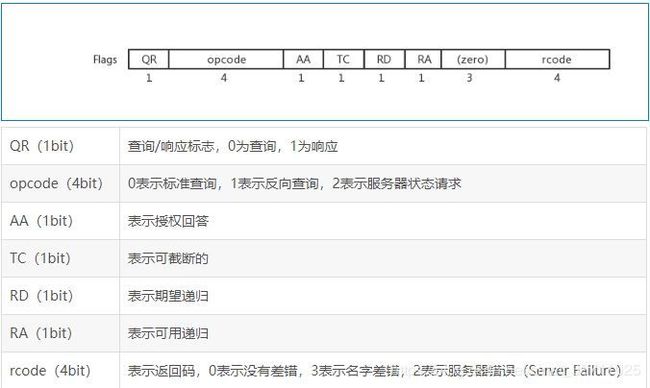 此字段内容为:0x0100,表示标准查询。
此字段内容为:0x0100,表示标准查询。
数量字段(总共8字节):Questions、Answer RRs、Authority RRs、Additional RRs 各自表示后面的四个区域的数目。Questions表示查询问题区域节的数量,Answers表示回答区域的数量,Authoritative namesversers表示授权区域的数量,Additional recoreds表示附加区域的数量。此字段内容为:1,0,0,0。
Queries区域:
1 查询名:长度不固定,且不使用填充字节,一般该字段表示的就是需要查询的域名(如果是反向查询,则为IP,反向查询即由IP地址反查域名),一般的格式如下图所示。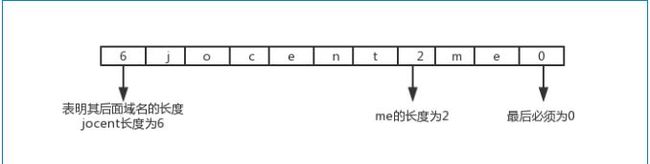
2 查询类型:
3 查询类:通常为1,表明是Internet数据
此Queries字段内容为: 查询的域名为:_ldap._tcp.Default-First-Site-Name._sites.dc._msdcs.mondogreek.com
查询的域名为:_ldap._tcp.Default-First-Site-Name._sites.dc._msdcs.mondogreek.com
查询类型为:SRV。
查询类为:0x0001,表示互联网地址。
分析2:Scapy编程
熟悉Scapy库使用,编写函数实现给定域名解析
在分析一中,分析DNS协议可知,在Queries字段中,如果查询类型为1(A)时,就可以通过域名获得IPv4地址。
查询Scapy文档:https://scapy.readthedocs.io/en/latest/usage.html#dns-requests ,有DNS请求,其中IPv4(A)请求可以执行DNS请求来查询IPv4地址。
from scapy.all import *
from scapy.layers.dns import DNS, DNSQR
from scapy.layers.inet import IP, UDP
# 根据域名查询IPv4地址
def query_dns(dns_name):
'''
Scapy函数介绍:
sr()函数:用来发送数据包和接收响应信息。这个函数返回好几个数据包和响应,和未应答的数据包
sr1()函数:一种变体,只返回发送的、应答的数据包响应。
srp()函数:对第二层数据(Ethernet, 802.3等)做相同的功能。
:param dns_name: 域名地址
:return:
'''
# dst:DNS域名服务器IP地址
# dport: DNS协议端口号53
# id: DNS会话标识字段(匹配请求与回应)
# qr:查询/响应标志,0为查询,1为响应
# opcode:0表示标准查询,1表示反向查询,2表示服务器状态请求
# rd:1表示期望递归
# qname:要查询的域名
# qtype: 查询类型
ans = sr1(IP(dst="114.114.114.114")/UDP(sport=RandShort(), dport=53)/DNS(id=201, qr=0, opcode=0, rd=1, qd=DNSQR(qname=dns_name, qtype="A")))
# ans1, unans1 = sr(IP(dst="114.114.114.114")/UDP(sport=RandShort(), dport=53)/DNS(id=201, qr=0, opcode=0, rd=1, qd=DNSQR(qname=dns_name, qtype="A")))
# print(ans1[0][1].show())
# print(ans.show())
# print(ans.summary())
# print(ans.getlayer(DNS).show())
# print(ans.getlayer(DNS).an.type)
# print(ans.getlayer(DNS).ancount)
# 根据DNS协议字段可知,响应数据包在回答(answers:an)区域,授权(authoritative nameservers:ns)区域和附加(additional recoreds:ar)区域
dns = ans.getlayer(DNS)
for x in range(dns.ancount):
if dns.an[x].type == 1:
dns_ip = dns.an[x].rdata
print('域名: {} 对应的IPv4地址:{}'.format(dns_name, dns_ip))
else: # 但是查询的有不一定是A,可能是CNAME,输入的域名可能不正确,应要求查询规范名称
print('请输入规范的域名地址!')
if __name__ == '__main__':
# query_dns('cn.bing.com')
query_dns('baidu.com')
query_dns('bing.com')jupyter notebook中安装第三方包
# 以安装scapy为例
import sys
!{sys.executable} -m pip install scapy
分析3:算法逆向破解
base64加密是属于可逆加密的,即前后可以互逆。
base64算法就是根据一个base64表,将原始字符的值一一替换。替换规则如下:
1、首先将每三个字节划分为一组,得到24个二进制位
2、然后将这24个二进制位划分为4组,得到4组6个二进制位的大小
3、在每组前面添加两个00,扩展成32个二进制位,也就是四个字节。
4、根据base64的表格对照替换得到base64编码
表格如下:
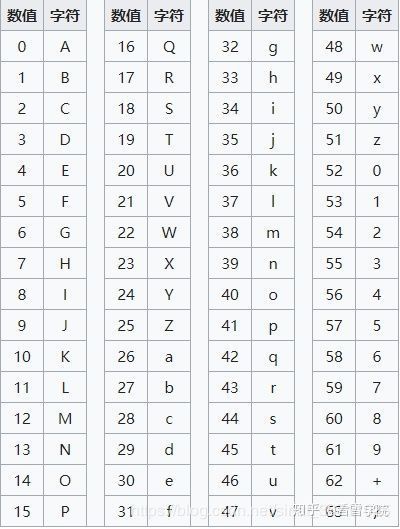
定义为字符串数组如下: "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
如果需要编码的字节不能被三整除,则会多出1个或2个字节,处理方式是加上"="号,也就是平时我们看到的base64编码最后的"="或者"=="
# 算法逆向破解
# 加密函数,flag是某个字符串
import random
import base64
def enc(flag):
bcode = {
'16': lambda x: base64.b16encode(x), # 使用lambda表达式对x进行base64编码
'32': lambda x: base64.b32encode(x),
'64': lambda x: base64.b64encode(x)
}
# 字符串在Python内部的表示是unicode编码
# 因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
msg = flag.encode('utf-8') # encode的作用是将unicode编码转换成其他编码的字符串
# 加密过程
for i in range(10):
order = random.choice(['64', '32', '16'])
msg = bcode[order](msg)
# print('{}:{}'.format(order, msg))
msg = msg.decode('utf-8') # decode的作用是将其他编码的字符串转换成unicode编码
return msg
# print(enc('flag{****some secret****}'))
# 任务:假设flag未知,如何通过加密结果恢复出flag
# print(base64.b16encode('Hello, I am Darren!'.encode('utf-8')))
# print(base64.b32encode('Hello, I am Darren!'.encode('utf-8')))
# print(base64.b64encode('Hello, I am Darren!'.encode('utf-8')))
cipherText = enc("flag{****some secret****}")
print("密文是:", cipherText)
def dec(cipher):
bcode = {
'16': lambda x: base64.b16decode(x), # 使用lambda表达式对x进行base64编码
'32': lambda x: base64.b32decode(x),
'64': lambda x: base64.b64decode(x)
}
num = ('16', '32', '64')
msg = cipher.encode('utf-8')
for i in range(10): # 两层循环
for k in num:
try:
msg = bcode[k](msg)
# 如果解密成功那个跳过这次,否则继续下一轮
if msg:
break
else:
continue
except:
pass
msg = msg.decode('utf-8')
return msg
plainText = dec(cipherText)
print("解密后的明文是:", plainText)