序列化梳理
文章目录
- 一、为什么需要序列化?
- 二、反序列化时如何生成实例
- 三、是不是所有的类都需要序列化
- 四、java序列化(Serializable)和外部化(Externalizable)的主要区别
- 五、哪些东西需要序列化
- 1. 普通成员变量需要序列化
- 2. 静态变量无需序列化
- 3. 方法无需序列化
- 4. 属性是一个引用(需要被序列化)
- 5.有父类(较为复杂)
- 6. 有实现接口(接口内容无需序列化)
- 7. 用transient保护的敏感信息不用序列化
- 六、java序列化为什么要使用serialversionUID
- 七、序列化应用
- 1.dubbo RPC序列化
- 2.缓存序列化
- 3.各种序列化方式比较(kryo/fst/json/hessian2)
- 八、参考链接:
一、为什么需要序列化?
java进程运行时会把相关的类生成一堆实例,并放入堆栈空间中,如果进程执行结束,那么内存中的实例对象就会被gc回收。如果想在新的程序中使用之前那个对象,应该怎么办?
远程接口调用时,两端在各自的虚拟机中运行,因为内存是不共享的,那么入参和返回值如何传递?
序列化就是解决这个问题的。虽然内存不共享,但我们可以将对象转化为一段字节序列,并放到流中,接下来就交给 I/O,可以存储在文件中、可以通过网络传输……当我们想用到这些对象的时候,再通过 I/O,从文件、网络上读取字节序列,根据这些信息重建对象。而重建对象的过程也叫做“反序列化”。如果没有 “反序列化”,那么“序列化”是没有任何意义的。
用现实生活中的搬桌子为例,桌子太大了不能通过比较小的门,我们要把它拆了再运进去,这个拆桌子的过程就是序列化。同理,反序列化就是等我们需要用桌子的时候再把它组合起来,这个过程就是反序列化。
理解上面的背景知识后,序列化和反序列化概括起来就是下面这张图:
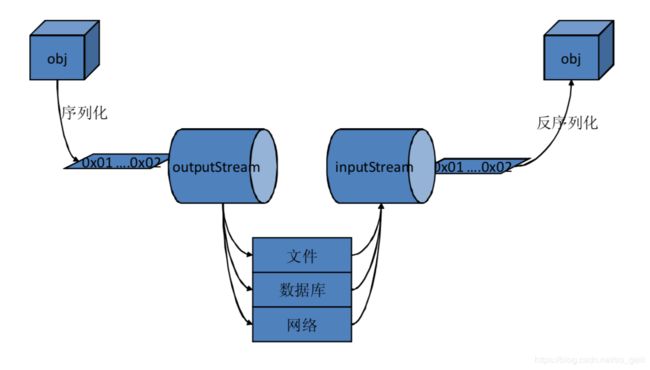
- 根据某种序列化算法,将对象序列化。(结果可能是:字节序列、json串等,取决于使用的序列化算法)
- 将序列化的结果通过流写入到载体中 (文件、数据库、redis、网络等 )
- 当要用到这些对象的时候,程序通过输入流从载体中读取出序列化的流信息,根据对应的反序列化算法,重建对象。
虽然过程很简单,但每一步都有很多东西需要了解,下面就逐一介绍。
二、反序列化时如何生成实例
生成对象实例时,一般的做法是让每个类提供一个默认的无参构造方法,等到反序列化的时候,自动调用这个构造方法来生成实例。看似蛮合理的、蛮简单的,但是这种方式有几个缺陷:
- 侵入性太大,为了实现反序列化,类不得不提供无参构造。
- 不安全,如果有的类不希望提供构造方法给外界调用。那么序列化/反序列化的这个“无理”要求将引起灾难。
因此上述方案是行不通的,只能另寻出路。这里直接说底层源码的做法 :不用类去显示声明无参构造方法,而是通过一种语言之外的对象创建机制;从底层源码来看,生成实例时调用了 java.reflect.Constructor的 newInstance() 方法。
// 用反射生成实例
public T newInstance(Object... initargs) throws InstantiationException, IllegalAccessException, IllegalArgumentException, InvocationTargetException {
// ... 此次省略
return (T) constructorAccessor.newInstance(initargs);
}
这里就有两个问题需要注意:
- 通过序列化可以任意创建实例,不受任何限制。单例模式如果实现序列化的话,通过反序列化也可以轻松创建对象。
- 由于不调用类自己的构造器,而是通过构造器Constructor来实现的。一些限制条件就很难满足。比如,有两个参数 max,min,构造时必须满足 max>min。如果不满足参数条件,系统存在被序列化攻击的风险。
- 对象进行序列化时,类中所定义的被private、final等访问控制符所修饰的字段是直接忽略这些访问控制符而直接进行序列化的,因此,原本在本地定义的想要控制字段的访问权限的工作都是不起作用的。对于序列化后的有序字节流来说一切都是可见的,对象中的任何private字段几乎都是以明文的方式出现在套接字流中,这严重破坏了原有类的数据的“安全性”。幸运的是,我们可以让序列化的类可以实现一个 writeObject方法;反序列化过程,我们将在同一个类上实现一个readObject方法,通过使用writeObject 和 readObject 可以实现密码加密和签名管理。
public class Person implements java.io.Serializable {
public Person(String fn, String ln, int a) {
this.firstName = fn; this.lastName = ln; this.age = a;
}
// 省略 get set 方法
// writeObject
private void writeObject(java.io.ObjectOutputStream stream)
throws java.io.IOException {
age = age << 2;
stream.defaultWriteObject();
}
// readObject
private void readObject(java.io.ObjectInputStream stream)
throws java.io.IOException, ClassNotFoundException {
stream.defaultReadObject();
age = age << 2;
}
private String firstName;
private String lastName;
private int age;
private Person spouse;
}
三、是不是所有的类都需要序列化
是不是所有的类都需要序列化? 如果是,则序列化就应该是类的基本功能,如果这样的话,序列化就应该对程序员彻底透明才是,所以并不是所有的类都需要序列化,原因如下:
- 安全问题:有的类是敏感的类,里面的数据不能公开。而实现了序列化就很容易被破解,可以说没有秘密可言,隐私性没有保证。
- 资源问题:序列化可以任意生成实例而不受限制,如果有的对象生成的实例是受限制的,比如只能生成10个实例,或者是单例的,这个很难保证。
所以不是所有的类都需要序列化,那么这就要提供一个接口/标识符,需要序列化的类要贴上标识符。未实现此接口的类将无法使其任何状态序列化或反序列化。可序列化类的所有子类型本身都是可序列化的。这个标识符就是 Serializable 或 Externalizable(定制自己的序列化算法),实现了任何一个接口就代表可以被序列化。这就是JDK自带的java序列化。当然还有很多的序列化框架,如:json序列化、dubbo序列化、fst、kryo、hessian2序列化等,他们的区别就在于序列化算法不同,把java实例生成的不同的序列流。先重点梳理JDK自带的java序列化。
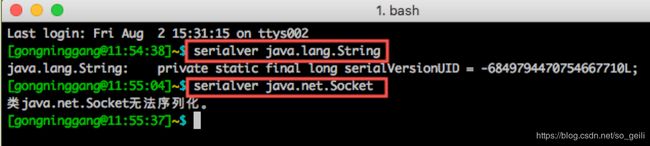
java 有个工具可以查看一个类是否能够使用"java序列化",用法如下:
四、java序列化(Serializable)和外部化(Externalizable)的主要区别
通过Serializable接口对对象序列化的支持是内建于核心api的,也就是说只要类实现java.io.Serializable接口,java就会试图存储和重组你的对象。如果使用外部化,程序员就可以自由地完成读取和存储的方式(自定义序列化算法、反序列化算法)。
- 序列化:
- 优点:易于实现;直接实现Serializable接口即可。
- 缺点:占用空间过大、由于额外的开销导致速度变比较慢,字节序列可读性差。
- 外部化:
- 优点:开销较少(程序员决定存储什么)速度可能有提升;
- 缺点:虚拟机不提供任何帮助,也就是说所有的工作(开发自定义序列化算法、反序列化算法)都落到了开发人员的肩上。
在两者之间如何选择要根据应用程序的需求来定。serializable通常是最简单的解决方案,但是虚拟机必须弄清楚每个成员属性的结构,所以可能会导致不可接受的性能问题或空间问题;在出现这些问题的情况下,externalizable可能是一条可行之路。要记住一点,如果一个类是可外部化的(externalizable),那么externalizable方法将被用于序列化类的实例,即使这个类型也提供了serializable方法。
// write方法用于实现定制序列化,read方法用于实现定制反序列化
public interface Externalizable extends java.io.Serializable {
void writeExternal(ObjectOutput out) throws IOException;
void readExternal(ObjectInput in) throws IOException, ClassNotFoundException;
}
五、哪些东西需要序列化
类里那么多东西 ,哪些需要进行序列化?序列化的原则就是:序列化的信息要足够帮助我们在反序列化的时候恢复之前对象的状态就可以了,空间能省则省(毕竟涉及到网络传输问题)。那我们来分析下面这个Person.java类:
@Data
public class Person implements Serializable {
private String name;
protected String account;
public String password;
//private String newAdd;
//static int i=0;
//private transient Double dou;
}
public class TestSerial {
public static void main(String[] args) throws Exception {
//序列化 采用默认的序列化算法把对象转换为字节序列。
SerialUtils.writeObject(new Person(), "personbyte");
//反序列化
SerialUtils.readObject("personbyte");
}
}
public class SerialUtils {
public static void writeObject(Object o, String fileName) throws IOException {
File file = new File(fileName);
FileOutputStream fos = new FileOutputStream(file);
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(o);
oos.flush();
oos.close();
fos.close();
// 返回文件以字节为单位的长度,或者文件不存在时返回 0
System.out.println("长度:" + file.length());
}
public static Object readObject(String fileName) throws IOException, ClassNotFoundException {
File file = new File(fileName);
FileInputStream fis = new FileInputStream(file);
ObjectInputStream ois = new ObjectInputStream(fis);
Object o = ois.readObject();
ois.close();
fis.close();
System.out.println("read form " + fileName + "get " + o);
return o;
}
}
执行上面的main方法,可以看到如下结果:

对象序列化使用的是一种特殊的文件格式来存储对象。使用UltraEdit打开personbyte文件(上述案例生成),使用16进制的方式查看字节序列,如下:
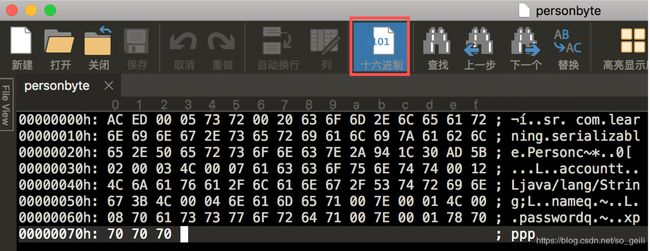
- AC ED:STREAM_MAGIC,声明使用了序列化协议.
- 00 05: STREAM_VERSION.序列化协议版本.
- 0x73: TC_OBJECT.声明这是一个新的对象.
- 0x72: TC_CLASSDESC.声明这里开始一个新Class。
可读性极差,不再一一解释这些16进制的含义。深挖下去意义不大。
1. 普通成员变量需要序列化
无论是用什么权限标识符修饰(public/private/protected)的成员变量,他们都是对象的状态,不序列化成员变量的话,反序列化的实例也是不完整的。所以,普通成员变量必须序列化。
2. 静态变量无需序列化
静态变量其实是类属性,并不属于某个具体实例,所以也不用保存。当恢复对象的时候,直接取类当前的静态变量即可。(可以放开Person类中的static int i=0;注释,执行结果不变同上图)
3. 方法无需序列化
方法只是类的无状态指令。重建类的时候,可以直接从类的信息中获取,所以也不需要被序列化。(同样可以用代码验证)
以上讨论的都是很简单的情形,下面看一些复杂场景:
4. 属性是一个引用(需要被序列化)
类a有b、c两个引用属性,b有引用d,d又引用f….看下图:
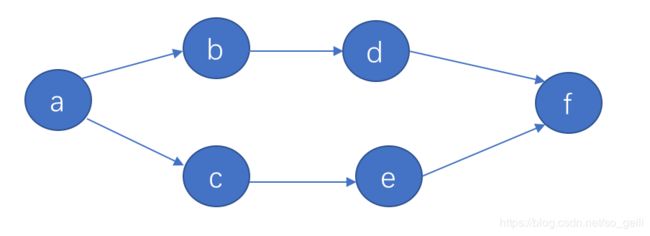
成员变量虽是引用,但也是对象必不可缺的属性,如果序列化时不存储这些信息,反序列化出来的对象是残缺的,它的所有引用属性都会是null。所以当一个对象的实例变量引用其他对象,序列化该对象时也把引用对象进行序列化。需要注意的是,上图描述的是一个特殊的场景,含有对f实例的重复引用,序列化时f实例只会被序列化一次。循环引用本篇不展开介绍,详见《解决fastjson内存对象重复/循环引用json错误》,这篇博文以fastJson序列化框架为例,介绍了重复/循环引用的一种很实际序列化方案。
java对象序列化不仅保留一个对象的数据,而且递归保存对象引用的每个对象的数据。可以将整个对象层次写入字节流中,可以保存在文件中或在网络连接上传递。利用对象序列化可以进行对象的"深复制",即复制对象本身及引用的对象本身。
这种复杂对象也使得序列化和反序列化算法比较复杂,本篇不会深入解释序列化算法。
5.有父类(较为复杂)
子类继承父类 ,就像儿子继承父亲的特征,比如姓氏。那么姓氏也应该是儿子的一个状态,所以父类的这些状态还是要保存的。但并不绝对,因为还有另一个问题,如果父类没有实现序列化接口呢?
@Data
public class Person extends Animal implements Serializable {
private String name;
protected String account;
public String password;
//private String newAdd;
//static int i=0;
//private transient Double dou;
public Person(){
super(1);
}
}
// 这里的父类没有实现序列化
public class Animal {
private Integer age;
public Animal(Integer age) {
this.age = age;
System.out.println("父 有参构造执行");
}
// 若去掉父类的无参构造方法,反序列化时会报语法错误。
public Animal() {
System.out.println("父 无参构造执行");
}
}
修改Demo程序让Person类继承一个没有实现序列化的Animal类,重新执行main方法。结果如下:
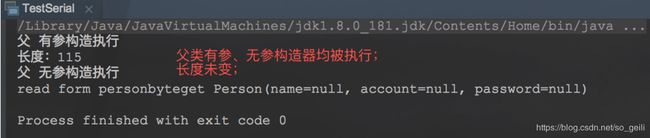
这说明没有实现序列化的父类,没有被写入到文件中,序列化的仅仅是子类。而且注意一点 ,父类的构造方法被调用了两次。为什么呢?这个挺好解释的,因为我们要创建一个子类的实例 ,必然要创建其父类的实例。第一个“父 有参构造执行”就是创建子类时,调用了父类的有参构造方法而打印出来的;第二个是我们反序列化的时候,生成子类实例的时候,调用了父类的无参构造方法,而打印出来的。若去掉父类的无参构造方法,反序列化时会报语法错误。
长度:115
Exception in thread "main" java.io.InvalidClassException: com.learning.serializable.Person; no valid constructor
at java.io.ObjectStreamClass$ExceptionInfo.newInvalidClassException(ObjectStreamClass.java:169)
at java.io.ObjectStreamClass.checkDeserialize(ObjectStreamClass.java:874)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2043)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:431)
at com.learning.serializable.SerialUtils.readObject(SerialUtils.java:35)
at com.learning.serializable.TestSerial.main(TestSerial.java:22)
Process finished with exit code 1
修改代码,让父类实现序列化:
public class Animal implements Serializable{
private Integer age;
public Animal(Integer age) {
this.age = age;
System.out.println("父 有参构造执行");
}
public Animal() {
System.out.println("父 无参构造执行");
}
}
执行main方法,结果如下:

注意:
若父类没有实现序列化,反序列化时要生成示例,就只能调用父类的无参构造方法,没有无参构造就会报错。如果父类实现了序列化,那么父类的无参构造方法是不会被调用的。
结论如下:
- 父类实现序列化:父类的状态被保存
- 父类未实现序列化:分两种情况
- 父类提供了无参构造方法:子类可以序列化,父类不能序列化.
- 父类没有提供无参构造方法:子类可以序列化,反序列化时程序报错.
- 当一个父类实现序列化,子类自动实现序列化,不需要显式实现Serializable接口
6. 有实现接口(接口内容无需序列化)
接口一般是无状态的,就算有也是static的,那么毫无疑问,接口的信息也不会被序列化。
7. 用transient保护的敏感信息不用序列化
前面说过了,类里面的哪些信息要被序列化,非static的属性是要被序列化的。所以用户可能不想序列化某些敏感内容,比如前面例子中的password,因为序列化之后,黑客可以轻而易举的破解其内容,没有丝毫安全性可言(在序列化进行传输的过程中,这个对象的private等域是不受保护的。)。如果我们是设计者的话,会怎么做?无非有两种做法:
- 对敏感属性打一个标识,序列化的时候,不保存这些内容。
- 对敏感内容进行加密。
java里采用第一种方式,这个标识叫做transient(瞬态/临时数据)。用法如下:
transient private String password;
原理也很简单,在序列化的时候,虚拟机会将标识 transient 的属性排除在外。
六、java序列化为什么要使用serialversionUID
If a serializable class does not explicitly declare a serialVersionUID, then the serialization runtime will calculate a default serialVersionUID value for that class based on various aspects of the class, as described in the Java™ Object Serialization Specification. However, it is strongly recommended that all serializable classes explicitly declare serialVersionUID values, since the default serialVersionUID computation is highly sensitive to class details that may vary depending on compiler implementations, and can thus result in unexpected InvalidClassExceptions during deserialization.
以上是序列化接口上的注释,如果用户没有自己声明一个serialVersionUID,接口会默认生成一个serialVersionUID(根据包名、类名、继承关系、非私有的方法和属性以及参数、返回值等诸多因子计算得出的,生成极度复杂的一个64位的long值。基本上计算出来的这个值是唯一的),但是强烈建议用户自定义一个serialVersionUID,因为默认的serialVersinUID对于class的细节非常敏感,类修改后默认的serialVersionUID也会发生变化。如果序列化和反序列化时用的serialversionUID不同,会导致InvalidClassException异常。
修改上面的测试用例,不显式指定Person类的serialversionUID。将对象进行序列化保存到本地文件中;然后修改Person类(增减属性);最后,从本地文件读取序列化后的有序字节流,进行反序列化,重建对象。报如下错误:
Exception in thread "main" java.io.InvalidClassException: com.learning.serializable.Person; local class incompatible: stream classdesc serialVersionUID = 7407092434109718168, local class serialVersionUID = 2475206011077688084
at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:699)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1885)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1751)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2042)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:431)
at com.learning.serializable.SerialUtils.readObject(SerialUtils.java:35)
at com.learning.serializable.TestSerial.main(TestSerial.java:22)
Process finished with exit code 1
当指定序列化版本serialversionUID时,序列化端 和 反序列化端的对象属性个数、名字即使对应不上,也不会影响反序列化,对应不上的属性会有默认值。也就是说对象显式指定serialversionUID时,序列化和反序列化时,兼容性更好。这里所说的兼容性,仅仅以反序列化成功为标准。在很多复杂的业务中,兼容性还要满足其他约束条件,不仅仅是满足反序列化成功而已。
以上就是JDK自带的java序列化,虚拟机必须弄清楚每个成员属性的结构,所以性能问题和空间问题较为突出,生产中较少使用。成熟的序列化框架很多,如:json序列化、dubbo序列化、fst、kryo、hessian2序列化等,他们的性能、使用场景各有不同。下面重点介绍序列化应用。
七、序列化应用
1.dubbo RPC序列化
在dubbo RPC中,服务调用的入参和出参就是通过序列化和反序列化实现的。dubbo RPC同时支持多种序列化方式,例如:
- dubbo序列化:阿里尚未开发成熟的高效java序列化实现,阿里不建议在生产环境使用它
- hessian2序列化:hessian是一种跨语言的高效二进制序列化方式。但这里实际不是原生的hessian2序列化,而是阿里修改过的hessian lite,它是dubbo RPC默认启用的序列化方式
- json序列化:目前有两种实现,一种是采用的阿里的fastjson库,另一种是采用dubbo中自己实现的简单json库,但其实现都不是特别成熟,而且json这种文本序列化性能一般不如上面两种二进制序列化。
- java序列化:主要是采用JDK自带的Java序列化实现,性能很不理想。
对于dubbo RPC这种追求高性能的远程调用方式来说,实际上只有第1、第2两种高效序列化方式比较般配,而第1个dubbo序列化由于还不成熟,所以实际只剩下2可用,所以dubbo RPC默认采用hessian2序列化。但hessian是一个比较老的序列化实现了,而且它是跨语言的,所以不是单独针对java进行优化的。而dubbo RPC实际上完全是一种Java to Java的远程调用,其实没有必要采用跨语言的序列化方式(当然肯定也不排斥跨语言的序列化)。
除此之外,各种新的高效序列化方式层出不穷,不断刷新序列化性能的上限,如专门针对Java语言的:Kryo,FST等等。
使用Kryo和FST非常简单,只需要在dubbo RPC的XML配置中添加一个属性即可。详见
2.缓存序列化
在企业开发中缓存能提高系统的性能。无论是redis、memcache等存储的都是序列化后的信息。例如在使用kryo序列化方法刷redis缓存时,常见的set、get方法,如下:
// set
public boolean setByKryo(String key, Object object_, int seconds) {
if (object_ == null) {
return false;
}
ShardedJedis commonJedis = null;
byte[] data_ = null;
boolean success = false;
try {
commonJedis = jedisPool.getResource();
Kryo kryo = new Kryo();
Output output = new Output( 256, 131072);
kryo.writeObject(output, object_);
data_ = output.toBytes();
output.flush();
output.close();
commonJedis.setex(key.getBytes(), getRealCacheTime(seconds), data_);
success = true;
} catch (Exception e) {
jedisPool.returnBrokenResource(commonJedis);
RedisException.exceptionJedisLog(logger, key, commonJedis, e , "setByKryo");
commonJedis = null;
} finally {
if (commonJedis != null) {
jedisPool.returnResource(commonJedis);
}
}
return success;
}
// get
public Object getByKryo(String key, Class<?> myClass, int seconds) {
ShardedJedis commonJedis = null;
Object object_ = null;
Input input = null;
try {
commonJedis = jedisPool.getResource();
byte[] data_ = commonJedis.get(key.getBytes());
if (data_ == null) {
return null;
}
Kryo kryo = new Kryo();
input = new Input(data_);
object_ = kryo.readObject(input, myClass);
if (seconds > 0) {
commonJedis.expire(key, getRealCacheTime(seconds));
}
} catch (Exception e) {
jedisPool.returnBrokenResource(commonJedis);
RedisException.exceptionJedisLog(logger, key, commonJedis, e , "getByKryo");
commonJedis = null;
} finally {
if (commonJedis != null) {
jedisPool.returnResource(commonJedis);
}
if (input != null) {
input.close();
}
}
return object_;
}
kryo序列化刷缓存有其缺陷,在实际开发中,bean增删字段是很常见的事情,但kryo却不支持这一操作。所以生产中采用json序列化刷缓存较为普遍。
3.各种序列化方式比较(kryo/fst/json/hessian2)
- kryo序列
- 优点:kryo序列化更快,采用可变长存储方式,让kryo序列化后的数据比Java序列化占用的空间更小。
- 缺点:可读性差,kryo序列化不支持bean新增字段。因为生成的byte数据中部包含field数据,对类升级的兼容性很差!所以,若用kryo序列化对象用于C/S架构的话,两边的Class结构要保持一致。
- 踩坑记:在开发中,一些表对应的entity需要通过kryo序列化存储进redis,而kryo反序列化是通过取key值进行的。如果对表增减字段,那么kryo取key值反序列化时,旧的缓存内容和新entity字段对不上,反序列时报错。所以,无论修改哪张表,都先要确定这张表的bean是否需要序列化。如果存在 ICacheKey 取值,需要把数据重新刷到另外一个key上,替换原有缓存key值为新的key值。这样序列化与反序列化时,就不会出现字段对不上的情况,只要设计通过key值取值的地方均需要更改,且反复校验,是否有丢落的地方。
在dubbo rpc中 ,kryo序列化方式,也同样存在反序列化时不兼容的问题。
-
fst序列化
FST序列化/反序列化,这篇博客中重点介绍了序列化和反序列化的过程。结论是:FST序列化方式缺点和kyro类似,序列化反序列化速度很快,缺点也是和kyro类似,新增加字段时,会不兼容。解决方法分两种:- 如果接口返回的bean不是List类型,可以直接加@Version注解。
- 如果接口返回的bean是List类型。建议将dubbo的序列化方式由fst改成hession2。
-
json序列化
- 优点:可读性强,兼容性强,增加字段不会出现无法反序列化的问题。
- 缺点:序列化反序列化速度慢,由于是纯字符串,序列化后的结果可能会较大,会引起IO问题。
适用场景:
业务会不断变化,会经常有增加字段的业务场景,序列化需要有兼容性。
能控制好key的大小、适当使用redis的命令(避免hgetall等操作,尽可能低地减少序列化反序列化和IO问题)。
FastJson简单实用、fastjson漏洞网上有很多分析看不太懂,参考Fastjson反序列化漏洞研究
- hessian2序列化
- 优点:默认支持跨语言,兼容性好。
- 缺点:性能不好。
序列化框架性能对比参考链接
八、参考链接:
- Java 对象序列化
- 序列化和反序列化
- 《序列化的秘密》
- 《Effective java 中文版(第二版)》
- 一篇搞懂java序列化Serializable
- FST序列化/反序列化
- 浅析kryo
- 在Dubbo中使用高效的Java序列化(Kryo和FST)
- 高效的Java序列化(Kryo和FST)
- Kryo官方文档-中文翻译
- 谈谈 JAVA 的对象序列化