使用Stanford NLP工具实现中文命名实体识别
一、 系统配置
Eclipseluna、 JDK 1.8+
二、分词介绍
使用斯坦福大学的分词器,下载地址http://nlp.stanford.edu/software/segmenter.shtml,从上面链接中下载stanford-segmenter-2014-10-26,解压之后,如下图所示
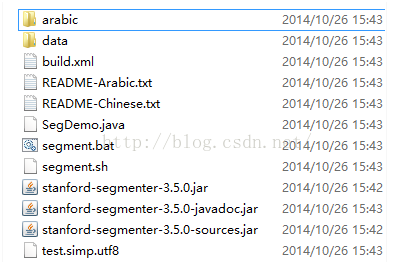
data目录下有两个gz压缩文件,分别是ctb.gz和pku.gz,其中CTB:宾州大学的中国树库训练资料 ,PKU:中国北京大学提供的训练资料。
三、 NER
使用斯坦福大学的NER,下载地址:http://nlp.stanford.edu/software/CRF-NER.shtml,在该页面下分别下载stanford-ner-2014-10-26和stanford-ner-2012-11-11-chinese两个包。
解压后分别可以看到:
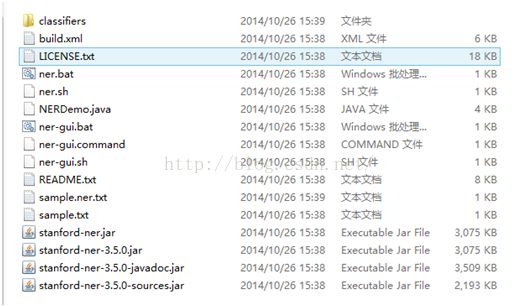
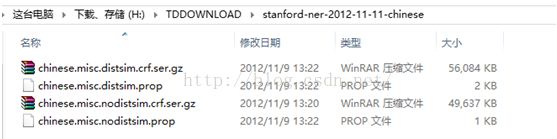
同时下载commons-io-2.4.jar、commons-lang3-3.3.2.jar、junit-4.10.jar三个Java包。
四、 中文命名实体识别
新建Java项目,将data目录拷贝到项目根路径下,再把stanford-ner-2012-11-11-chinese解压的内容全部拷贝到classifiers文件夹下,将第三步中的三个Java包以及stanford NER和分词器的Java包都导入classpath中,然后,在:http://nlp.stanford.edu/software/ corenlp.shtml下载stanford-corenlp-full-2014-10-31,将解压之后的stanford-corenlp-3.5.0也加入到classpath之中。将stanfordner中src添加到项目目录下,并添加一下两个代码:
ExtractDemo.java
importedu.stanford.nlp.ie.AbstractSequenceClassifier;
importedu.stanford.nlp.ie.crf.CRFClassifier;
importedu.stanford.nlp.ling.CoreLabel;
/*
ClassNameExtractDemo
加载NER模块
*/
publicclassExtractDemo
{
privatestaticAbstractSequenceClassifier
publicExtractDemo()
{
InitNer();
}
publicvoidInitNer()
{
String serializedClassifier ="classifiers/chinese.misc.distsim.crf.ser.gz";//chinese.misc.distsim.crf.ser.gz
if (ner ==null)
{
ner =CRFClassifier.getClassifierNoExceptions(serializedClassifier);
}
}
public StringdoNer(Stringsent)
{
returnner.classifyWithInlineXML(sent);
}
publicstaticvoid main(Stringargs[])
{
String str = "今天下雨,不去打球。";
ExtractDemoextractDemo =newExtractDemo(); System.out.println(extractDemo.doNer(str));
System.out.println("Complete!");
}
}
ZH_SegDemo.java
importjava.io.File;
importjava.io.IOException;
importjava.util.Properties;
importorg.apache.commons.io.FileUtils;
importedu.stanford.nlp.ie.crf.CRFClassifier;
importedu.stanford.nlp.ling.CoreLabel;
/*
* ClassNameZH_SegDemo
* Description 使用StanfordCoreNLP进行中文实体识别
*/
public class ZH_SegDemo {
public staticCRFClassifier
static {
// 设置一些初始化参数
Propertiesprops = new Properties();
props.setProperty("sighanCorporaDict","data");
props.setProperty("serDictionary","data/dict-chris6.ser.gz");
props.setProperty("inputEncoding","UTF-8");
props.setProperty("sighanPostProcessing","true");
segmenter = newCRFClassifier
segmenter.loadClassifierNoExceptions("data/ctb.gz",props);
segmenter.flags.setProperties(props);
}
public static String doSegment(String sent) {
String[] strs =(String[]) segmenter.segmentString(sent).toArray();
StringBufferbuf= new StringBuffer();
for (String s :strs) {
buf.append(s +" ");
}
System.out.println("segmentedres: " + buf.toString());
returnbuf.toString();
}
public staticvoid main(String[] args) {
try {
StringreadFileToString = FileUtils.readFileToString(newFile("IFENG-8.txt"));
StringdoSegment = doSegment(readFileToString);
System.out.println(doSegment);
ExtractDemoextractDemo= new ExtractDemo();
System.out.println(extractDemo.doNer(doSegment));
System.out.println("Complete!");
} catch(IOException e) {
e.printStackTrace();
}
}
}
最后项目结构如下:

运行结果如下: