词向量模型(word2vec)总结笔记
引言
自从Mikolov在他2013年的论文“Efficient Estimation of Word Representation in Vector Space”提出词向量的概念后,NLP领域仿佛一下子进入了embedding的世界,Sentence2Vec、Doc2Vec、Everything2Vec。词向量基于语言模型的假设——“一个词的含义可以由它的上下文推断得出“,提出了词的Distributed Representation表示方法。相较于传统NLP的高维、稀疏的表示法(One-hot Representation),Word2Vec训练出的词向量是低维、稠密的。
在上一篇文章里,我们用onehot将词转换成向量的形式,如下所示:
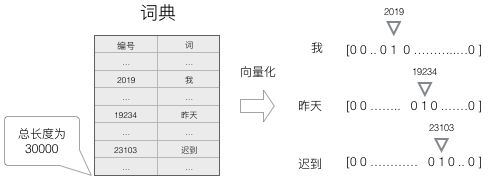
假设有二、三、四元词进行onehot,我们可能得到的特征为:
feature1=[01,10]
feature2=[001,010,100]
feature3=[0001,0010,0100,1000]
而如果依照上面的特征,我们发现会出现正交的情况,那么根据余弦相似度的关系, a ⋅ b = ∣ a ∣ ∣ b ∣ cos θ \boldsymbol{a}\cdot \boldsymbol{b}=\left| \boldsymbol{a} \right|\left| \boldsymbol{b} \right|\cos \theta a⋅b=∣a∣∣b∣cosθ,这将导致任何一对词的余弦相似度为0,而它得到的特征也将是离散稀疏的。
word2vec介绍
关于word2vec,我们知道的CBOW(Continuous Bag-of-Words Model)和Skip-gram (Continuous Skip-gram Model),都是它的两种训练模式。而负采样(Negative Sample)和层次softmax(Hierarchical Softmax)则是两种加速训练的方法。
跳字模型(skip-gram)
在跳字模型中,词典索引集 V = { 0 , 1 , … , ∣ V ∣ − 1 } \mathcal{V} = \{0, 1, \ldots, |\mathcal{V}|-1\} V={0,1,…,∣V∣−1}。假设给定一个长度为 T T T的文本序列,设时间步 t t t的词为 w ( t ) w^{(t)} w(t)。假设给定中心词的情况下背景词的生成相互独立,当背景窗口大小为 m m m时,跳字模型的似然函数即给定任一中心词生成所有背景词的概率
∏ t = 1 T ∏ − m ≤ j ≤ m , j ≠ 0 P ( w ( t + j ) ∣ w ( t ) ) , \prod_{t=1}^{T} \prod_{-m \leq j \leq m,\ j \neq 0} P(w^{(t+j)} \mid w^{(t)}), t=1∏T−m≤j≤m, j=0∏P(w(t+j)∣w(t)),
m为窗口大小,比如说m=2也就是滑窗大小为5,T为文本序列的总长度,上式也为给定中心词的极大似然估值。而在之前的softmax章节中提到过,若要使得整个联合概率最大化,这个联合概率最大化就等价于最小化这个损失函数,那么上式就能等价于:
− 1 T ∑ t = 1 T ∑ − m ≤ j ≤ m , j ≠ 0 log P ( w ( t + j ) ∣ w ( t ) ) -\frac{1}{T} \sum_{t=1}^{T} \sum_{-m \leq j \leq m,\ j \neq 0} \text{log}\, P(w^{(t+j)} \mid w^{(t)}) −T1t=1∑T−m≤j≤m, j=0∑logP(w(t+j)∣w(t))
我们可以用 v v v和 u u u分别代表中心词和背景词的向量。换言之,对于词典中一个索引为 i i i的词,它在作为中心词和背景词时的向量表示分别是 v i v_{i} vi和 u i u_{i} ui。而词典中所有词的这两种向量正是跳字模型所要学习的模型参数。为了将模型参数植入损失函数,我们需要使用模型参数表达损失函数中的中心词生成背景词的概率。设中心词 w c w_{c} wc 在词典中索引为 ,背景词 w o w_{o} wo 在词典中索引为 ,给定中心词生成背景词的条件概率可以通过对向量内积做softmax运算而得到:
P ( w o ∣ w c ) = exp ( u o ⊤ v c ) ∑ i ∈ V exp ( u i ⊤ v c ) P(w_o \mid w_c) = \frac{\text{exp}(\boldsymbol{u}_o^\top \boldsymbol{v}_c)}{ \sum_{i \in \mathcal{V}} \text{exp}(\boldsymbol{u}_i^\top \boldsymbol{v}_c)} P(wo∣wc)=∑i∈Vexp(ui⊤vc)exp(uo⊤vc)
当序列长度T较大时,我们通常随机采样一个较小的子序列来计算损失函数并使用随机梯度下降优化该损失函数。根据定义:
∂ log P ( w o ∣ w c ) ∂ v c = u o − ∑ j ∈ V exp ( u j ⊤ v c ) ∑ i ∈ V exp ( u i ⊤ v c ) u j \frac{\partial \log \mathbb{P}\left( w_o|w_c \right)}{\partial v_c}=u_o-\sum_{j\in \mathcal{V}}{\frac{\exp \left( u_{j}^{\top}v_c \right)}{\sum_{i\in \mathcal{V}}{\exp}\left( u_{i}^{\top}v_c \right)}}u_j ∂vc∂logP(wo∣wc)=uo−j∈V∑∑i∈Vexp(ui⊤vc)exp(uj⊤vc)uj
通过微分,可以得到:
∂ log P ( w o ∣ w c ) ∂ v c = u o − ∑ j ∈ V exp ( u j ⊤ v c ) u j ∑ i ∈ V exp ( u i ⊤ v c ) = u o − ∑ j ∈ V ( exp ( u j ⊤ v c ) ∑ i ∈ V exp ( u i ⊤ v c ) ) u j = u o − ∑ j ∈ V P ( w j ∣ w c ) u j . \begin{aligned} \frac{\partial \text{log}\, P(w_o \mid w_c)}{\partial \boldsymbol{v}_c} &= \boldsymbol{u}_o - \frac{\sum_{j \in \mathcal{V}} \exp(\boldsymbol{u}_j^\top \boldsymbol{v}_c)\boldsymbol{u}_j}{\sum_{i \in \mathcal{V}} \exp(\boldsymbol{u}_i^\top \boldsymbol{v}_c)}\\ &= \boldsymbol{u}_o - \sum_{j \in \mathcal{V}} \left(\frac{\text{exp}(\boldsymbol{u}_j^\top \boldsymbol{v}_c)}{ \sum_{i \in \mathcal{V}} \text{exp}(\boldsymbol{u}_i^\top \boldsymbol{v}_c)}\right) \boldsymbol{u}_j\\ &= \boldsymbol{u}_o - \sum_{j \in \mathcal{V}} P(w_j \mid w_c) \boldsymbol{u}_j. \end{aligned} ∂vc∂logP(wo∣wc)=uo−∑i∈Vexp(ui⊤vc)∑j∈Vexp(uj⊤vc)uj=uo−j∈V∑(∑i∈Vexp(ui⊤vc)exp(uj⊤vc))uj=uo−j∈V∑P(wj∣wc)uj.
上式即为我们求得的词向量的梯度,它的计算需要词典中所有词以 w c w_{c} wc为中心词的条件概率。
连续词袋模型(continuous bag of words,CBOW)
同样,连续词袋模型和词袋模型基本一致,与跳字模型最大的不同在于,连续词袋模型假设基于某中心词在文本序列前后的背景词来生成该中心词。举个例子,给定背景词“the”“man”“his”“son”生成中心词“loves”的条件概率,也就是:
P ( ‘ ‘ l o v e s " ∣ ‘ ‘ t h e " , ‘ ‘ m a n " , ‘ ‘ h i s " , ‘ ‘ s o n " ) P(``loves"∣``the",``man",``his",``son") P(‘‘loves"∣‘‘the",‘‘man",‘‘his",‘‘son")
给定一个长度为 T T T的文本序列,设时间步 t t t的词为 w t w_{t} wt ,背景窗口大小为 m m m。连续词袋模型的似然函数是由背景词生成任一中心词的概率:
∏ t = 1 T P ( w ( t ) ∣ w ( t − m ) , … , w ( t − 1 ) , w ( t + 1 ) , … , w ( t + m ) ) \prod_{t=1}^{T} P(w^{(t)} \mid w^{(t-m)}, \ldots, w^{(t-1)}, w^{(t+1)}, \ldots, w^{(t+m)}) t=1∏TP(w(t)∣w(t−m),…,w(t−1),w(t+1),…,w(t+m))
连续词袋模型的最大似然估计等价于最小化损失函数:
− ∑ t = 1 T log P ( w ( t ) ∣ w ( t − m ) , … , w ( t − 1 ) , w ( t + 1 ) , … , w ( t + m ) ) -\sum_{t=1}^T \text{log}\, P(w^{(t)} \mid w^{(t-m)}, \ldots, w^{(t-1)}, w^{(t+1)}, \ldots, w^{(t+m)}) −t=1∑TlogP(w(t)∣w(t−m),…,w(t−1),w(t+1),…,w(t+m))
那么再对上式做softmax运算就可以得到:
P ( w c ∣ w o 1 , … , w o 2 m ) = exp [ u c ⊤ ( v o 1 + … + v o 2 n ) / ( 2 m ) ] ∑ i ∈ V exp [ u i ⊤ ( v o 1 + … + v o 2 m ) / ( 2 m ) ] \mathbb{P}\left(w_{c} | w_{o_{1}}, \ldots, w_{o_{2 m}}\right)=\frac{\exp \left[\mathbf{u}_{c}^{\top}\left(\mathbf{v}_{o_{1}}+\ldots+\mathbf{v}_{o_{2 n}}\right) /(2 m)\right]}{\sum_{i \in \mathcal{V}} \exp \left[\mathbf{u}_{i}^{\top}\left(\mathbf{v}_{o_{1}}+\ldots+\mathbf{v}_{o_{2 m}}\right) /(2 m)\right]} P(wc∣wo1,…,wo2m)=∑i∈Vexp[ui⊤(vo1+…+vo2m)/(2m)]exp[uc⊤(vo1+…+vo2n)/(2m)]
同样,当序列长度 T T T较大时,我们通常随机采样一个较小的子序列来计算损失函数并使用随机梯度下降优化损失函数:
∂ log P ( w c ∣ w o 1 , . . . , w o 2 ) ∂ v o i = 1 2 m ( u c − ∑ j ∈ V exp ( u j ⊤ v c ) ∑ i ∈ V exp ( u i ⊤ v c ) u j ) \frac{\partial \log \mathbb{P}\left( w_c|w_{o_1},...,w_{\left. o_2 \right)} \right.}{\partial v_{o_i}}=\frac{1}{2m}\left( u_c-\sum_{j\in \mathcal{V}}{\frac{\exp \left( u_{j}^{\top}v_c \right)}{\sum_{i\in V}{\exp}\left( u_{i}^{\top}v_c \right)}}u_j \right) ∂voi∂logP(wc∣wo1,...,wo2)=2m1⎝⎛uc−j∈V∑∑i∈Vexp(ui⊤vc)exp(uj⊤vc)uj⎠⎞