FM模型
FM模型
一、FM模型的意义
1、传统模型的缺点
忽略了特征之间的联系
特征高维、稀疏,容易爆炸
2、什么是FM模型
FM就是Factor Machine,因子分解机。
FM通过对两两特征组合,引入交叉项特征,提高模型得分;其次是高维灾难,通过引入隐向量(对参数矩阵进行矩阵分解),完成对特征的参数估计。
二、FM模型
1、对特征进行组合
一般的线性模型
y = ω 0 + ∑ i = 1 n w i x i y = {\omega _0} + \sum\limits_{i = 1}^n {{w_i}{x_i}} y=ω0+i=1∑nwixi
二阶多项式模型
y = ω 0 + ∑ i = 1 n w i x i + ∑ i = 1 n − 1 ∑ j = i + 1 n ω i j x i x j y = {\omega _0} + \sum\limits_{i = 1}^n {{w_i}{x_i}} + \sum\limits_{i = 1}^{n - 1} {\sum\limits_{j = i + 1}^n {{\omega _{ij}}{x_i}{x_j}} } y=ω0+i=1∑nwixi+i=1∑n−1j=i+1∑nωijxixj
上式中,n表示样本的特征数量,xi表示第i个特征。
与线性模型相比,FM模型多了后面特征组合的部分。
2、FM求解
从上面的式子可以看到,组合部分的特征相关参数有 n ( n − 1 ) / 2 n\left( {n - 1} \right)/2 n(n−1)/2个。但是对于稀疏数据来说,同时满足 x i , x j {x_i},{x_j} xi,xj都不为0的情况十分少,这就会导致 ω i j {{\omega _{ij}}} ωij无法通过训练得到。
为了求出 ω i j {{\omega _{ij}}} ωij,我们对每一个特征分量xi引入辅助向量 V i = ( v i 1 , v i 2 , ⋯ , v i k ) {V_i} = \left( {{v_{i1}},{v_{i2}}, \cdots ,{v_{ik}}} \right) Vi=(vi1,vi2,⋯,vik)。然后利用 v i v j T {v_i}v_j^T vivjT对 ω i j {{\omega _{ij}}} ωij进行求解。

那么 ω i j {{\omega _{ij}}} ωij组成的矩阵可以表示为:
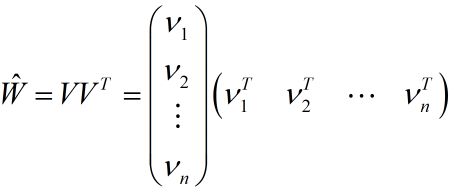
求解 v i {v_i} vi和 v j {v_j} vj的具体过程如下:
∑ i = 1 n − 1 ∑ j = i + 1 n ⟨ ν i , ν j ⟩ x i x j = 1 2 ∑ i = 1 n ∑ j = 1 n ⟨ ν i , ν j ⟩ x i x j − 1 2 ∑ i = 1 n ⟨ ν i , ν i ⟩ x i x i = 1 2 ( ∑ i = 1 n ∑ j = 1 n ∑ f = 1 k v i , f v j , f x i x j − ∑ i = 1 n ∑ f = 1 k v i , f v j , f x i ) = 1 2 ∑ f = 1 k ( ( ∑ i = 1 n v i , f x i ) ( ∑ j = 1 n v j , f x j ) − ∑ i = 1 n v i , f 2 x i 2 ) = 1 2 ∑ f = 1 k ( ( ∑ i = 1 n v i , f x i ) 2 − ∑ i = 1 n v i , f 2 x i 2 ) \begin{array}{l} \sum\limits_{i = 1}^{n - 1} {\sum\limits_{j = i + 1}^n {\left\langle {{\nu _i},{\nu _j}} \right\rangle {x_i}{x_j}} } \\ = \frac{1}{2}\sum\limits_{i = 1}^n {\sum\limits_{j = 1}^n {\left\langle {{\nu _i},{\nu _j}} \right\rangle {x_i}{x_j}} } - \frac{1}{2}\sum\limits_{i = 1}^n {\left\langle {{\nu _i},{\nu _i}} \right\rangle {x_i}{x_i}} \\ = \frac{1}{2}\left( {\sum\limits_{i = 1}^n {\sum\limits_{j = 1}^n {\sum\limits_{f = 1}^k {{v_{i,f}}{v_{j,f}}{x_i}{x_j}} - \sum\limits_{i = 1}^n {\sum\limits_{f = 1}^k {{v_{i,f}}{v_{j,f}}{x_i}} } } } } \right)\\ = \frac{1}{2}\sum\limits_{f = 1}^k {\left( {\left( {\sum\limits_{i = 1}^n {{v_{i,f}}{x_i}} } \right)\left( {\sum\limits_{j = 1}^n {{v_{j,f}}{x_j}} } \right) - \sum\limits_{i = 1}^n {v_{i,f}^2x_i^2} } \right)} \\ = \frac{1}{2}\sum\limits_{f = 1}^k {\left( {{{\left( {\sum\limits_{i = 1}^n {{v_{i,f}}{x_i}} } \right)}^2} - \sum\limits_{i = 1}^n {v_{i,f}^2x_i^2} } \right)} \end{array} i=1∑n−1j=i+1∑n⟨νi,νj⟩xixj=21i=1∑nj=1∑n⟨νi,νj⟩xixj−21i=1∑n⟨νi,νi⟩xixi=21(i=1∑nj=1∑nf=1∑kvi,fvj,fxixj−i=1∑nf=1∑kvi,fvj,fxi)=21f=1∑k((i=1∑nvi,fxi)(j=1∑nvj,fxj)−i=1∑nvi,f2xi2)=21f=1∑k((i=1∑nvi,fxi)2−i=1∑nvi,f2xi2)
梯度
FM有一个重要的性质:multilinearity:若 Θ = ( ω 0 , ω 1 , ω 2 , ⋯ , ω n , v 11 , v 12 , ⋯ , v n k ) \Theta = \left( {{\omega _0},{\omega _1},{\omega _2}, \cdots ,{\omega _n},{v_{11}},{v_{12}}, \cdots ,{v_{nk}}} \right) Θ=(ω0,ω1,ω2,⋯,ωn,v11,v12,⋯,vnk)表示FM模型的所有参数,则对于任意的 θ ∈ Θ \theta \in \Theta θ∈Θ,存在与 θ \theta θ无关的 g ( x ) g\left( x \right) g(x)与 h ( x ) h\left( x \right) h(x),则二阶多项式模型可以表示为:
f ( x ) = g ( x ) + θ h ( x ) f\left( x \right) = g\left( x \right) + \theta h\left( x \right) f(x)=g(x)+θh(x)
从上式可以看到,如果我们得到了 g ( x ) g\left( x \right) g(x)与 h ( x ) h\left( x \right) h(x),则对于参数 θ \theta θ的梯度为 h ( x ) h\left( x \right) h(x)。
- 当 θ = ω 0 \theta = {\omega _0} θ=ω0时,则:
f ( x ) = ∑ i = 1 n ω i x i + ∑ i = 1 n − 1 ∑ j = i + 1 n ( V i T V j ) x i x j + ω 0 × 1 f\left( x \right) = \sum\limits_{i = 1}^n {{\omega _i}{x_i}} + \sum\limits_{i = 1}^{n - 1} {\sum\limits_{j = i + 1}^n {\left( {V_i^T{V_j}} \right){x_i}{x_j}} } + {\omega _0} \times 1 f(x)=i=1∑nωixi+i=1∑n−1j=i+1∑n(ViTVj)xixj+ω0×1
最后一项1为 h ( x ) h\left( x \right) h(x),其余项为 g ( x ) g\left( x \right) g(x)。可以看出此时的梯度为1。 - 当 θ = ω l , l ∈ ( 1 , 2 , ⋯ , n ) \theta = {\omega _l},l \in \left( {1,2, \cdots ,n} \right) θ=ωl,l∈(1,2,⋯,n)时,
f ( x ) = ω 0 + ∑ i = 1 n ω i x i + ∑ i = 1 n − 1 ∑ j = i + 1 n ( V i T V j ) x i x j + ω l × x l f\left( x \right) = {\omega _0} + \sum\limits_{i = 1}^n {{\omega _i}{x_i}} + \sum\limits_{i = 1}^{n - 1} {\sum\limits_{j = i + 1}^n {\left( {V_i^T{V_j}} \right){x_i}{x_j}} } + {\omega _l} \times {x_l} f(x)=ω0+i=1∑nωixi+i=1∑n−1j=i+1∑n(ViTVj)xixj+ωl×xl
此时梯度为 x l {x_l} xl - θ = v l m \theta = {v_{lm}} θ=vlm时
f ( x ) = ω 0 + ∑ i = 1 n ω i x i + ∑ i = 1 n − 1 ∑ j = i + 1 n ( ∑ s = 1 , i s ≠ l m , j s ≠ l m k v i s v j s ) x i x j + v l m × x l ∑ i ≠ l v i m x i f\left( x \right) = {\omega _0} + \sum\limits_{i = 1}^n {{\omega _i}{x_i}} + \sum\limits_{i = 1}^{n - 1} {\sum\limits_{j = i + 1}^n {\left( {\sum\limits_{s = 1,is \ne lm,js \ne lm}^k {{v_{is}}{v_{js}}} } \right){x_i}{x_j}} } + {v_{lm}} \times {x_l}\sum\limits_{i \ne l} {{v_{im}}{x_i}} f(x)=ω0+i=1∑nωixi+i=1∑n−1j=i+1∑n⎝⎛s=1,is=lm,js=lm∑kvisvjs⎠⎞xixj+vlm×xli=l∑vimxi
此时梯度为 x l ∑ i ≠ l v i m x i {x_l}\sum\limits_{i \ne l} {{v_{im}}{x_i}} xli=l∑vimxi。
综上, f ( x ) f\left( x \right) f(x)关于 θ \theta θ的偏导数为:
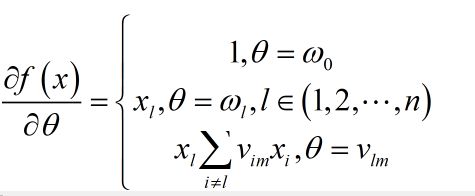
更详细的推导过程请看文章。
三、FM代码
1、数据集
本文使用的数据集为MovieLens100k Datase,数据包括四列,分别是用户ID,电影ID,打分,时间戳。
2、数据处理
要使用FM模型,我们首先要将数据处理成一个矩阵,矩阵的大小是用户数 * 电影数。使用的是scipy.sparse中的csr.csr_matrix实现这个矩阵。
函数形式如下csr_matrix((data, indices, indptr)
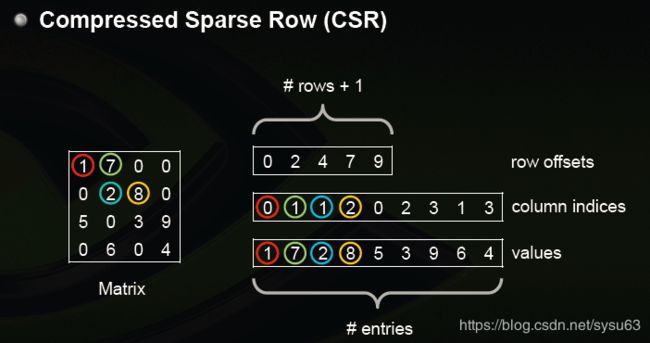
可以看到,函数接收三个参数,
第一个参数是数值(也就是图中的values)
第二个参数是每个数对应的列号(也就是图中的column indices)
第三个参数是每行的起始的偏移量(也就是图中的row offsets)
图中的例子,row offsets的前rows个元素代表每一行的第一个非零元素在values中的位置。第一行的第一个非零元素在values的位置为0,也就是1,第二行的第一个非零元素在values的位置为2,也就是2,以此类推。因此第一行有两个非零元素1,7,他们在行中的位置对应为column indices的0,1。
数据处理的代码
def vectorize_dic(dic,ix=None,p=None,n=0,g=0):
'''
:params:dic,特征列表字典,关键字是特征名
:params:ix,索引
:params:p,特征向量的维度
'''
if ix == None:
ix = dict()
nz = n * g
col_ix = np.empty(nz,dtype = int)#随机生成一个大小为nz的数组,元素为整数
i = 0
#dict.get(k,d),dict[k] if dict[k] else d
for k,lis in dic.items():
#users和users的list,或者是items和items的list
for t in range(len(lis)):
#为编号为t的user或者item赋值
ix[str(lis[t]) + str(k)] = ix.get(str(lis[t]) + str(k),0) + 1
col_ix[i + t * g] = ix[str(lis[t]) + str(k)]
i += 1
row_ix = np.repeat(np.arange(0,n),g)#np.repeat(np.arange(0,3),2):[0 0 1 1 2 2]
data = np.zeros(nz)
if p == None:
p = len(ix)
ixx = np.where(col_ix < p)
return csr.csr_matrix((data[ixx],(row_ix[ixx],col_ix[ixx])),shape=(n,p)),ix
分批次训练模型
def batcher(X_,y_=None,batch_size=-1):
n_samples = X_.shape[0]
if batch_size == -1:
batch_size = n_samples
if batch_size < 1:
raise ValueError("参数batch_size={}是不支持的".format(batch_size))
for i in range(0,n_samples,batch_size):
upper_bound = min(i + batch_size,n_samples)
ret_x = X_[i:upper_bound]
ret_y = None
if y_ is not None:
ret_y = y_[i:i + batch_size]
yield (ret_x,ret_y)
构建模型
x = tf.placeholder('float',[None,p])
y = tf.placeholder('float',[None,1])
w0 = tf.Variable(tf.zeros([1]))
w = tf.Variable(tf.zeros([p]))
v = tf.Variable(tf.random_normal([k,p],mean=0,stddev=0.01))
linear_terms = tf.add(w0,tf.reduce_sum(tf.multiply(w,x),1,keep_dims=True))
pair_interactions = 0.5 * tf.reduce_sum(tf.subtract(
tf.pow(tf.matmul(x,tf.transpose(v)),2),
tf.matmul(tf.pow(x,2),tf.transpose(tf.pow(v,2)))
),axis=1,keep_dims=True)
y_hat = tf.add(linear_terms,pair_interactions)
lambda_w = tf.constant(0.001,name='lambda_w')
lambda_v = tf.constant(0.001,name='lambda_v')
l2_norm = tf.reduce_sum(tf.add(
tf.multiply(lambda_w,tf.pow(w,2)),
tf.multiply(lambda_v,tf.pow(v,2))
))
error = tf.reduce_mean(tf.square(y - y_hat))
loss = tf.add(error,l2_norm)
train_op = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(loss)