caffe的googlenet模型使用
首先从网上下载imagenet训练好的模型,模型下载地址
http://dl.caffe.berkeleyvision.org/bvlc_googlenet.caffemodel
可以把模型放入/caffe-master/models/bvlc_googlenet/目录下
bvlc_googlenet目录就是官方提供的googlenet模型,可以训练或者直接使用googlenet模型。
可以在这个文件夹中新建一个image文件夹,存放要检测的照片。
然后就是编写一个test.py测试程序,程序如下:
#coding=utf-8
import numpy as np
import matplotlib.pyplot as plt
import os
import PIL
from PIL import Image
caffe_root = '/home/grid/caffe-master/'
import sys
sys.path.insert(0,caffe_root+'python')
import caffe
MODEL_FILE =caffe_root+'models/bvlc_googlenet/deploy.prototxt'
PRETRAINED =caffe_root+'models/bvlc_googlenet/bvlc_googlenet.caffemodel'
#cpu模式
caffe.set_mode_cpu()
#定义使用的神经网络模型
net = caffe.Classifier(MODEL_FILE,PRETRAINED,
mean=np.load(caffe_root +'python/caffe/imagenet/ilsvrc_2012_mean.npy').mean(1).mean(1),
channel_swap=(2,1,0),
raw_scale=255,
image_dims=(224, 224))
imagenet_labels_filename = caffe_root +'data/ilsvrc12/synset_words.txt'
labels =np.loadtxt(imagenet_labels_filename, str, delimiter='\t')
#对目标路径中的图像,遍历并分类
for root,dirs,files inos.walk("/home/grid/caffe-master/models/bvlc_googlenet/image/"):
for file in files:
#加载要分类的图片
IMAGE_FILE = os.path.join(root,file).decode('gbk').encode('utf-8');
input_image = caffe.io.load_image(IMAGE_FILE)
#预测图片类别
prediction = net.predict([input_image])
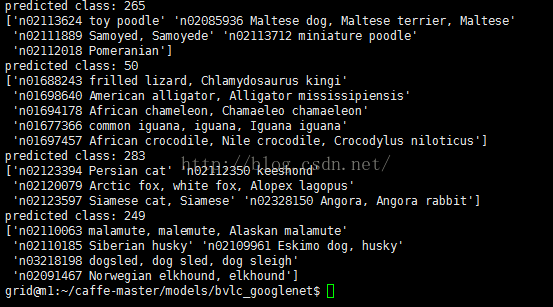
print 'predicted class:',prediction[0].argmax()
# 输出概率最大的前5个预测结果
top_k = net.blobs['prob'].data[0].flatten().argsort()[-1:-6:-1]
print labels[top_k]
然后执行程序python test.py
输入预测结果: