独家连载 | 覃秉丰深度学习重磅新书首发抢读!!!(2)
前言:大家好,我是覃秉丰,又和大家见面了。之前我发布了关于我的《深度学习从0到1》的新书首读。鉴于大家的反响都比较热烈,所以我决定继续连载,希望给每个深度学习的践行者带来一点小小的帮助和启发。
1.3深度学习应用
深度学习最早兴起于图像识别,在最近几年可以说是已经深入各行各业。深度学习在计算机视觉,语音识别,自然语言处理,机器人控制,生物信息,医疗,法律,金融,推荐系统,搜索引擎,电脑游戏,娱乐等领域均有应用。
图像识别——图像识别可以说是深度学习最早实现突破性成就的领域。如今计算机对图片的识别能力已经跟人类不相上下。我们把一张图片输入神经网络,经过网络的运算,最后可以得到图片的分类。如图1.15所示,我们可以看到每一张图片神经网络都给出了5个最有可能的分类,排在最上面的可能性最大。
目标检测 —— 利用深度学习我们还可以识别图片中的特定物体,然后对该物体进行标注,如图1.16。

人脸识别 —— 深度学习还可以识别图像中的人脸,判断是男人还是女人,判断人的年龄,判断图像中的人是谁等,如图1.17。

描述图片 —— 把一张图片输入神经网络中,就可以输出对这张图片的文字描述,如图1.18。

图片风格转换 —— 利用深度学习实现一张图片加上另一张图片的风格,然后生成一张新的图片,如图1.19。

语音识别 —— 深度学习还可以用来识别人说的话,如图1.20。
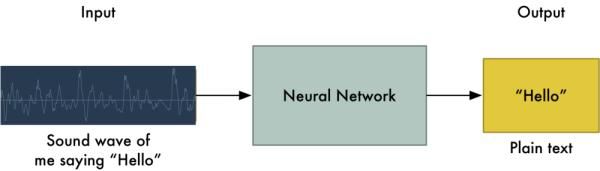
文本分类 —— 使用深度学习对多个文本进行分类,如图1.21。
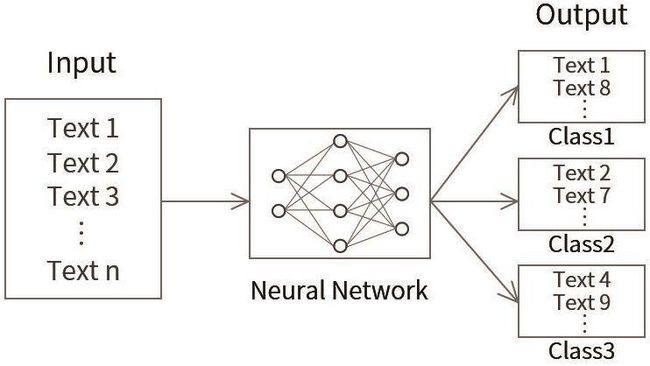
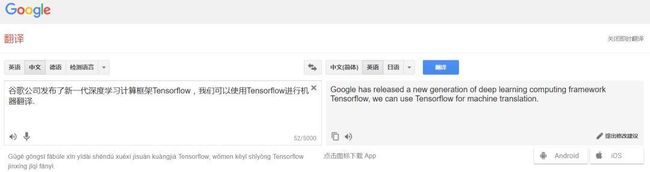
机器翻译 —— 使用深度学习进行机器翻译,如图1.22。
诗词生成 —— 把一个诗词的题目传入神经网络,就可以生成一篇诗词,如图1.23。

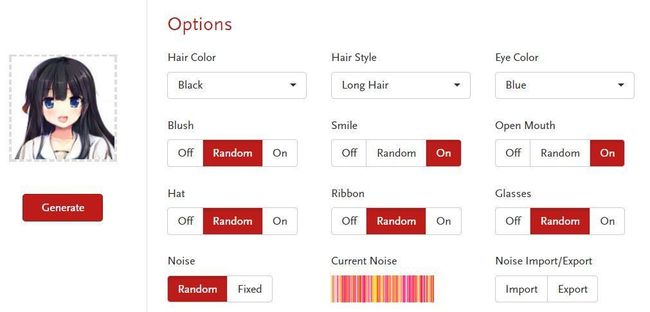
图像生成 —— 深度学习还可以用来生成图片。如下图所示,只要设置好动漫人物的头发颜色,头发长度,眼睛颜色,是否戴帽子等信息就可以生成符合条件的动漫人物。并且可以生成无数张不重复的照片,如图1.24。
这里只是列举了非常少量的例子,深度学习的已经逐渐深入各行各业,深入我们的生活中。
1.4 神经网络发展史
神经网络的发展历史中有过三次热潮,分别发展在20世纪40年代到60年代,20世纪80年代到90年代,以及2006年至今。每一次神经网络的热潮都伴随着人工智能的兴起,人工智能和神经网络一直以来都有着非常密切的关系。
1.4.1 神经网络诞生—20世纪40-60年代
1943年,神经病学家和神经元解剖学家W.S.McCulloch和数学家W.A.Pitts在生物物理学期刊发表文章提出神经元的数学描述和结构。并且证明了只要有足够的简单神经元,在这些神经元互相连接并同步运行的情况下,可以模拟任何计算函数,这种神经元的数学模型称为M-P模型。
该模型把神经元的动作描述为:
- 1.神经元的活动表现为兴奋或抑制的二值变化;
- 2.任何兴奋性突触输入激励后,使神经元兴奋;
- 3.任何抑制性突触有输入激励后,使神经元抑制;
- 4.突触的值不随时间改变;
- 5.突触从感知输入到传送出一个输出脉冲的延时时间是0.5ms。
尽管现在看来M-P模型过于简单,并且观点也不是完全正确,不过这个模型被认为是第一个仿生学的神经网络模型,他们提出的很多观点一直沿用至今,比如说他们认为神经元有两种状态,要不就是兴奋,要不就是抑制。这跟后面要提到的单层感知器非常类似,单层感知器的输出要不就是0要不就是1。他们最重要的贡献就是开创了神经网络这个研究方向,为今天神经网络的发展奠定了基础。
1949年,另一位心理学家Donald Olding Hebb在他的一本名为《行为构成》(Organization of Behavior)的书提出了Hebb算法。他也是首先提出“连接主义”(connectionism)这一名词的人之一,这个名词的含义是大脑的活动是靠脑细胞的组合连接实现的。
Hebb认为,如果源和目的神经元均被激活兴奋时,它们之间突触的连接强度将会增强。他指出在神经网络中,信息存储在连接权值中。并提出假设神经元A到神经元B连接权与从B到A的连接权是相同的。
他这里提到的这个权值的思想也被应用到了我们目前所使用的神经网络中,我们通过调节神经元之间的连接权值来得到不同的神经网络模型,实现不同的应用。虽然这些理论在今天看来是理所当然的,不过在当时看来这是一种全新的想法,算得上是开创性的理论。
1958年,计算机学家Frank Rosenblatt提出了一种具有三层网络特性的神经网络结构,称为感知器(Perceptron)。他提出的这个感知器可能是世界上第一个真正意义上的人工神经网络。感知器提出之后在60年代就掀起了神经网络研究的第一次热潮。很多人都认为只要使用成千上万的神经元,他们就能解决一切问题。现在看来可能会让人感觉too young too naive,不过感知器在当时确实是影响非凡。
这股感知器热潮持续了10年,直到1969年,人工智能的创始人之一的M.Minsky和S.Papert出版了一本名为《感知器》的书,书中指出简单神经网络只能运用于线性问题的求解,能够求解非线性问题的网络应具有隐层,而从理论上还不能证明将感知器模型扩展到多层网络是有意义的。
由于Minsky在学术界的地位和影响,其悲观论点极大地影响了当时的人工神经网络研究,为刚刚燃起希望之火的人工神经网络泼了一大盘冷水。这本书出版不不久之后,几乎所有为神经网络提供的研究基金都枯竭了,没有人愿意把钱浪费在没有意义的事情上。
1.4.2神经网络复兴—20世纪80-90年代
1982年,美国加州理工学院的优秀物理学家John J.Hopfield博士提出了Hopfield神经网络。Hopfield神经网络引用了物理力学的分析方法,把网络作为一种动态系统并研究这种网络动态系统的稳定性。
1985年,G.E.Hinton和T.J.Sejnowski借助统计物理学的概念和方法提出了一种随机神经网络模型——玻尔兹曼机(Boltzmann Machine)。一年后他们又改进了模型,提出了受限玻尔兹曼机(Restricted Boltzmann Machine)。
1986年,Rumelhart,Hinton,Williams发展了BP(Back Propagation)算法(多层感知器的误差反向传播算法)。到今天为止,这种多层感知器的误差反向传播算法还是非常基础的算法,凡是学神经网络的人,必然要学习BP算法。我们现在的深度网络模型基本上都是在这个算法的基础上发展出来的。不过BP神经网络的神经元层数不能太多,一旦网络层数过多,就会出现梯度消失问题,使得网络再也无法训练。具体原因在后面的章节中会详细说明。
注:Hopfield神经网络,玻尔兹曼机以及受限玻尔兹曼机由于目前已经较少使用,所以本书后面章节不再详细介绍这三种网络。
1.4.3 深度学习—2006年至今
2006年,多伦多大学的教授Geoffrey Hinton提出了深度学习。他在世界顶级学术期刊《科学》上发表了一篇论文(Reducing the dimensionality of data with neural networks)[1],论文中提出了两个观点:
-
多层人工神经网络模型有很强的特征学习能力,深度学习模型学习得到的特征数据对原始数据有更本质的代表性,这将大大便于分类和可视化问题;
-
对于深度神经网络很难训练达到最优的问题,可以采用逐层训练方法解决。将上层训练好的结果作为下层训练过程中的初始化参数。在这一文献中深度模型的训练过程中逐层初始化采用无监督学习方式。
Hinton在论文中提出了一种新的网络结构深度置信网(Deep Belief Net:DBN),这种网络使得训练深层的神经网络成为可能。
注:深度置信网络由于目前已经较少使用,所以本书后面章节不再详细介绍这种网络。
2012年,Hinton课题组为了证明深度学习的潜力,首次参加ImageNet图像识别比赛,通过CNN网络AlexNet一举夺得冠军。也正是由于该比赛,CNN吸引了众多研究者的注意。
2014年,香港中文大学教授汤晓鸥领导的计算机视觉研究组开发了名为DeepID的深度学习模型, 在LFW (Labeled Faces in the Wild,人脸识别使用非常广泛的测试基准)数据库上获得了99.15%的识别率,人用肉眼在LFW上的识别率为97.52%,深度学习在学术研究层面上已经超过了人用肉眼的识别。
2016年3月人工智能围棋比赛,由位于英国伦敦的谷歌(Google)旗下DeepMind公司的开发的AlphaGo战胜了世界围棋冠军、职业九段选手李世石,并以4:1的总比分获胜。
作者介绍:
