独家连载 | 误差反向传播算法推导
4.5 BP网络模型和公式推导
4.5.1BP网络模型
假设我们有一个2层(统计神经网络层数的时候一般输入层忽略不计)的神经网络如图4.17所示:
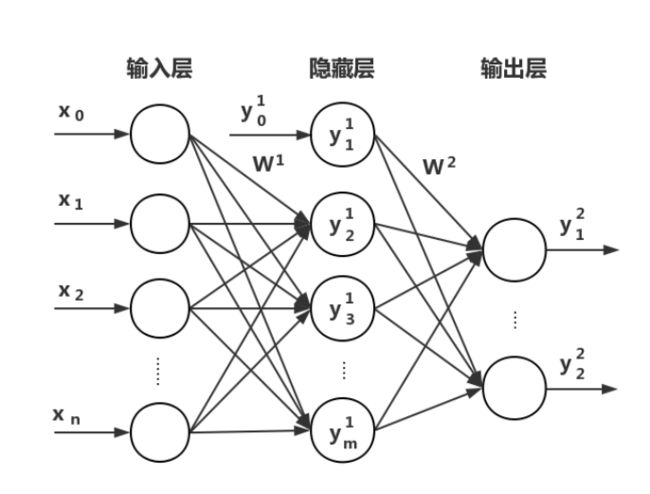
该网络的输入向量为X = (x1,x2,…,xi,…,xn),图中x0 = 1表示输入层偏置值。隐藏层输出向量为 Y 1 = ( y 1 1 , y 2 1 , … , y j 1 , … , y m 1 ) Y^1=( y_1^1,y_2^1,\ldots,y_j^1,\ldots,y_m^1) Y1=(y11,y21,…,yj1,…,ym1),图中 y 0 1 = 1 y^1_0=1 y01=1表示隐藏层偏置值。输出层输出向量为 Y 2 = ( y 1 2 , y 2 2 , … , y k 2 , … , y l 2 ) Y^2=( y_1^2,y_2^2,\ldots,y_k^2,\ldots,y_l^2) Y2=(y12,y22,…,yk2,…,yl2)。期望输出 T = ( t 1 , t 2 , … , t k , … , t l ) T=(t_1,t_2,\ldots,t_k,\ldots,t_l) T=(t1,t2,…,tk,…,tl)。输入层到隐藏层之间的权值用矩阵W1表示,W1ij表示W1矩阵中第i行第j列的权值。隐藏层到输出层之间的权值用矩阵W2表示,W2jk表示W2矩阵中第j行第k列的权值。另外我们定义net1为隐藏层中权值乘以输入层信号的总和,net1j表示隐藏层中第j个神经元得到的输入信号总和。net2为输出层中权值乘以隐藏层信号的总和,net2k表示输出层中第k个神经元得到的输入信号总和。
对于隐藏层有:
n e t j 1 = ∑ i = 0 n w i j 1 x i ; ( j = 1 , 2 , . . . , m ) net_j^1=\sum_{i=0}^{n} {w^1_{ij}x_i} ;(j=1,2,...,m) netj1=∑i=0nwij1xi;(j=1,2,...,m)
y j 1 = f ( n e t j 1 ) ; ( j = 1 , 2 , . . . , m ) y_j^1=f(net_j^1);(j=1,2,...,m) yj1=f(netj1);(j=1,2,...,m)
对于输出层有:
n e t k 2 = ∑ i = 0 n w j k 2 y j 1 ; ( k = 1 , 2 , . . . , l ) net_k^2=\sum_{i=0}^{n} {w^2_{jk}y_j^1};(k=1,2,...,l) netk2=∑i=0nwjk2yj1;(k=1,2,...,l)
KaTeX parse error: \tag works only in display equations
公式4.13和4.15中的激活函数假设我们都使用sigmoid函数,sigmoid函数的公式在上文中的公式4.8。sigmoid函数具有连续、可导的特点,它的导数为:
f ′ ( x ) = f ( x ) [ 1 − f ( x ) ] f'(x)=f(x)[1-f(x)] f′(x)=f(x)[1−f(x)]
4.5.2BP算法推导
根据上文中提到的代价函数,当网络输出与期望输出不同时,会存在输出误差E,为了简单我们只计算一个样本的均方差公式,如果是计算多个样本可以求所有样本代价函数的平均值。一个样本的均方差公式定义如下:
E = 1 2 ( T − Y 2 ) 2 = 1 2 ∑ k = 1 l ( t k − y k 2 ) 2 E=\frac {1} {2}(T-Y^2)^2=\frac {1} {2}\sum_{k=1}^{l} {(t_k-y_k^2)^2} E=21(T−Y2)2=21k=1∑l(tk−yk2)2
将以上误差定义式展开至隐藏层:
E = 1 2 ∑ k = 1 l [ t k − f ( n e t k 2 ) ] 2 = 1 2 ∑ k = 1 l [ t k − f ( ∑ j = 0 m w j k 2 y j 1 ) ] 2 E=\frac {1} {2}\sum_{k=1}^{l} {[t_k-f(net_k^2)]^2}=\frac {1} {2}\sum_{k=1}^{l} { \left [t_k-f\left(\sum_{j=0}^{m}{w_{jk}^2}y_j^1 \right)\right]^2} E=21k=1∑l[tk−f(netk2)]2=21k=1∑l[tk−f(j=0∑mwjk2yj1)]2
再进一步展开至输入层:
E = 1 2 ∑ k = 1 l [ t k − f ( ∑ j = 0 m w j k 2 f ( n e t j 1 ) ) ] 2 = 1 2 ∑ k = 1 l [ t k − f ( ∑ j = 0 m w j k 2 f ( ∑ j = 0 m w i j 1 x i ) ) ] 2 E=\frac {1} {2}\sum_{k=1}^{l} { \left [t_k-f\left(\sum_{j=0}^{m}{w_{jk}^2}f(net_j^1)\right)\right]^2}=\frac {1} {2}\sum_{k=1}^{l} { \left [t_k-f\left(\sum_{j=0}^{m}{w_{jk}^2}f\left(\sum_{j=0}^{m}{w_{ij}^1x_i}\right)\right)\right]^2} E=21k=1∑l[tk−f(j=0∑mwjk2f(netj1))]2=21k=1∑l[tk−f(j=0∑mwjk2f(j=0∑mwij1xi))]2
从公式4.18和4.19中可以看出,网络的误差E是跟神经网络各层权值W1ij和W2jk相关的,因此调整各层的权值,就可以改变误差E的值。我们的目标就是要得到比较小的误差值,所以我们可以采用梯度下降法来最小化误差E的值。根据梯度下降法,我们可以得到:
Δ w i j 1 = − η δ E δ w i j 1 \Delta w_{ij}^1=-\eta\frac {\delta E} {\delta w_{ij}^1} Δwij1=−ηδwij1δE
i = 0 , 1 , 2 , … , n ; j = 1 , 2 , … , m i=0,1,2,\ldots,n;j=1,2,\ldots,m i=0,1,2,…,n;j=1,2,…,m
Δ w i j 2 = − η δ E δ w j k 2 \Delta w_{ij}^2=-\eta\frac {\delta E} {\delta w_{jk}^2 } Δwij2=−ηδwjk2δE
j = 0 , 1 , 2 , … , m ; k = 1 , 2 , … , l j=0,1,2,\ldots,m;k=1,2,\ldots,l j=0,1,2,…,m;k=1,2,…,l
在下面的推导过程中均默认对于隐藏层有i =0,1,2,…,n;j = 1,2,…,m;对于输出层有:j =0,1,2,…,m;k = 1,2,…,l。
根据微积分的链式法则可以得到,对于隐藏层有:
Δ w i j 1 = − η δ E δ w i j 1 = − η δ E δ n e t j 1 δ n e t j 1 δ w i j 1 \Delta w_{ij}^1=-\eta\frac {\delta E} {\delta w_{ij}^1 }=-\eta\frac {\delta E} {\delta net_j^1 }\frac {\delta net_j^1 } {\delta w_{ij}^1 } Δwij1=−ηδwij1δE=−ηδnetj1δEδwij1δnetj1
根据微积分的链式法则可以得到,对于输出层有:
Δ w j k 2 = − η δ E δ w j k 2 = − η δ E δ n e t k 2 δ n e t k 2 δ w j k 2 \Delta w_{jk}^2=-\eta\frac {\delta E} {\delta w_{jk}^2 }=-\eta\frac {\delta E} {\delta net_k^2 }\frac {\delta net_k^2 } {\delta w_{jk}^2 } Δwjk2=−ηδwjk2δE=−ηδnetk2δEδwjk2δnetk2
我们可以定义一个误差信号,命名为δ(delta),令:
δ j 1 = − δ E δ n e t j 1 \delta_j^1=-\frac {\delta E} {\delta net_j^1 } δj1=−δnetj1δE
δ k 1 = − δ E δ n e t k 2 \delta_k^1=-\frac {\delta E} {\delta net_k^2 } δk1=−δnetk2δE
综合公式4.12,4.22,4.24,可以得到输入层到隐藏层的权值调整公式为:
Δ w i j 1 = η δ j 1 x i \Delta w_{ij}^1=\eta\delta_j^1x_i Δwij1=ηδj1xi
综合公式4.14,4.23,4.25,可以得到隐藏层到输出层的权值调整公式为:
Δ w j k 2 = η δ k 2 y j 1 \Delta w_{jk}^2=\eta\delta_k^2y_j^1 Δwjk2=ηδk2yj1
可以看出在公式4.26和4.27中,只要求出δ1j和δ2k的值,就可以计算出Δw1ij和Δw2jk的值了。
对于隐藏层,δ1j可以展开为:
δ j 1 = − δ E δ n e t j 1 = − δ E δ y j 1 δ y j 1 δ n e t j 1 = − δ E δ y j 1 f ′ ( n e t j 1 ) \delta_j^1=-\frac {\delta E} {\delta net_j^1 }=-\frac {\delta E} {\delta y_j^1 }\frac {\delta y_j^1} {\delta net_j^1 }=-\frac {\delta E} {\delta y_j^1 }f'(net_j^1) δj1=−δnetj1δE=−δyj1δEδnetj1δyj1=−δyj1δEf′(netj1)
对于输出层,δ2k可以展开为:
δ k 2 = − δ E δ n e t k 2 = − δ E δ y k 2 δ y k 2 δ n e t k 2 = − δ E δ y k 2 f ′ ( n e t k 2 ) \delta_k^2=-\frac {\delta E} {\delta net_k^2 }=-\frac {\delta E} {\delta y_k^2 }\frac {\delta y_k^2} {\delta net_k^2 }=-\frac {\delta E} {\delta y_k^2 }f'(net_k^2) δk2=−δnetk2δE=−δyk2δEδnetk2δyk2=−δyk2δEf′(netk2)
在公式4.28和4.29中,求网络误差对各层输出的偏导,对于输出层:
δ E δ y k 2 = − ( t k − y k 2 ) \frac {\delta E} {\delta y_k^2 }=-(t_k-y_k^2) δyk2δE=−(tk−yk2)
对于隐藏层:
δ E δ y j 1 = δ 1 2 ∑ k = 1 l [ t k − f ( ∑ j = 0 m w j k 2 y j 1 ) ] 2 δ y j = − ∑ k = 1 l ( t k − f ( ∑ j = 0 m w j k 2 y j 1 ) ) f ′ ( ∑ j = 0 m w j k 2 y j 1 ) w j k 2 = − ∑ k = 1 l ( t k − y k 2 ) f ′ ( n e t k 2 ) w j k 2 \frac{δE}{δy^1_j}=\frac{δ\frac{1}{2}\sum_{k=1}^{l}{[t_k-f(\sum_{j=0}^{m}{w^2_{jk}y^1_j})]^2}}{δy_j}=-\sum_{k=1}^{l}{\left(t_k-f\left(\sum_{j=0}^{m}{w^2_{jk}y^1_j}\right)\right)f'\left(\sum_{j=0}^{m}{w^2_{jk}y^1_j}\right)w^2_{jk}=-\sum_{k=1}^{l}{(t_k-y^2_k)f'(net^2_k)w^2_{jk}}} δyj1δE=δyjδ21∑k=1l[tk−f(∑j=0mwjk2yj1)]2=−∑k=1l(tk−f(∑j=0mwjk2yj1))f′(∑j=0mwjk2yj1)wjk2=−∑k=1l(tk−yk2)f′(netk2)wjk2
将公式4.30带入公式4.29,再根据sigmoid函数的求导公式4.16,可以得到:
δ k 2 = − δ E δ y k 2 f ′ ( n e t k 2 ) = ( t k − y k 2 ) y k 2 ( 1 − y k 2 ) δ^2_k=-\frac{δE}{δy^2_k}f'(net^2_k)=(t_k-y^2_k)y^2_k(1-y^2_k) δk2=−δyk2δEf′(netk2)=(tk−yk2)yk2(1−yk2)
δ j 1 = − δ E δ y j f ′ ( n e t j 1 ) = ( ∑ k = 1 l ( t k − y k 2 ) f ′ ( n e t k 2 ) w j k 2 ) f ′ ( n e t j 1 ) = ( ∑ k = 1 l ( t k − y k 2 ) y k 2 ( 1 − y k 2 ) w j k 2 ) f ′ ( n e t j 1 ) = ( ∑ k = 1 l δ k 2 w j k 2 ) y j 1 ( 1 − y j 1 ) δ^1_j=-\frac{δE}{δy_j}f'(net^1_j)=\left(\sum_{k=1}^{l} {(t_k-y^2_k)f'(net^2_k)w^2_{jk}}\right)f'(net^1_j)=\left(\sum_{k=1}^l{(t_k-y^2_k)y^2_k(1-y^2_k)w^2_{jk}}\right)f'(net^1_j)=\left(\sum_{k=1}^{l}{δ^2_kw^2_{jk}}\right)y^1_j(1-y^1_j) δj1=−δyjδEf′(netj1)=(∑k=1l(tk−yk2)f′(netk2)wjk2)f′(netj1)=(∑k=1l(tk−yk2)yk2(1−yk2)wjk2)f′(netj1)=(∑k=1lδk2wjk2)yj1(1−yj1)
将公式4.32带入4.27中,得到隐藏层到输出层权值调整:
Δ w j k 2 = η δ k 2 y j 1 = η ( t k − y k 2 ) y k 2 ( 1 − y k 2 ) y j 1 Δw^2_{jk}=ηδ^2_ky^1_j=η(t_k-y^2_k)y^2_k(1-y^2_k)y^1_j Δwjk2=ηδk2yj1=η(tk−yk2)yk2(1−yk2)yj1
将公式4.33带入4.26中,得到输入层到隐藏层权值调整:
Δ w i j 1 = η δ j 1 x i = η ( ∑ k = 1 l δ k 2 w j k 2 ) y j 1 ( 1 − y j 1 ) x i Δw^1_{ij}=ηδ^1_jx_i=η\left(\sum_{k=1}^{l} {δ^2_kw^2_{jk}}\right)y^1_j(1-y^1_j)x_i Δwij1=ηδj1xi=η(∑k=1lδk2wjk2)yj1(1−yj1)xi
对于一个多层的神经网络,假设一共有h个隐藏层,按顺序将各隐藏层节点数分别记为:m1,m2,…,mh,输入神经元个数为n,输出神经元个数为l;各隐藏层输出分别记为:Y1,Y2,…,Yh,输入层的输入记为:X,输出层的输出记为:Yh+1;各层权值矩阵分别记为:W1,W2,…,Wh+1,W1表示输入层到一个隐藏层的权值矩阵,Wh+1表示最后一个隐藏层到输出层的权值矩阵;各层学习信号分别记为:δ1,δ2,…,δh+1,δh+1表示输出层计算出的学习信号;则各层权值调整计算公式为(如下分类)
对于输出层:
Δ w j k h + 1 = η δ k h + 1 y j h = η ( t k − y k h + 1 ) y k h + 1 ( 1 − y k h + 1 ) y j h ( j = 0 , 1 , 2 , . . . , m h ; k = 1 , 2 , . . . , l ) Δw^{h+1}_{jk}=ηδ^{h+1}_ky^h_j=η(t_k-y^{h+1}_k)y^{h+1}_k(1-y^{h+1}_k)y^h_j (j=0,1,2,...,m_h;k=1,2,...,l) Δwjkh+1=ηδkh+1yjh=η(tk−ykh+1)ykh+1(1−ykh+1)yjh(j=0,1,2,...,mh;k=1,2,...,l)
对于第h隐藏层:
Δ w i j h = η δ j h y i h − 1 = η ( ∑ k = 1 l δ k h + 1 w j k h + 1 ) y j h ( 1 − y j h ) y j h − 1 ( i = 0 , 1 , 2 , . . . , m h − 1 ; j = 1 , 2 , . . . , m h ) Δw^h_{ij}=ηδ^h_jy^{h-1}_i=η\left(\sum_{k=1}^{l} {δ^{h+1}_kw^{h+1}_{jk}}\right)y^h_j(1-y^h_j)y^{h-1}_j (i=0,1,2,...,m_{h-1};j=1,2,...,m_h) Δwijh=ηδjhyih−1=η(∑k=1lδkh+1wjkh+1)yjh(1−yjh)yjh−1(i=0,1,2,...,mh−1;j=1,2,...,mh)
按照以上规律逐层类推,则第一个隐藏层的权值调整公式为:
Δ w p q 1 = η δ q 1 x p = η ( ∑ r = 1 m 2 δ r 2 w q r 2 ) y q 1 ( 1 − y q 1 ) x p ( p = 0 , 1 , 2 , . . . , n ; j = 1 , 2 , . . . , m 1 ) Δw^1_{pq}=ηδ^1_qx_p=η(\sum_{r=1}^{m_2} {δ^2_rw^2_{qr}})y^1_q(1-y^1_q)x_p (p=0,1,2,...,n;j=1,2,...,m_1) Δwpq1=ηδq1xp=η(∑r=1m2δr2wqr2)yq1(1−yq1)xp(p=0,1,2,...,n;j=1,2,...,m1)
4.5.3BP算法推导的补充说明
我们已经从头到尾详细推导了一遍BP算法的整个流程,在这一小节中对BP算法再做两点补充说明:
1.网络的偏置值。
在上文中我们的推导过程一直是使用权值w来进行计算的,如果我们把偏置值独立出来,那么偏置值的参数应该怎么调整呢?
我们可以看到公式4.26以及4.27,在公式4.26中,把i的取值设置为0,并且我们知道x0 = 1,所以我们可以得到:
Δ b j 1 = η δ j 1 Δb^1_j=ηδ^1_j Δbj1=ηδj1
在公式4.26中,把j的取值设置为0,并且我们知道y0 = 1,所以我们可以得到:
Δ b k 2 = η δ k 2 Δb^2_k=ηδ^2_k Δbk2=ηδk2
如果是把偏置值单独拿出来计算的话就是公式4.39和4.40的表达式。
2.用矩阵形式来表达BP学习算法。
下面我们直接给出BP学习算法矩阵表达形式的结果,具体推导过程跟上文中的推导过程类似,不过会涉及到矩阵求导的相关知识,大家有兴趣的话可以自己推导一下。如果是把BP学习算法写成矩阵的形式来表达,假设一共有h个隐藏层。输入数据的矩阵为X,X中的每一行表示一个数据,列表示数据的特征。比如我们一次性输入3个数据,每个数据有4个特征,那么X就是一个3行4列的矩阵。
各隐藏层输出分别记为:Y1,Y2,…,Yh,输出层的输出记为:Yh+1。Y中的每一个行表示一个数据的标签。比如我们有3个数据,每个数据有1个标签,那么Y就是一个3行1列的矩阵。
各层权值矩阵分别记为:W1,W2,…,Wh+1,W1表示输入层到一个隐藏层的权值矩阵,Wh+1表示最后一个隐藏层到输出层的权值矩阵。权值矩阵的行等于前一层的神经元个数,权值矩阵的列对应于后一层的神经元个数。比如在输入层和第一个隐藏层之间的权值矩阵是W1,输入层有3个神经元,第一个隐藏层有10个神经元,那么W1就是一个3行10列的矩阵。
各层学习信号分别记为:δ1,δ2,…,δh+1。δh+1表示输出层计算出的学习信号。
对于输出层的学习信号δh+1:
δ h + 1 = ( T − Y h + 1 ) ∘ f ′ ( Y h W h + 1 ) = ( T − Y h + 1 ) ∘ Y h + 1 ∘ ( 1 − Y h + 1 ) δ^{h+1}=(T-Y^{h+1})∘f'(Y^hW^{h+1})=(T-Y^{h+1})∘Y^{h+1}∘(1-Y^{h+1}) δh+1=(T−Yh+1)∘f′(YhWh+1)=(T−Yh+1)∘Yh+1∘(1−Yh+1)
公式4.41中的“ ∘ ”符号是element-wise multiplication,意思是矩阵中的元素对应相乘。例如下面的例子:

对于第h隐藏层的学习信号δh:
δ h = δ h + 1 ( W h + 1 ) T ∘ f ′ ( Y h − 1 W h ) = δ h + 1 ( W h + 1 ) T ∘ Y h ∘ ( 1 − Y h ) δ^h=δ^{h+1}(W^{h+1})^T∘f'(Y^{h-1}W^h)=δ^{h+1}(W^{h+1})^T∘Y^h∘(1-Y^h) δh=δh+1(Wh+1)T∘f′(Yh−1Wh)=δh+1(Wh+1)T∘Yh∘(1−Yh)
对于第1隐藏层的学习信号δ1:
δ 1 = δ 2 ( W 2 ) T ∘ f ′ ( X W 1 ) = δ 2 ( W 2 ) T ∘ Y 1 ∘ ( 1 − Y 1 ) δ^1=δ^2(W^2)^T∘f'(XW^1)=δ^2(W^2)^T∘Y^1∘(1-Y^1) δ1=δ2(W2)T∘f′(XW1)=δ2(W2)T∘Y1∘(1−Y1)
对于输出层的权值矩阵Wh+1:
Δ W h + 1 = η ( Y h ) T δ h + 1 ΔW^{h+1}=η(Y^h)^Tδ^{h+1} ΔWh+1=η(Yh)Tδh+1
对于第h隐藏层权值矩阵Wh:
Δ W h = η ( Y h − 1 ) T δ h ΔW^h=η(Y^{h-1})^Tδ^h ΔWh=η(Yh−1)Tδh
对于第1隐藏层权值矩阵W1:
Δ W 1 = η ( X ) T δ 1 ΔW^1=η(X)^Tδ^1 ΔW1=η(X)Tδ1
作者介绍
