NLP技术在海外金融机构的应用

来源:DataFunTalk
本文长度为5500字,建议阅读10分钟
本文带你了解如何运用自然语言处理来辅助投资分析,涵盖了主题抽取、事件抽取、公众情绪这三类典型的应用场景。

[ 导读 ] 他山之石,可以攻玉。在这篇文章中,熵简科技的 NLP 团队带着大家看一看海外机构在自然语言处理与金融投资分析这个交叉领域的研究和应用现状。文章列举和分析了 Two Sigma、贝莱德、UC Berkeley 等知名金融和学术机构,如何运用自然语言处理来辅助投资分析,涵盖了主题抽取、事件抽取、公众情绪这三类典型的应用场景。
金融分析为什么需要用到 NLP 技术
金融分析的核心目标是找出合适的投资组合,从而获取高于市场平均水平的超额收益。
超额收益往往归功于信息不对称,而信息不对称来自两个方面:
信息总量的不对称,如果某一方投资者掌握了其他方没有的重要信息,那么他们在投资竞争中将处在优势地位;
信息过载的情况下,快速利用和挖掘信息的能力不对称。在大数据时代,这一点越来越成为各个金融资管机构竞争的焦点。
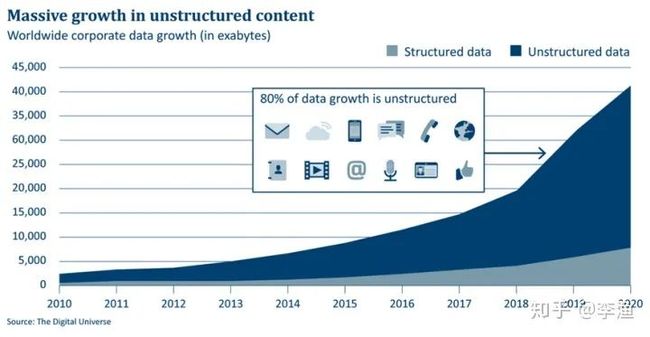
由此可知,信息不对称是金融行业的本质特征和竞争焦点。下面这张图来自 IDC 的报告,表明近几年全球新增的数据中,有 80% 都来自非结构化的数据,比如微博、twitter 等等社交媒体,人民日报、头条等新闻资讯,以及专业机构发布的研报等等。因此,金融机构需要借助自然语言处理技术从这些非结构化的文本数据中,及时、高效地挖掘出信息,这样才能在激烈的信息竞争中获取优势,赢取超额收益。
NLP 技术在金融分析中的基本特点
基于自然语言处理技术的金融分析最早在上世纪80年代就已经有机构进行探索,但公认的开创性工作是 google 在2003年申请的一项专利,这项工作证明了用新闻来预测股票价值的有效性,并解决了早期 NLP 中的一系列问题,例如指代消解、实体链接等等。时间到了2011年,随着 twitter、facebook 等等社交媒体上数据量的暴涨,研究机构发现通过分析 twitter 等社交媒体上公众情绪,可以显著提高道琼斯工业指数的预测准确度。同年,伦敦的对冲基金公司 Derwent Capital Markets 运用 twitter 舆情辅助投资分析,在第一个月实现了 1.85% 的盈利。在这之后,越来越多的机构参与到这项技术的研究中,这带来了更广泛的数据维度、更丰富的应用场景。同时,随着深度学习技术的发展,诸如 CNN、LSTM、词向量等 NLP 领域的重要成果也被逐渐运用进来,进一步加强了机器对于文本语义的建模能力。
经过十几年的发展,目前基于自然语言处理技术的金融分析方法已经逐渐发展成为了一个重要的投资分析工具。在实际的落地场景中,海外机构运用 NLP 技术解决的典型任务包括市场上关键指标的预测,例如价格波动、交易量、信用评级等等,还包括宏观经济因子提取,乃至欺诈检测、供应链管理等等。
下面这张图列出了在金融分析中,当前自然语言处理任务所面对的主要数据来源和对应的特点,包括公司公告、研报、财经新闻、社交媒体等等,各类数据的长度和更新频率也具有明显的不同。不同来源数据的频率和噪音程度不一致,因此不同数据源会影响不同的市场周期。一般而言,频率低、权威性高的文本往往会产生深远而持久的影响,而高频数据则主要反映市场短期的波动性。

在实际的应用场景中,对于上面各类文本,NLP 技术挖掘出的三类典型信息有:
关键词或主题词提取:通过词袋模型、LDA 技术或者近几年的词向量技术,将原始文本中浓缩为最能反映文本主题或语义特征的少数几个词汇;
情绪分析:市场情绪分析已经成为金融分析中一个重要的研究方向,涉及到的应用场景、技术实现方式和分析层次非常广泛,本文仅展示一个案例,之后有时间会专门写一篇文章做详细介绍;
事件提取:通过事件模板、句法分析、命名实体识别等技术手段,从原始文本中抽取出金融活动相关的事件,如 公司并购、IPO、中标等等,由此来分析不同事件对于公司股价的事后影响;
文本接下来部分,对于上述三类文本结构化方式,各自列举一个案例进行详细讨论和分析。
基于特征词/主题词分析的应用案例
基于 LDA 算法的宏观经济因子提取,by Two Sigma
在这一案例中,美国的对冲基金 Two Sigma 运用主题模型 LDA,分析美国联邦公开市场委员会(FOMC)历年会议记录的主题,根据不同主题比例的变化趋势来分析 FOMC 在不同时期对于美国经济及金融状况的主要观点和立场,从而帮助投资者更好地聚焦注意力,并预判未来形势。
先交代一下 FOMC 会议记录的重要性:FOMC 是全球经济中有重大影响力的经济参与者之一,每年定期举行八次会议,分析和审查经济、金融状况,确定货币政策立场等等,因此 FOMC 的观点非常重要。
在传统的方法中,为了及时分析这类信息,有专门的所谓美联储观察员对于会议纪要进行整理分析。但是基于人的分析往往过于主观和随机,而通过 NLP 技术则可以转为客观、稳定的信息。
在分析中,他们采用 8 个 topic 的模型分析了 FOMC 从 1995 年到 2016 年的会议记录,对部分主题合并之后的结果如下:

从上图中至少可以看到几个明显的趋势:
对比 2002 年与 2016 年,FOMC 讨论 Growth 的话题减少了一半,而讨论金融市场的话题从 10% 增加到了 22%。这似乎在说明,金融市场的稳定性是以降低增长为代价。
对比 2008 年与 2016 年,FOMC 讨论 通货膨胀 的比例逐年增加,尤其在2014年之后,这一比例快速增长到了 20% 以上。这似乎表明,美国市场受到通胀的压力正在逐年提高。
而在过去十几年间,FOMC 在就业问题上一直投入较少的关注。
基于事件提取的应用案例
新闻事件对于公司股价的短期影响分析,by UC Berkeley & 贝莱德
这一研究案例是由贝莱德和 UC Berkeley 共同完成。其主要工作是,通过从新闻标题中聚类出典型事件,来分析各类事件对于标普500 公司股价的正负影响及影响周期。在此基础上,运用组合投资方法来获取超额收益。
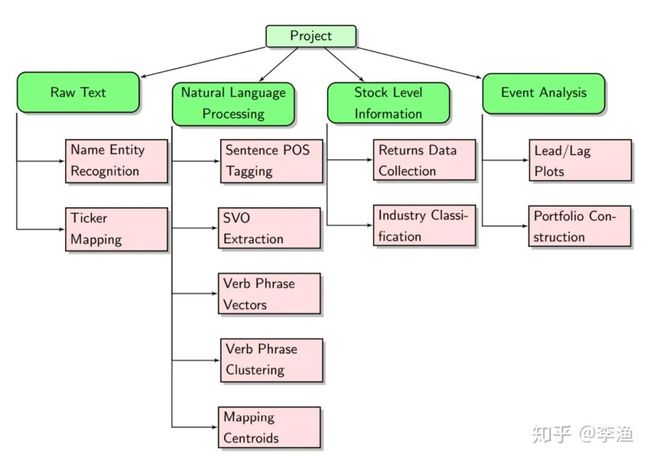
上图是整体的研究框架,我们重点关注以下四方面的问题:
1. 如何从新闻中提取出事件?
研究人员选取了新闻标题而非新闻正文作为原始文本。主要原因在于,他们认为新闻正文中包含了太多的噪音信息,尤其当新闻中引用过去的其他事件时,会对提取结果造成很大误差,而新闻标题只会聚焦于文本的主题,相当于事前加了一层噪音过滤。
接下来,通过句法分析、词性标注等技术手段对新闻标题进行分析,只有具备 主谓宾 结构的标题才会被保留,因为这一类标题往往包含着公司主体采取了行动。
对于标题中的主语,通过命名实体识别的方法从中抽取出公司主体,并与标普500中的公司映射起来;
对于标题中“谓语 + 宾语”,则构成一个“动宾短语”,一般是用来表达公司行为,这也正是我们希望提取出来的事件。
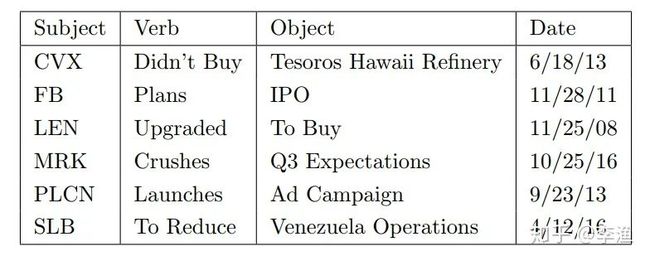
上面这张表列出了一些典型的处理结果。其中,第一列为提取的公司,包含诸如雪佛龙、facebook 等公司。
第二列和第三列共同构成了事件短语,包含了诸如“放弃收购某工厂”、“计划IPO”等典型事件。
最后,利用词向量对抽取出的动宾短语进行编码之后,通过 k-means 对于同一类的相似事件聚合在一起,从而更方便地分析各类事件对于公司股价的影响。
2. 如何考量新闻事件对于股价的影响?
完成了事件提取之后,接下来就需要定量地分析各类事件对于公司股价的影响。在这个案例中,研究人员直接分析了各类事件是否可以带来正面的超额收益,还是低于市场平均水平的负面收益。
在实际中,首先利用调整后的资本资产定价模型(CAPM)来评估,假设事件没有发生时,股票的预期收益。接下来,考虑事件实际发生后,若持有该股票,在接下来的一段时间内的累计收益是多少。这两项收益相减,即是这项事件带来的额外收益。
当然,在实际中,为了尽可能准确地抽离出事件的影响,实际的计算会更复杂一些,例如会考虑多个时间窗口下的滑动平均等等。感兴趣的同学可以参考原文。
3. 如何运用分析结果来指导投资?
有了前面的分析之后,就可以将各类事件的影响转换到投资组合中,来指导实际的资产投资。
这里面涉及到最优化方法的一些数学知识,此处不做详细展开。其核心思想是,将事件对于资产收益的影响转为投资组合问题的一个约束条件,据此来获取到更优的资产投资组合。
在实际中,研究人员用 2006 年-2014年的数据作为训练样本,来提取出各类典型事件,并提取各类事件对于股价收益的影响。在此基础上,用投资组合方法在 2015 年-2016 年的数据上进行了回测,实验证明了这一方法可以带来超额收益,同时降低负面事件带来的损失。
4. 有哪些重要的研究发现?
在原始的研究结果中,研究人员尝试了事件的聚类数目分别是 10,20,50,100 时,提取到的事件对于股价的收益影响。因为篇幅原因,这里列举两类典型事件:
第一类事件:Oversold Conditions
在这一类事件中,排在最前面的几类动宾短语如下:
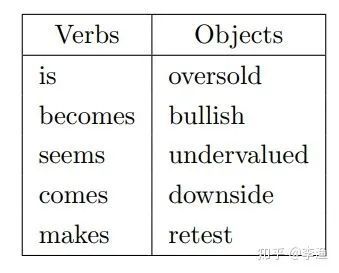
直观来看,这一类事件往往与公司股票超卖和低估有关系。下面这张图列出了事件发生前后的日均收益和累计收益的变化:
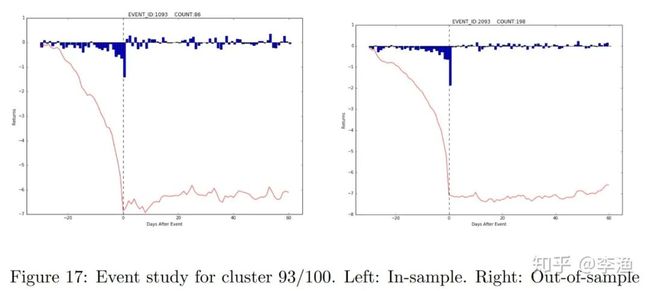
左右两张图分别代表着样本内和样本外的分析结果,二者基本一致。其中,蓝色柱状图代表着日均收益,红色实线代表着累计收益,而虚线则代表着事件的发生日期。两张图都表明,在事件发生之前,该公司的股价处在下降状态,因而累计的负向收益越来越大。
而此类事件发生之后,股价的下降趋势被迅速扭转,且有一定的回升。这说明,研究人员用到的这一套事件提取和聚类的方法,有效地将正向事件识别了出来。
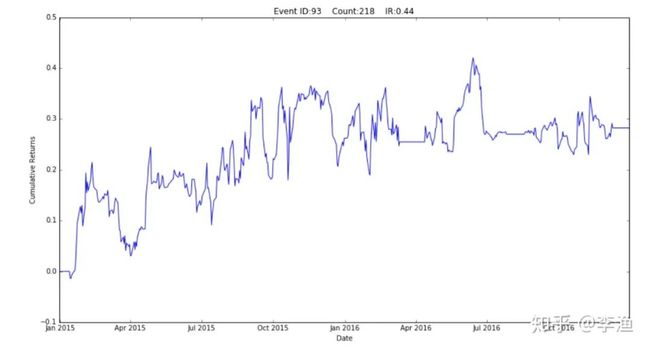
接下来,研究人员将将上述的分析结果运用到组合投资中。上面这张图是在 2015-2016年的样本外数据上的回测结果,表明整套方法确实可以带来超额收益。
第二类事件:Approval Story
对应排在最前面的几类动宾短语如下:

这一类事件预示着公司获取了某项批准,这表明公司在发展道路上获取到了积极的支持。下面两张图同样展示了样本内外的分析结果:
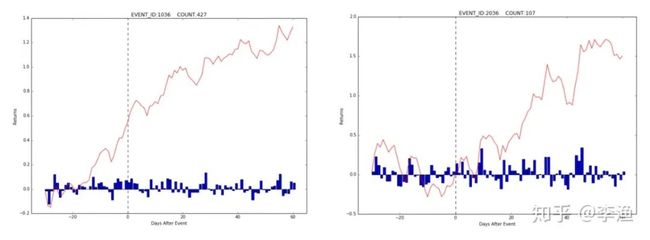
样本内外的分析结果都表明,在与“批准”有关的事件发生之后,公司的股价会有一定的上涨。同样地,在样本外的数据上进行投资回测,也可以获取到超额收益,如下图所示:

简单总结一下这部分的内容。这一案例充分证明了通过 NLP 技术来挖掘新闻事件,可以快速捕捉到某一些与公司股价变化具有强相关的新闻事件,从而帮助投资者优化投资组合,获取到更好的收益。
此外,本文的不足也是显而易见的。首先,受限于所采用的 NLP 技术手段,这一案例只考虑了新闻标题中的主谓宾关系提取。而近几年快速发展的 NLP 技术已经使得机器具备更强的阅读理解能力和特征提取能力,因此有希望构建出更复杂、分析能力更为强大的系统,以获取到更大的竞争优势。
基于市场情绪分析的应用案例
前面已经提到,基于市场情绪的金融分析是一大类方法。本文以2011年一篇早期的代表性研究工作为切入点,介绍这类方法的基本方法和思想,这一研究工作累积至今的 google 引用量已经超过了4500,因此很有必要回顾一下。其他更新、更全面的有关市场情绪的应用案例放在以后再做详细介绍。
这项研究的核心目标是,研究 twitter 上所反映出的公众情绪是否与道琼斯工业指数(DJIA)有显著的相关性。
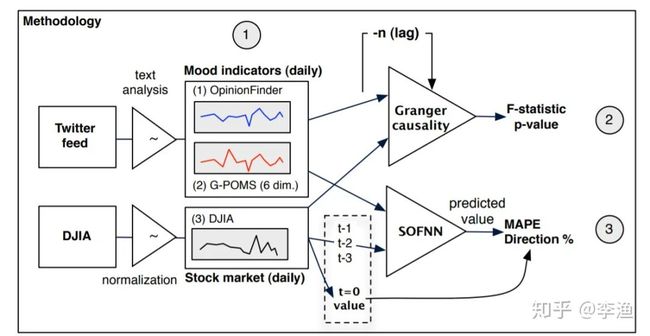
上面这张图展示了整体的研究框架。研究人员采用了 twitter 上从 2008年10月到12月的数据,分别运用 OpinionFinder 和 GPOMS 两类情绪分析工具,从twitter 中抽取出情绪值。其中,OpinionFinder 可抽取文本整体所表现情感的正负极性;而 GPOMS 可从文本中抽取出六个不同维度的情绪表现,分别是:Calm, Alert, Sure, Vital, Kind 和 Happy。总而言之,对于一条 twitter,会抽取出七个维度的情感表现。
完成了对于twitter的情感分析之后,研究人员分别运用 Granger 因果分析法和 自组织模糊神经网络(SOFNN)对于 twitter 的七类情绪值与 DJIA 的关系进行建模分析。两种模型都证明了,运用 twitter 上的公众情绪可以显著提高道琼斯工业指数的预测准确性。
其中的重要发现列举如下:
1. 在 Granger 因果分析中,twitter 中的 Calm 这个维度的情绪值与道琼斯工业指数具有显著的 Granger 因果性,其结果如下图所示:
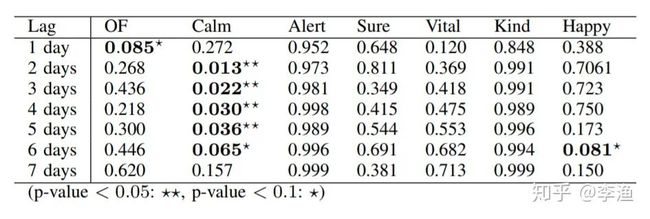
其中,OF 这一列代表着推文的整体情感极性。在统计学上,p 值越小,说明该情绪值与 道琼斯工业指数 的 Granger 因果性越高,也就越具有可预测性。
2. 由于 SOFNN 网络可对几个情绪值之间的非线性关系进行建模,因此可以挖掘 twitter 情绪与道琼斯工业指数之间更复杂的关系。他们发现,运用 SOFNN 网络在可以道琼斯工业指数变化的方向上实现 87.6% 的预测准确率。
同时,我们尤其应该注意的是,研究中还发现,推文的整体情感极性对于道琼斯工业指数并没有显著的预测效果,而仅有 Calm 这个维度的情绪值对于道琼指数表现出了较高的预测性。因此,投资者如果希望通过社交媒体上的公众情绪来辅助投资分析,不应该简单的关注推文正负情感极性,而应该考虑从推文中挖据出更复杂、更多维度的情感、情绪表达。
总结
本文回顾了海外机构在自然语言处理与金融投资分析这个交叉领域的研究和应用现状。列举和分析了 Two Sigma、贝莱德、UC Berkeley 等知名金融和学术机构,如何运用自然语言处理来辅助投资分析,涵盖了主题抽取、事件抽取、公众情绪这三类典型的应用场景。
最后再简单讨论一点。从前面的案例中可以看出,各案例中所用到的技术与历史同期的 NLP 技术相比,一般落后了至少五年以上。排除技术路径的依赖性以后,有很大一部分的原因是同时深入理解 NLP 技术和金融业务的专业人士太少。因此,只有金融领域的业务专家和 NLP 领域的技术专家深度合作,才能有效发挥现代 NLP 技术的能力,开发出更智能化的系统。
今天的分享就到这里,谢谢大家。
原文链接:
https://zhuanlan.zhihu.com/p/133469871
参考文献:
1. Chew, Ming, et al. "Using Natural Language Processing Techniques for Stock Return Predictions." Available at SSRN 2940564 (2017).
2. Zhang, Xue, Hauke Fuehres, and Peter A. Gloor. "Predicting stock market indicators through twitter “I hope it is not as bad as I fear”."Procedia-Social and Behavioral Sciences26 (2011): 55-62.
3. Bollen, Johan, Huina Mao, and Xiaojun Zeng. "Twitter mood predicts the stock market."Journal of computational science2.1 (2011): 1-8.
4. Oliveira, Nuno, Paulo Cortez, and Nelson Areal. "The impact of microblogging data for stock market prediction: Using Twitter to predict returns, volatility, trading volume and survey sentiment indices."Expert Systems with Applications73 (2017): 125-144.
5. Kumar, B. Shravan, and Vadlamani Ravi. "A survey of the applications of text mining in financial domain."Knowledge-Based Systems114 (2016): 128-147.
6. Xing, Frank Z., Erik Cambria, and Roy E. Welsch. "Natural language based financial forecasting: a survey."Artificial Intelligence Review50.1 (2018): 49-73.
7. Breaban, Adriana, and Charles N. Noussair. "Emotional state and market behavior."Review of Finance22.1 (2018): 279-309.
8. Berger, Jonah, et al. "Uniting the tribes: Using text for marketing insight." Journal of Marketing 84.1 (2020): 1-25.
9. Saret, Jeffrey N., and Subhadeep Mitra. "An ai approach to fed watching." Two Sigma Insights (2016).
10. Atkins, Adam, Mahesan Niranjan, and Enrico Gerding. "Financial news predicts stock market volatility better than close price." The Journal of Finance and Data Science 4.2 (2018): 120-137.
11. https://www.ibtimes.com/twitter-based-hedge-fund-making-money-833863
文章作者

李渔博士
熵简科技 | 联合创始人
博士毕业于清华大学电子工程系,以第一作者身份发表学术论文10余篇,申请专利6项,致力于将先进的自然语言处理及深度学习技术真正落地于金融资管领域,让科技赋能产业。目前负责熵简科技NLP技术中台的建设,包括层次化的分层架构、大数据泛采体系、持续部署的后台支持以及前沿算法的领域内落地等,为熵简科技的各大业务线提供底层技术支持和可落地的解决方案。
作者知乎专栏《自然语言处理二三事》地址:
https://zhuanlan.zhihu.com/c_1215573707772649472
编辑:于腾凯
校对:林亦霖
