一文带你入门图论和网络分析(附Python代码)

作者:Srivatsa
翻译:和中华
校对:丁楠雅
本文约6300字,建议阅读20+分钟。
本文从图的概念以及历史讲起,并介绍了一些必备的术语,随后引入了networkx库,并以一个航班信息数据集为例,带领读者完成了一些基本分析。
简介
俗话说一图胜千言。但是“图”(Graph)说的远不止于此。以图形式呈现的数据可视化能帮助我们获得见解,并基于它们做出更好的数据驱动型决策。
但要真正理解图是什么以及为什么使用它们,我们需要理解一个称为图论(Graph Theory)的概念。理解它可以使我们成为更好的程序员。

如果你曾经尝试理解这个概念,应该会遇到大量的公式和干涩的理论。这便是为什么我们要写这篇博文的原因。我们先解释概念,然后提供实例,以便你可以跟随并弄明白它的执行方式。这是一篇详细的文章,因为我们认为提供概念的正确解释要比简洁的定义更受欢迎。
在本文中,我们将了解图是什么,它们的应用以及一些历史背景。我们还将介绍一些图论概念,然后使用进行案例研究以巩固理解。
准备好了吗?我们开始吧。
目录
图及其应用
图论的历史、为何使用图论
必备术语
图论概念
熟悉Python中的图
数据分析案例
图及其应用
让我们看一个简单的图(Graph)来理解这个概念。如下图所示:
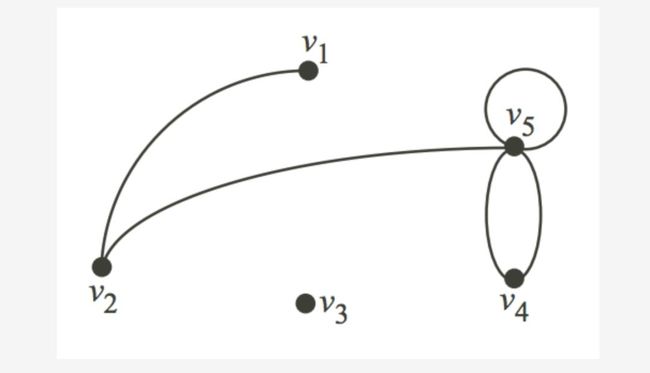
假设此图代表某个城市的热门景点位置,以及游客所遵循的路径。我们把V视为景点位置,将E视为从一个地方到另一个地方的路径。
V = {v1, v2, v3, v4, v5}
E = {(v1,v2), (v2,v5), (v5, v5), (v4,v5), (v4,v4)}
边(u,v)与边(v,u)相同 - 它们是无序对。
具体而言,图(Graph)是用于研究对象和实体之间成对关系的数学结构。它是离散数学的一个分支,在计算机科学,化学,语言学,运筹学,社会学等领域有多种应用。
数据科学和分析领域也使用图来模拟各种结构和问题。作为一名数据科学家,你应该能以有效的方式解决问题,如果数据是以特定方式排列的,则图可以提供一种解决问题的机制。
形式上看,
图是一对集合。G = (V, E),V是顶点集合,E是边集合。 E由V中的元素对组成(无序对)
有向图(DiGraph)也是一对集合。D = (V, A),V是顶点集合,A是弧集合。A由V中的元素对组成(有序对)
在有向图的情况下,(u,v)和(v,u)之间存在区别。通常在这种情况下,边被称为弧,以指示方向的概念。
R和Python中都有使用图论概念分析数据的包。在本文中,我们将简要介绍一些概念并使用Networkx Python包分析一个数据集。
from IPython.display import Image
Image('images/network.PNG')
Image('images/usecase.PNG')
从上面的例子可以清楚地看出,图在数据分析中的应用是广泛的。我们来看几个用例场景:
营销分析
图可用于找出社交网络中最有影响力的人。广告商和营销人员可以通过社交网络中最有影响力的人员传达他们的信息,从而估算最大的营销价格。
银行交易
图可用于查找有助于减少欺诈交易的异常模式。有一些例子可以通过分析银行网络的资金流动来侦测恐怖主义活动。
供应链
图有助于确定送货卡车的最佳路线以及识别仓库和交付中心的位置。
制药公司
制药公司可以使用图论优化销售人员的路线。这有助于降低成本并缩短销售人员的行程时间。
电信行业
电信公司通常使用图(Voronoi图)来了解基站的数量和位置,以确保最大的覆盖范围。
图的历史以及为何使用图
图的历史
如果想更多地了解关于图的想法是如何形成的,请继续阅读!
该理论的起源可以追溯到柯尼斯堡七桥问题(大约1730年代)。它提问是否可以在以下限制条件下遍历柯尼斯堡市的七座桥梁
每座桥只经过一次(即不重复)
从哪出发,最终回到哪
小故事:欧拉于1736年研究并解决了此问题,他把问题归结为如“一笔画”问题。他的《柯尼斯堡七桥》的论文圆满解决了这一问题,同时开创了数学一个新分支---图论。
这等价于询问4个节点和7个边的多图(multigraph)是否具有欧拉环(欧拉环是在同一个顶点上开始和结束的欧拉路径。而欧拉路径是指在图中仅仅遍历每个边一次的路径。更多术语后文中给出)。这个问题引出了欧拉图的概念。柯尼斯堡七桥问题的答案是否定的,它最早由欧拉解答。
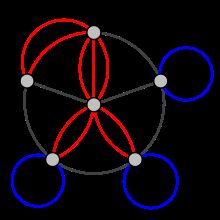
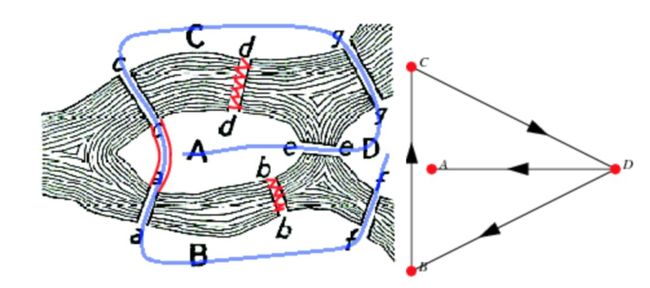
译者注:在图论中,多图(相对于简单图)是指图中允许出现多边(也叫平行边),即两个顶点可以有多条边连接,如下图中的红色就是多边,所以该图属于多图。
1840年,A.F Mobius提出了完全图(complete graph)和二分图(bipartite graph)的概念,Kuratowski通过趣味谜题证明它们是平面的。树的概念(没有环的连通图)由Gustav Kirchhoff于1845年提出,他在计算电网或电路中的电流时使用了图论思想。
1852年,Thomas Gutherie发现了著名的四色问题。然后在1856年,Thomas P. Kirkman和William R.Hamilton研究了多面体的循环,并通过研究仅访问某些地点一次的旅行,发明了称为哈密顿图的概念。1913年,H.Dudeney提到了一个难题。尽管发明了四色问题,但Kenneth Appel和Wolfgang Haken在一个世纪后才解决了这个问题。这一次被认为是图论真正的诞生。
Caley研究了微分学的特定分析形式来研究树。这在理论化学中有许多含义。这也导致了枚举图论(enumerative graph theory)的发明。不管怎么说,“图”这个术语是由Sylvester在1878年引入的,他在“量子不变量”与代数和分子图的协变量之间进行了类比。
1941年,Ramsey致力于着色问题,这产生了另一个图论的分支 - 极值图论(Extremal graph theory)。1969年,Heinrich使用计算机解决了四色问题。对渐近图连通性的研究产生了随机图论。图论和拓扑学的历史也密切相关,它们有许多共同的概念和定理。
Image('images/Konigsberg.PNG', width = 800)
为何使用图?
以下几点可以激励你在日常数据科学问题中使用图:
图提供了一种处理关系和交互等抽象概念的更好的方法。它还提供了直观的视觉方式来思考这些概念。图很自然地成了分析社会关系的基础。
图数据库已成为一种常用的计算工具,并且是SQL和NoSQL数据库的替代方案。
图用于以DAG(定向非循环图)的形式建模分析工作流。
一些神经网络框架还使用DAG来模拟不同层中的各种操作。
图理论用于研究和模拟社交网络,欺诈模式,功耗模式,社交媒体的病毒性和影响力。社交网络分析(SNA)可能是图理论在数据科学中最著名的应用。
它用于聚类算法 - 特别是K-Means。
系统动力学也使用一些图理论 - 特别是循环。
路径优化是优化问题的一个子集,它也使用图的概念。
从计算机科学的角度来看,图提供了计算效率。某些算法的Big O复杂度对于以图形式排列的数据更好(与表格数据相比)。
必备术语
在进一步阅读本文之前,建议你熟悉这些术语。
顶点u和v称为边(u,v)的末端顶点。
如果两条边具有相同的末端顶点,则它们是平行的。
形式为(v,v)的边是循环。
如果图没有平行边和循环,则图被称为简单图。
如果图没有边,则称其为Empty,即E是空的。
如果图没有顶点,则称其为Null,即V和E是空的。
只有1个顶点的图是一个Trivial graph。
具有共同顶点的边是相邻的。具有共同边的顶点是相邻的。
顶点v的度,写作d(v),是指以v作为末端顶点的边数。按照惯例,我们把一个循环计作两次,并且平行边缘分别贡献一个度。
孤立顶点是度数为1的顶点。d(1)顶点是孤立的。
如果图的边集合包含了所有顶点之间的所有可能边,则图是完备的。
图G =(V,E)中的步行(Walk)是指由图中顶点和边组成的一个形如ViEiViEi的有限交替序列。
如果初始顶点和最终顶点不同,则Walk是开放的(Open)。如果初始顶点和最终顶点相同,则Walk是关闭的(Closed)。
如果任何边缘最多遍历一次,则步行是一条Trail。
如果任何顶点最多遍历一次,则Trail是一条路径Path(除了一个封闭的步行)。
封闭路径(Closed Path)是一条回路Circuit,类似于电路。
图论概念
在本节中,我们将介绍一些对数据分析有用的概念(无特定顺序)。请注意,另外还有很多概念的深度超出了本文的范围。我们开始吧。
平均路径长度
所有可能节点对应的最短路径长度的平均值。给出了图的“紧密度”度量,可用于了解此网络中某些内容的流动速度。
BFS和DFS
广度优先搜索和深度优先搜索是用于在图中搜索节点的两种不同算法。它们通常用于确定我们是否可以从给定节点到达某个节点。这也称为图遍历。
BFS的目的是尽可能接近根节点遍历图,而DFS算法旨在尽可能远离根节点。
中心性(Centrality)
用于分析网络的最广泛使用和最重要的概念工具之一。中心性旨在寻找网络中最重要的节点。可能存在对“重要”的不同理解,因此存在许多中心性度量标准。中心性标准本身就可以分成好多类。有一些标准是以沿着边的流动为特征,还有一些标准以步行结构(Walk Structure)为特征。
一些最常用的标准是:
度中心性(Degree Centrality) - 第一个也是概念上最简单的中心性定义。表示连接到某节点的边数。在有向图中,我们可以有2个度中心性度量。流入和流出的中心性。
紧密中心性(Closeness Centrality) - 从某节点到所有其他节点的最短路径的平均长度。
中介中心性(Betweenness Centrality) - 某节点在多少对节点的最短路径上。
这些中心性度量有不同变种,并且可以使用各种算法来实现定义。总而言之,这方面有大量的定义和算法。
网络密度
图的边数的度量。实际定义将根据图的类型和所提问问题的上下文而不同。对于完备的无向图,密度为1,而空图(empty)为0。在某些情况下(包含循环时),图密度可能大于1。
图随机化(Graph Randomization)
尽管一些图度量指标可能很容易计算,但要理解它们的相对重要性并不容易。在这种情况下,我们使用网络/图随机化。我们计算了手头的图和随机生成的另一些类似图的度量。例如,这些相似图可以有相同数量的密度和节点。通常我们生成1000个相似的随机图并计算每个图的度量标准,然后与手头图的相同度量进行比较,以得出某些基准(benchmark)。
在数据科学中,当尝试对某个图进行声明时,如果与某些随机生成的图进行对比,则会有所帮助。
熟悉Python中的图
我们将在Python中使用networkx包。它可以安装在Anaconda的Root环境中(如果你使用的是Anaconda的Python分发版)。你也可以pip install安装它。
让我们看一下使用Networkx软件包可以完成的一些常见事情。包括导入和创建图以及可视化图的方法。
图形创建
import networkx as nx
# Creating a Graph
G = nx.Graph() # Right now G is empty
# Add a node
G.add_node(1)
G.add_nodes_from([2,3]) # You can also add a list of nodes by passing a list argument
# Add edges
G.add_edge(1,2)
e = (2,3)
G.add_edge(*e) # * unpacks the tuple
G.add_edges_from([(1,2), (1,3)]) # Just like nodes we can add edges from a list
通过传递包含节点和属性dict的元组,可以在创建节点和边的时候添加节点和边的属性。
除了逐个节点或逐个边地构建图形之外,还可以通过一些经典的图操作来生成它们,例如:
subgraph(G, nbunch) - induced subgraph view of G on nodes in nbunch
union(G1,G2) - graph union
disjoint_union(G1,G2) - graph union assuming all nodes are different
cartesian_product(G1,G2) - return Cartesian product graph
compose(G1,G2) - combine graphs identifying nodes common to both
complement(G) - graph complement
create_empty_copy(G) - return an empty copy of the same graph class
convert_to_undirected(G) - return an undirected representation of G
convert_to_directed(G) - return a directed representation of G
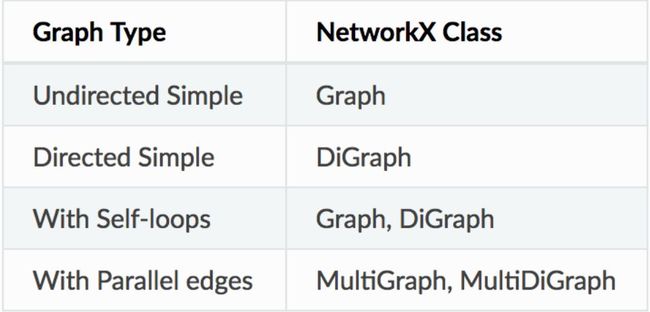
对于不同类型的图,存在单独的类。例如,nx.DiGraph类允许创建有向图。可以使用单个方法直接创建包含路径的特定图。有关图创建方法的完整列表,请参阅完整文档。链接在本文末尾给出。
Image('images/graphclasses.PNG', width = 400)
访问边和节点
可以使用G.nodes和G.edges方法访问节点和边。可以使用括号/下标法访问各个节点和边。
G.nodes()
NodeView((1, 2, 3))
G.edges()
EdgeView([(1, 2), (1, 3), (2, 3)])
G[1] # same as G.adj[1]
AtlasView({2: {}, 3: {}})
G[1][2]
{}
G.edges[1, 2]
{}
图可视化
Networkx提供了可视化图的基本功能,但其主要目标是帮助图分析而不是图的可视化。图可视化很难,我们将使用专门用于此任务的工具。Matplotlib提供了一些便利功能。但是GraphViz可能是最好的工具,因为它提供了一个PyGraphViz的Python接口(链接在文档的末尾)。
%matplotlib inline
import matplotlib.pyplot as plt
nx.draw(G)
首先必须安装Graphviz。然后使用该命令pip install pygraphviz --install-option =“<>。在安装选项中,你必须提供Graphviz 中lib和include文件夹的路径。
import pygraphviz as pgv
d={'1': {'2': None}, '2': {'1': None, '3': None}, '3': {'1': None}}
A = pgv.AGraph(data=d)
print(A) # This is the 'string' or simple representation of the Graph
Output:
strict graph "" {
1 -- 2;
2 -- 3;
3 -- 1;
}
PyGraphviz可以很好地控制边和节点的各个属性。我们可以使用它获得非常漂亮的可视化。
# Let us create another Graph where we can individually control the colour of each node
B = pgv.AGraph()
# Setting node attributes that are common for all nodes
B.node_attr['style']='filled'
B.node_attr['shape']='circle'
B.node_attr['fixedsize']='true'
B.node_attr['fontcolor']='#FFFFFF'
# Creating and setting node attributes that vary for each node (using a for loop)
for i in range(16):
B.add_edge(0,i)
n=B.get_node(i)
n.attr['fillcolor']="#%2x0000"%(i*16)
n.attr['height']="%s"%(i/16.0+0.5)
n.attr['width']="%s"%(i/16.0+0.5)
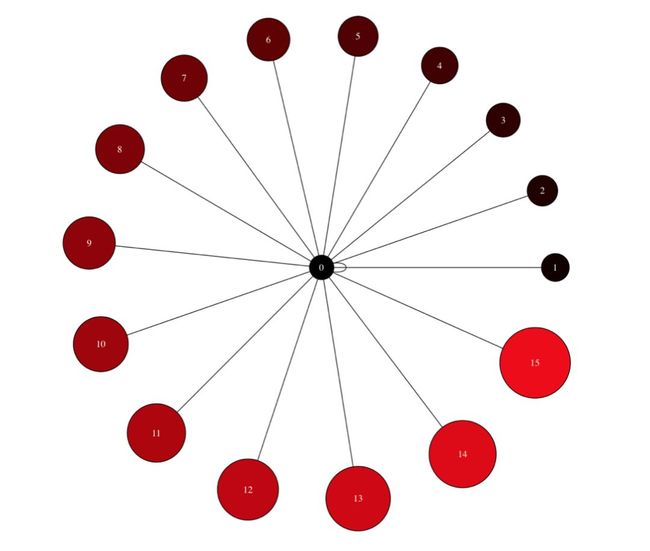
B.draw('star.png',prog="circo") # This creates a .png file in the local directory. Displayed below.
Image('images/star.png', width=650) # The Graph visualization we created above.
通常,可视化被认为是与图分析独立的任务。分析后的图将导出为Dotfile。然后单独显示该Dotfile以展示我们想表达的内容。
数据分析案例
我们将寻找一个通用数据集(不是专门用于图的数据集)并进行一些操作(在pandas中),以便它可以以边列表(edge list)的形式输入到图中。边列表是一个元组列表,其中的元组包含定义每条边的顶点
我们将关注的数据集来自航空业。它有一些关于航线的基本信息。有某段旅程的起始点和目的地。还有一些列表示每段旅程的到达和起飞时间。如你所想,这个数据集非常适合作为图进行分析。想象一下通过航线(边)连接的几个城市(节点)。如果你是航空公司,你可以问如下几个问题:
从A到B的最短途径是什么?分别从距离和时间角度考虑。
有没有办法从C到D?
哪些机场的交通最繁忙?
哪个机场位于大多数其他机场“之间”?这样它就可以变成当地的一个中转站。
import pandas as pd
import numpy as np
data = pd.read_csv('data/Airlines.csv')
data.shape
(100, 16)
data.dtypes
year int64
month int64
day int64
dep_time float64
sched_dep_time int64
dep_delay float64
arr_time float64
sched_arr_time int64
arr_delay float64
carrier object
flight int64
tailnum object
origin object
dest object
air_time float64
distance int64
dtype: object
我们注意到起始点和目的地看起来像节点的好人选。然后可以将所有东西想象为节点或边的属性。单条边可以被认为是一段旅程。这样的旅程将有不同的时间,航班号,飞机尾号等相关信息。
我们注意到年,月,日和时间信息分散在许多列上。所以我们想创建一个包含所有这些信息的日期时间列。我们还需要将预计的(scheduled)和实际的(actual)到达离开时间分开。所以我们最终应该有4个日期时间列(预计到达时间、预计起飞时间、实际到达时间和实际起飞时间)。
此外,时间列的格式不正确。下午4:30被表示为1630而不是16:30。该列没有分隔符。一种方法是使用pandas字符串方法和正则表达式。
我们还应该注意到sched_dep_time和sched_arr_time是int64 类型而dep_time和arr_time是float64 类型。
另一个麻烦是NaN值。
# converting sched_dep_time to 'std' - Scheduled time of departure
data['std'] = data.sched_dep_time.astype(str).str.replace('(\d{2}$)', '') + ':' + data.sched_dep_time.astype(str).str.extract('(\d{2}$)', expand=False) + ':00'
# converting sched_arr_time to 'sta' - Scheduled time of arrival
data['sta'] = data.sched_arr_time.astype(str).str.replace('(\d{2}$)', '') + ':' + data.sched_arr_time.astype(str).str.extract('(\d{2}$)', expand=False) + ':00'
# converting dep_time to 'atd' - Actual time of departure
data['atd'] = data.dep_time.fillna(0).astype(np.int64).astype(str).str.replace('(\d{2}$)', '') + ':' + data.dep_time.fillna(0).astype(np.int64).astype(str).str.extract('(\d{2}$)', expand=False) + ':00'
# converting arr_time to 'ata' - Actual time of arrival
data['ata'] = data.arr_time.fillna(0).astype(np.int64).astype(str).str.replace('(\d{2}$)', '') + ':' + data.arr_time.fillna(0).astype(np.int64).astype(str).str.extract('(\d{2}$)', expand=False) + ':00'
现在时间列被转换成了我们想要的格式。最后,我们可能希望将年,月和日列合并到日期列中。这一步不是绝对必要的。但是,一旦转换为日期时间(datetime)格式,我们就可以轻松获取年,月,日(和其他)信息。
data['date'] = pd.to_datetime(data[['year', 'month', 'day']])
# finally we drop the columns we don't need
data = data.drop(columns = ['year', 'month', 'day'])
现在使用networkx函数导入数据集,该函数直接读如pandas DataFrame。就像图创建一样,多种方法可以将数据从多种格式中输入到图中。
import networkx as nx
FG = nx.from_pandas_edgelist(data, source='origin', target='dest', edge_attr=True,)
FG.nodes()
输出:
NodeView(('EWR', 'MEM', 'LGA', 'FLL', 'SEA', 'JFK', 'DEN', 'ORD', 'MIA', 'PBI', 'MCO', 'CMH', 'MSP', 'IAD', 'CLT', 'TPA', 'DCA', 'SJU', 'ATL', 'BHM', 'SRQ', 'MSY', 'DTW', 'LAX', 'JAX', 'RDU', 'MDW', 'DFW', 'IAH', 'SFO', 'STL', 'CVG', 'IND', 'RSW', 'BOS', 'CLE'))
FG.edges()
输出:
EdgeView([('EWR', 'MEM'), ('EWR', 'SEA'), ('EWR', 'MIA'), ('EWR', 'ORD'), ('EWR', 'MSP'), ('EWR', 'TPA'), ('EWR', 'MSY'), ('EWR', 'DFW'), ('EWR', 'IAH'), ('EWR', 'SFO'), ('EWR', 'CVG'), ('EWR', 'IND'), ('EWR', 'RDU'), ('EWR', 'IAD'), ('EWR', 'RSW'), ('EWR', 'BOS'), ('EWR', 'PBI'), ('EWR', 'LAX'), ('EWR', 'MCO'), ('EWR', 'SJU'), ('LGA', 'FLL'), ('LGA', 'ORD'), ('LGA', 'PBI'), ('LGA', 'CMH'), ('LGA', 'IAD'), ('LGA', 'CLT'), ('LGA', 'MIA'), ('LGA', 'DCA'), ('LGA', 'BHM'), ('LGA', 'RDU'), ('LGA', 'ATL'), ('LGA', 'TPA'), ('LGA', 'MDW'), ('LGA', 'DEN'), ('LGA', 'MSP'), ('LGA', 'DTW'), ('LGA', 'STL'), ('LGA', 'MCO'), ('LGA', 'CVG'), ('LGA', 'IAH'), ('FLL', 'JFK'), ('SEA', 'JFK'), ('JFK', 'DEN'), ('JFK', 'MCO'), ('JFK', 'TPA'), ('JFK', 'SJU'), ('JFK', 'ATL'), ('JFK', 'SRQ'), ('JFK', 'DCA'), ('JFK', 'DTW'), ('JFK', 'LAX'), ('JFK', 'JAX'), ('JFK', 'CLT'), ('JFK', 'PBI'), ('JFK', 'CLE'), ('JFK', 'IAD'), ('JFK', 'BOS')])
nx.draw_networkx(FG, with_labels=True) # Quick view of the Graph. As expected we see 3 very busy airports
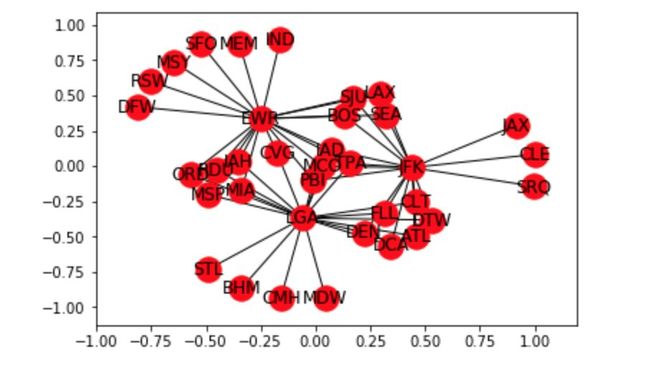
nx.algorithms.degree_centrality(FG) # Notice the 3 airports from which all of our 100 rows of data originates
nx.density(FG) # Average edge density of the Graphs
输出:
0.09047619047619047
nx.average_shortest_path_length(FG) # Average shortest path length for ALL paths in the Graph
输出:
2.36984126984127
nx.average_degree_connectivity(FG) # For a node of degree k - What is the average of its neighbours' degree?
输出:
{1: 19.307692307692307, 2: 19.0625, 3: 19.0, 17: 2.0588235294117645, 20: 1.95}
从可视化中(上面的方式)可以明显看出 - 从一些机场到其他机场有多条路径。 假如想要计算2个机场之间的最短路线。我们可以想到几种方法:
距离最短的路径。
飞行时间最短的路径。
我们可以通过距离或飞行时间来给路径赋予权重,并用算法计算最短路径。请注意,这是一个近似的解决方案 - 实际问题是计算当你到达中转机场时的航班可用性加候机的等待时间,这才是一种更完整的方法,也是人们计划旅行的方式。出于本文的目的,我们将假设你到达机场时可以随时使用航班并使用飞行时间作为权重,从而计算最短路径。
让我们以JAX和DFW机场为例:
# Let us find all the paths available
for path in nx.all_simple_paths(FG, source='JAX', target='DFW'):
print(path)
# Let us find the dijkstra path from JAX to DFW.
# You can read more in-depth on how dijkstra works from this resource - https://courses.csail.mit.edu/6.006/fall11/lectures/lecture16.pdf
dijpath = nx.dijkstra_path(FG, source='JAX', target='DFW')
dijpath
输出:
['JAX', 'JFK', 'SEA', 'EWR', 'DFW']
# Let us try to find the dijkstra path weighted by airtime (approximate case)
shortpath = nx.dijkstra_path(FG, source='JAX', target='DFW', weight='air_time')
shortpath
输出:
['JAX', 'JFK', 'BOS', 'EWR', 'DFW']
结语
本文充其量只是对图论和网络分析这一非常有趣的领域进行了粗浅的介绍。对理论和Python软件包的了解将为任何数据科学家的工具库增加一个有价值的工具。 对于上面使用的数据集,可以提出一系列其他问题,例如:
在给定成本,飞行时间和可用性的情况下,找到两个机场之间的最短路径?
作为一家航空公司,你们拥有一队飞机。你了解航班的需求。假设你有权再运营2架飞机(或者为你的机队添加2架飞机),把这两架飞机投入到哪条航线可以最大限度地提高盈利能力?
你可以重新安排航班和时刻表以优化某个参数吗?(如时效性或盈利能力等)
如果你解决了这些问题,请在下面的评论中告诉我们!
网络分析将有助于解决一些常见的数据科学问题,并在更大规模和抽象的情况下对其进行可视化。如果想了解更多有关其他内容的信息,请发表评论。
参考文献
1. History of Graph Theory || S.G. Shrinivas et. al
2. Big O Notation cheatsheet
3. Networkx reference documentation
4. Graphviz download
5. Pygraphvix
6. Star visualization
7. Dijkstra Algorithm
原文标题:
An Introduction to Graph Theory and Network Analysis (with Python codes)
链接:
https://www.analyticsvidhya.com/blog/2018/04/introduction-to-graph-theory-network-analysis-python-codes/
译者简介

和中华,留德软件工程硕士。由于对机器学习感兴趣,硕士论文选择了利用遗传算法思想改进传统kmeans。目前在杭州进行大数据相关实践。加入数据派THU希望为IT同行们尽自己一份绵薄之力,也希望结交许多志趣相投的小伙伴。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织