Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields【菜鸟读者】
Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields
- Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields
- 1.文章概要
- 2.文章亮点
- 3.姿势识别流程
- 4.网络详解
- 4.1 网络收敛性判断
- 4.2 计算S∗j(p)Sj∗(p)S^*_j(p)
- 4.3 计算L∗c(p)Lc∗(p)L^*_c(p)
- 4.4 如何评估评估两点相连的可能性
- 5. 关节拼接
- 5.1 拼接方法尝试
- 5.2 拼接过程
1.文章概要
文章实现了图片中的多人姿态检测,与已有的方法相比,最大的优势在于检测的速度对人物的数量不敏感,在保持检测精度的情况下大幅提升了速度。
怎样快速的理解本文的内容,我尝试着讲下面一个故事:
有一张照片上有很多人在摆pose,老师正要给小朋友们讲这些人都在摆什么姿势。突然,一个叫VGG19的熊孩子把照片给撕得七零八碎。为了恢复出照片上的姿势信息,于是老师找来一些好朋友帮忙。
首先来帮忙的是分别叫CNN_S和CNN_L的两个闺蜜。CNN_S负责从碎片中把身体关节部位(头、肩、胳膊肘等)识别出来,并且按照关节部位将所有人的同一关节点坐标记录一个热图中。CNN_L擅长识别肢体部分(大臂、小臂…),同样,她也要把所有的人同一肢体记录到一张图像中。需要提醒的是:CNN_L只是判断出碎片里是否有肢体,无法判断肢体两端是胳膊肘还是膝盖,
下面的任务就是如何把肢体两端的关节点连接起来,并且最终拼接成人骨架结构,以表示当前人的姿势。
这个任务就交给了帕森(Parsing)大叔,大叔先拿了两张位置相连的关节热图(例如肩膀和胳膊肘的热图),根据CNN_L提供的肢体图,找到两张热图中最可能的关节对应关系。这个关节点的连线就带表了一个肢体。然后大叔重复按照此方法把身体的其他肢体都逐一找到,最后把这些找到的肢体按照位置关系进行拼接,就实现了图中所有人物姿势的还原。
好了,故事结束,希望这个故事能够对文章的理解产生一点帮助。下面介绍一下本文的亮点。
2.文章亮点
目前,已经有了许多关于检测的工作。许多的检测方式都是先想办法检测出身体的部位的关节点,然后再连接这些部位点得到人的姿态骨架。
本文的工作差不多也是这个套路,但是为了快速的把点连到一起,提出了Part Affinity Fields这个概念来实现快速的关节点连接。
上图展示了文章进行多人姿态检测的效果,下栏的子图展示了文章的亮点–Part Affinity Fields(部分亲和字段<求更好的翻译>)。Part Affinity Fields的关键作用就是可以实现一段躯干(limb)两端(part)的快速匹配。
个人理解: Part Affinity Fields就是一个向量,该向量代表了身体的一段躯干(如白花花的大腿…)
好了,文章的亮点介绍完了,下面介绍文章的主要内容。我认为,这篇文章主要工作就是要用CNN在图片中检测两个东东:
1. Part(关节点 或 身体部位) — Part Confidence Maps
例子:头、肩膀、胳膊肘…..
2. Part Affinity(肢体段)检测 — Par Affinity Fields
例子:大臂(不包含肩膀和胳膊肘)
3.姿势识别流程

处理过程:图片->10 layers of VGG-19 -> two branch of CNN –> part confidence St S t & part affinity fields Lt L t -> parsing -> pose
上面一张图展示了本文所述的图片处理网络架构,主要包括这么几个过程:
1. 准备一张包含人物的图片;
2. 利用VGG-19网络(熊孩子)的前10层对图片进行处理,得到图片的特征 F F ;
3. 特征 F F 通过一个连续的多阶段网络进行处理,网络的每个阶段( t t )包含了两个分支,其输入结果分别为 St S t (Part Confidence Map)和 Lt L t (Part Affinity Map)。
4. 其中: St S t 告诉我们哪些地方是头部,哪些地方是胳膊肘。 Lt L t 告诉我们哪些地方肯定在哪条白花花的大腿上。
5. 在 Lt L t 的帮助下,把 St S t 的坐标点连接起来,形成人的姿势骨架。
好了,网络架构大体上就是这样了,总结来说,这个网络主要的目的就是计算出 St S t 和 Lt L t ,既然这俩哥们这么重要,下面就来看看他们长啥样(抱歉直接贴了论文的图)?
好了,下面进入文章的核心:two branch CNN Networks
4.网络详解
本文使用了反复迭代的CNN网络进行检测,每个CNN网络都有两个分支,即闺蜜CNN_S和CNN_L,如下图所示:
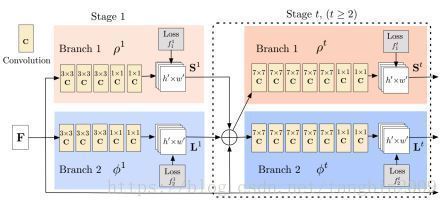
如图所示,本文所介绍的网络是一个不断迭代的网络连接。第1阶段和后续阶段的网络在形态上有所区别。每个阶段的两个网络分支分别用于计算部位置信图(Part Confidence Maps, 即关节点)和部位亲和域(Part Affinity Fields, 即肢体躯干)。
从图中还可以看出,网络的第1个阶段接收的输入是特征 F F ,经过网络的处理后分别得到 S1 S 1 和 L1 L 1 。从第2阶段开始,阶段 t t 网络的输入包括三部分: St−1,Lt−1,F S t − 1 , L t − 1 , F 。每个阶段网络的输入为:
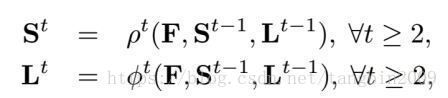
这样反复迭代,直到网络变得收敛。下图展示了CNN的两个分支计算的结果。

左边大图是待处理的原图,右边是处理后的结果。
其中,右上一栏图代表了检测到的关节点(Part),这就是 St S t ,江湖人称关节点置信图(Part Affinity Fields)。实际操作时,一个部位对应了一张置信图,请注意图中高亮像素。
右下一栏代表了一段躯干(图中是麒麟臂,也可以理解那条白花花的大腿),即 Lt L t ,文中给他取的名字叫Part Affinity Fields。同样,有多少个躯干就有多少个 PAFs P A F s 。
为什么作者要搞这样网络结构?我觉得有两篇文章可以参考,
Convolution Pose Machine
A deeper, stronger, and faster multiperson pose estimation model
- 第1篇文章提出了这种顺序循环迭代的的网络架构,其好处有两点:1.检测精度高,2.每个阶段都有损失函数,避免了梯度下消失的问题。
- 第2篇文章提出了先检测身体部位,然后再进行不同部位配对评分的方案,这跟每个阶段里的两个分支的思想比较类似。
4.1 网络收敛性判断
为了判断网络是否收敛,文中定义了网络的损失函数:
ftS f S t 和 ftL f L t 分别代表了两个输出图像的误差情况。其公式为:
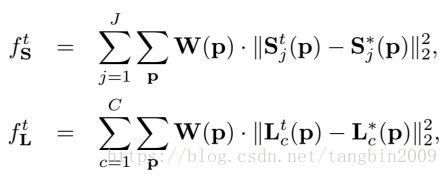
W(p) W ( p ) 是干啥的呢?因为数据的标注可能不完全,有些关节点没有被正确的标注上,就会导致上面公式中的 S∗j(p) S j ∗ ( p ) 和 L∗c(p) L c ∗ ( p ) 的值为0,从而导致损失函数的值特别大。这种情况下,令 W(p)=0 W ( p ) = 0 ,从而避免这种情况的出现。
下面的问题:为了计算损失函数,首先得计算 S∗j(p) S j ∗ ( p ) 和 L∗c(p) L c ∗ ( p ) 。即身体部位(part)和连接向量(affinity)的Groudtruth。
下面就开始介绍如何计算这俩哥们。
4.2 计算 S∗j(p) S j ∗ ( p )
S∗j(p) S j ∗ ( p ) 实际上就是求出一张图像上身体 j j 部位分布置信图(也称热点图)(请注意:左右两边图像是不同部位的热点图)

一个部位置信计算符合高斯分布,一张图像上有多个部位,所以是个多峰的高斯分布。(公式就不贴了,记住一个波峰就代表了一个胳膊肘就好)

4.3 计算 L∗c(p) L c ∗ ( p )

如上图所示,如果在图像中确定某人( k k )一段手臂(标记为 c c ),那么这幅图中任意位置 p p 的 L∗c(p) L c ∗ ( p ) 为:
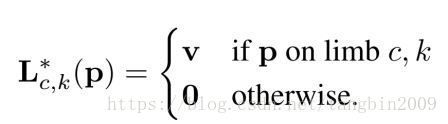
4.4 如何评估评估两点相连的可能性
前面说过,Part Affinity Fields的关键作用是用于判断两个部位是否相连,那他是怎么实现的呢?请看下面的公式:

dj1 d j 1 和 dj2 d j 2 分别是两个部位的位置(姑且认为是膝盖与踝关节坐标),如何判断这两点连起来就是一个躯干(白花花的小腿)?
解决方案就是计算从 dj1 d j 1 与 dj2 d j 2 连线上的线性积分。其中, p(u) p ( u ) 就是从 dj1 d j 1 到 dj2 d j 2 连线上的任意一点。
可见,如果 dj1dj2−→−− d j 1 d j 2 → 的方向与 L∗c(p) L c ∗ ( p ) 的方向一致, E E 的值就会很大,说明该位置是一个躯干的可能性就非常大。
5. 关节拼接
好啦,上一节讲了熊孩子把照片撕成了许多碎片,CNN_S和CNN_L阿姨费了老大劲从这些碎片中所有的身体部位(头、胳膊肘)和躯干(白花花的小腿)给找了出来。但是怎样将这些身体部位和躯干给正确的拼接起来呢?这时就要祭出我们的帕森(Parsing)大叔了( Section 2.4),事情的经过是这样的:

如上图所示,(a)被熊孩子撕掉的另一张照片,CNN阿姨在碎片中找到了肩膀( j1 j 1 )、胳膊肘( j2 j 2 )、手腕( j3 j 3 )的碎片,并将这些部位分别放到了3张照片里。帕森大叔任务就是要确保把图中每个人不同部位给正确的联结起来。他做了一下尝试:
5.1 拼接方法尝试
- 如图(b)所示,帕森大叔遍历了每张图片中的所有部位点,生成了一张全连接图。显然,要在这样的一张全连接图中把小明和小红的身体骨架给找出来是很难的,因为这是一个NP问题。此路不通!
- 如图(c)所示,根据不同部位的空间关系,帕森大叔把全连接进行了精简,仅保留有连接可能的边,(例如:胳膊肘肯定跟肩膀连接但必定不跟屁股相连。)这是一个K维匹配问题,仍然是NP-hard。放弃!
- 如图(d)所示,换个思路,从部位点出发把人的骨架搭起来是行不通,那就从躯干开始。例如,大臂的两端一定是肩膀和胳膊肘,那么就先把所有的肩膀和胳膊肘的连接图中进行搜索,因为有了 PAFs P A F s 的信息支撑,那么就可以很快把小明和小红的大臂分别找出来。然后,再分别找出小臂、小腿等其他躯干,再将这些躯干组合到一起形成人物姿势,问题就大大的被简化。
5.2 拼接过程
第一步,找出图中所有的小腿。下面的公式告诉我们该如何找小腿。
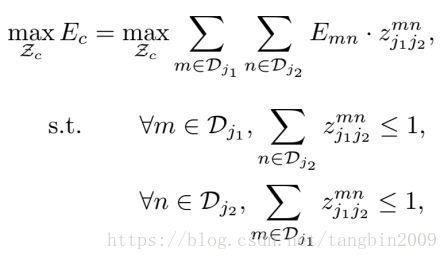
用 zmnj1j2=1 z j 1 j 2 m n = 1 来表示把膝盖( j1 j 1 )置信图中点 m m 和脚( j2 j 2 )置信图点 n n 连接起来的一个可能肢体搭配, Emn E m n 计算这样一个搭配的积分结果(依赖于 Lt L t )。 zmnj1j2=0 z j 1 j 2 m n = 0 表示点 m m 和 n n 不构成一个搭配。遍历所有的搭配,计算积分和。最终选择积分和最大的搭配组合代表原始图像中的所有小腿。
第二步,按照第一步的方法,分别去找出大臂、小臂、腰腹…
第三步,两个相邻的躯干必定有共享关节点,通过关节点再把所有的躯干结合起来,就可以得到所有人的身体骨架啦!
以上三个步骤是不是似曾相识,是不是很像构造一个最小生成树的过程?
再者,第一步和第二步中,不管一张图片有多少个人,先一股脑的把各个躯干给连起来,最后拼接起来就可以简单得到所有人的姿态,这就是自底向上(bottom-up)的实现过程。
好了,文章思想理解就介绍到这里。第一次尝试这种方式来记录文章阅读结果,有点语无伦次,希望大家多提提意见。
参考文献
VGG-19 https://arxiv.org/abs/1409.1556
CPM http://arxiv.org/abs/1602.00134
PEM https://arxiv.org/abs/1605.03170