1.2.3 大数据2.x 集群安装系列-- YARN配置启动
文章目录
- 1、三文件
- 2 etc/hadoop/mapred-site.xml
- 3 日志
- 4 etc/hadoop/yarn-site.xml:
- 5 同步配置文件到集群
- 6 实验准备
- 7 启动实验
- 8 另两台查看
- 9 WINDOWS访问产看节点
- 10 问题解决
- 11 重新启动
- 11 启动日志
1、三文件
yarn-env.sh
yarn-site.xml
mapred-site.xml --先用template生成
2 etc/hadoop/mapred-site.xml
:
cd /usr/local/hadoop/hadoop-3.2.1/etc/hadoop/
3 日志
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>bigdata-pro01.kfk.com:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>bigdata-pro01.kfk.com:19888</value>
</property>
</configuration>
4 etc/hadoop/yarn-site.xml:
主机 、日志聚集 、日志聚集存放多久
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata-pro01.kfk.com</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>10000</value>
</property>
</configuration>
5 同步配置文件到集群
scp -r ./* [email protected]:/opt/modules/hadoop-2.5.0/etc/hadoop/
scp -r ./* [email protected]:/opt/modules/hadoop-2.5.0/etc/hadoop/
6 实验准备
[kfk@bigdata-pro01 opt]$ ls
datas modules softwares tools
[kfk@bigdata-pro01 opt]$ cd datas
[kfk@bigdata-pro01 datas]$ ls
[kfk@bigdata-pro01 datas]$ touch wc.iput
[kfk@bigdata-pro01 datas]$ vim wc.iput
hadoop hive
hive spark
hbase java
java spark
7 启动实验
[kfk@bigdata-pro01 bin]$ ./hdfs dfs -put /opt/datas/wc.iput /user/kfk/data/
[kfk@bigdata-pro01 hadoop-2.5.0]$ sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to //opt/modules/hadoop-2.5.0/logs/yarn-kfk-resourcemanager-bigdata-pro01.kfk.com.out
[kfk@bigdata-pro01 hadoop-2.5.0]$ sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to //opt/modules/hadoop-2.5.0/logs/yarn-kfk-nodemanager-bigdata-pro01.kfk.com.out
[kfk@bigdata-pro01 hadoop-2.5.0]$ jps
3184 ResourceManager
3426 NodeManager
3530 Jps
2525 DataNode
2447 NameNode
8 另两台查看
[kfk@bigdata-pro02 hadoop-2.5.0]$ sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to /opt/modules/hadoop-2.5.0/logs/yarn-kfk-nodemanager-bigdata-pro02.kfk.com.out
[kfk@bigdata-pro02 hadoop-2.5.0]$ jps
2291 DataNode
2725 Jps
2619 NodeManager
[kfk@bigdata-pro03 hadoop-2.5.0]$ sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to /opt/modules/hadoop-2.5.0/logs/yarn-kfk-nodemanager-bigdata-pro03.kfk.com.out
[kfk@bigdata-pro03 hadoop-2.5.0]$ jps
2610 NodeManager
2310 DataNode
2717 Jps
9 WINDOWS访问产看节点
http://bigdata-pro01.kfk.com:8088/cluster
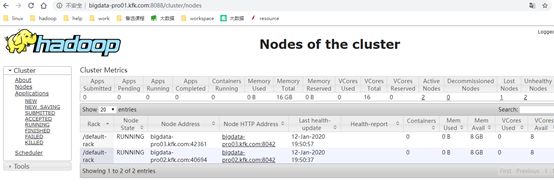
10 问题解决
只有两台起来了 还一台报不健康 查看日志发现 警告和错误
nodemanager. DirectoryCollection: Unable to create directory /modules/hadoop-2.5.0/logs/userlogs error mkdir of
1/1 log-dirs turned bad: /modules/hadoop-2.5.0/logs/userlogs
1、解决思路授权权限未果
2、手工创建文件夹未果
3、重新停服务 格式化 bin/hdfs namenode -format
这里需要注意的点是需要把存放dfs文件全部删了
默认在/tmp/目录下的 hadoop yarn namenode datanode 等和hadoop相关的通通删了 。
4、去其他从服务器也通通删了
5、启动HDFS后 (主namenode datanode 从 datanode )
6、再重试resourcemanager nodemanager 命令 终于成功 目录和文件都要重建重传了

11 重新启动
[kfk@bigdata-pro01 hadoop-2.5.0]$ sbin/hadoop-daemon.sh start namenode
[kfk@bigdata-pro01 hadoop-2.5.0]$ sbin/hadoop-daemon.sh start datanode
[kfk@bigdata-pro01 hadoop-2.5.0]$ sbin/yarn-daemon.sh start resourcemanager
[kfk@bigdata-pro01 hadoop-2.5.0]$ sbin/yarn-daemon.sh start nodemanager
[kfk@bigdata-pro01 hadoop-2.5.0]$ jps
7426 NameNode
7523 DataNode
7988 Jps
7879 NodeManager
7631 ResourceManager
[kfk@bigdata-pro01 hadoop-2.5.0]$ bin/hdfs dfs -mkdir -p /user/kfk/data/
[kfk@bigdata-pro01 hadoop-2.5.0]$ bin/hdfs dfs -put /opt/datas/wc.iput /user/kfk/data/
11 启动日志
[kfk@bigdata-pro01 hadoop-2.5.0]$ sbin/mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /opt/modules/hadoop-2.5.0/logs/mapred-kfk-historyserver-bigdata-pro01.kfk.com.out
[kfk@bigdata-pro01 hadoop-2.5.0]$ jps
7426 NameNode
7523 DataNode
8294 Jps
7879 NodeManager
8254 JobHistoryServer
7631 ResourceManager