光学神经网络 Optical neural network
之前有个博士的课程需要写一个文献综述,于是选了个现在比较热门的话题“光学神经网络ONN”,和大家分享一下。光学神经网络(Optical neural network, ONN)能有效减轻软件和电子硬件两者的部分运算,为替代人工神经网络提供了一种具有前景的方法。人工神经网络中耗能和耗时最多的部分是密集矩阵乘法。但在光学神经网络中,矩阵乘法可以在光速下执行。人工神经网络中的非线性在光学神经网络中也可以通过非线性光学元件实现。并且,一旦光学神经网络训练完成,这个结构可以在无额外能量输入的情况下执行光信号计算。此外,光学神经网络还具有高带宽、高互联性、内在的并行处理等特点。目前,光学神经网络可以分为光电混合神经网络(Hybrid optical-electronic neural network)和全光神经网络(All-optical neural network)两大类。其中光电混合神经网络可以实现卷积神经网络的功能,但是该网络的光学部分只能实现卷积的功能,经光电转换后得到的电信号继续在电子神经网络中传播。而全光神经网络虽然无需光电转换的过程,却无法实现卷积的效果,只能完成全连接层的功能。根据使用的主要光学元件的不同又可以将全光神经网络分为光子芯片(nanophotonic circuit)、被动衍射光学元件(passive diffractive layer)、散射材料三类。
- 基于角度敏感传感器的光电混合神经网络
(Chen, H. G. et al. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 903-912.)
2016年,美国康奈尔大学的Huaijin G. Chen等人首次提出ASP-Vision的概念。他们使用一种仿生的角度敏感传感器(angle sensitive pixel, ASP)来取代卷积神经网络的第一层卷积层。这种新型的硬件与算法相结合的光电混合型网络结构被称为ASP-Vision。ASP是一种衍射型传感器,通过光学卷积的方式对图像进行边缘滤波,能同时进行图像的获取以及图像的滤波,该传感器可以显著节省系统功耗,降低数据带宽以及减少浮点运算量,ASP-Vision结构如下图所示。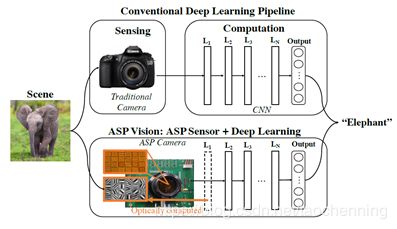
与传统深度学习网络相比,ASP-Vision系统可以节省97%的能耗和90%的传输带宽。ASP是一种通过CMOS工艺生产的集成了衍射光栅的光电二极管器件。它基于一种被称为塔伯效应(Talbot effect)的近场衍射现象。当平面波入射到周期性衍射光栅时,光栅的像会在光栅后重复出现。光栅像出现的间隔zt称为塔伯长度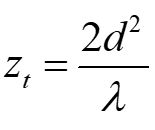 其中,d是光栅周期,λ是入射光波长。并且,塔伯效应所成的像会随入射光角度发生水平位移。如果在第一个光栅(基础光栅)后塔伯长度处放置第二个光栅(分析光栅),可以对入射光实现周期性强度调控。如下图所示
其中,d是光栅周期,λ是入射光波长。并且,塔伯效应所成的像会随入射光角度发生水平位移。如果在第一个光栅(基础光栅)后塔伯长度处放置第二个光栅(分析光栅),可以对入射光实现周期性强度调控。如下图所示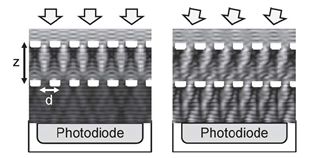
出射光光强为
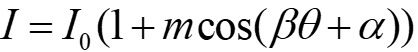
其中m和β是与光栅的角度敏感性有关的参数,θ是光波入射角,α是两个光栅的相位横向偏移。通过计算像素点相位为α和α+π时光强的差值,我们可以得到该公式中与直流项无关、只与入射角度有关的项。这个过程与滤波器在频域进行特征提取的过程相似。ASP将不同周期、不同方向和不同相位的光栅平铺,且与像素点一一对应,从而实现光学卷积,如下图所示。


图中,4×6个子像素平铺组成一个ASP像素。每个子像素大小为10微米,分别对应不同频率、方向和相位的塔伯滤波。上图为ASP其中一个卷积核的输出。使用ASP实现光学卷积最大的限制在于ASP会极大降低图像分辨率。并且ASP像素光能利用率极低,只有10%的量子效率,使得硬件系统中噪声很大。虽然经优化后量子效率有所提升,大约能实现50%,这仍是限制ASP应用的一大因素。目前ASP只能替代卷积神经网络的第一层。 - 基于衍射光学元件的光电混合神经网络
(Chang, J., Sitzmann, V., Xiong, D., Heidrich, W. & Wetzstein, G. J. S. R. Hybrid optical-electronic convolutional neural networks with optimized diffractive optics for image classification. 8, 12324- (2018).)
2017年,美国斯坦福大学的Julie Chang等人提出了基于衍射光学元件的光电混合神经网络,也是在电子计算前加入一层卷积运算,从而减少网络的计算量。不过与1中使用的元件不同,这里使用的是衍射光学元件。

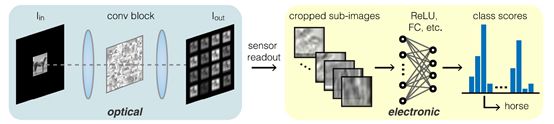
在线性光学系统中,输出图像是输入图像和系统点扩散函数的卷积
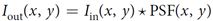
*是2D卷积符号。而由两个焦距均为f的凸透镜组成的“4f系统”,能够实现级联的两个傅里叶变换。如图5所示,第一个透镜摆放在距离物面f远处,透镜后f处为第一个透镜的傅里叶面。第二个透镜放置在该傅里叶面后f远处,并在距物面4f距离处产生共轭像面。若在 “4f系统”中间的傅里叶平面放入相位板对入射光的振幅和相位进行调制,这个过程就是卷积。为了实现多卷积操作,将相位板划分为多个平铺的卷积核。若单个卷积核的位移分别为x和,那么PSF可以描述为
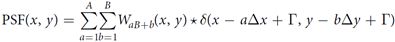
这里T是该PSF相对于原始光轴的位移。相应的卷积过程可以写成

不过与电子卷积神经网络不同的是,这样输出的是平铺的2D图像,而不是与电子神经网络相似的在第三个维度堆叠的图像。经卷积操作后的光信号由CCD接收转换为电信号并进入电子神经网络继续传播。如图所示,CCD读出的图像经划分得到多个卷积操作子图像。然而,这个系统的图像分辨率也对应下降,且只能实现非负卷积。当PSF优化完成后,整个系统的非相干PSF可以用4f系统的孔径传递函数(ATF)表示为
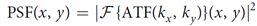
这里,F表示2D傅里叶变换,kx/ky 表示空间频率,λ是波长,f是透镜的焦距。ATF是一个复函数,可以分解成振幅和相位
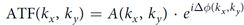
这里,A可以通过相位板的透过率进行调制,而相位信息可以通过相位板的厚度变换实现。在这篇文章中,作者采用Google QuickDraw数据集进行测试,共采用了16个32×32大小的卷积核,实现了72.2%的正确率。而如果是同样结构的电子神经网络,但卷积核是以堆叠的形式存在,正确率为75.9%。 - 全光衍射神经网络
这一篇之前写过就不写啦。 - 全光纳米光子神经网络
(Shen, Y. et al. Deep learning with coherent nanophotonic circuits. 11, 441 (2017).)
2017年,美国麻省理工学院的Yicheng Shen等人,提出了一种全光学神经网络的新架构,在硅光子集成电路中使用56个马赫曾德干涉仪 (Mach–Zehnder interferometer, MZI) 的级联阵列构成可编程纳米光子处理器(programmable nanophotonic processor, PNP),并用于元音识别。该网络结构如下图所示,由输入层、输出层、以及中间各隐藏层构成。中间各隐藏层包括光学干涉单元(OIU)和光学非线性单元(ONU),分别起到矩阵乘法和激活函数的作用。OIU由基于马赫曾德干涉仪阵列的可编程纳米光子器实现。马赫曾德干涉仪由前后两个3dB定向耦合器连接上下两个硅波导分支构成。内移相器通过改变波导折射率控制输出分光比,外移相器控制差分输出、相位延迟。ONU可由饱和吸收器、光学双稳态等具备非线性特征的光学硬件实现。

该网络的训练也是由计算机实现。其中,每层权重实矩阵M经奇异值分解(SVD)后,可得到酉矩阵U 、V†, 对角矩阵Σ
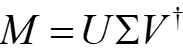
因为任意的酉矩阵都可以表示为一系列旋转矩阵的乘积,如果继续对酉矩阵进行分解,可以得到
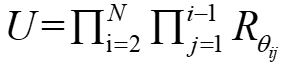
Rθij矩阵是单位矩阵,并用cosθ, -sinθ, sinθ, cosθ分别替换矩阵中的元素Iii, Iij, Iji, Ijj。假设U是4×4的酉矩阵,那么Rθij也是4×4的矩阵,并且计算得到的6个θ角的恰好对应一个4×4全连接层所需要的6个马赫曾德干涉仪的相位角,如下图所示(序号1~6)
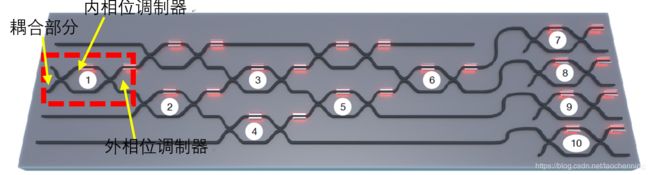
实验中一个OIU单元如下图所示。其中,红线部分完成矩阵乘法的功能,蓝线实现衰减功能。

ONU单元由可以集成到纳米光子电路的饱和吸收器实现(例如燃料分子、半导体、石墨饱和吸收器或饱和放大器等)。对于入射光Iin,出射光由非线性方程Iout=f(Iin)给出。这篇文章使用的饱和吸收器的模型是
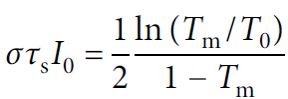 其中σ是吸收截面,τs是吸收材料的辐射寿命,T0是初始透过率,I0是入射光强,Tm是该材料的透过率。一旦I0给定,Tm(I0)可以通过该公式解的,出射光强可以通过Iout= I0 Tm(I0)求得。
其中σ是吸收截面,τs是吸收材料的辐射寿命,T0是初始透过率,I0是入射光强,Tm是该材料的透过率。一旦I0给定,Tm(I0)可以通过该公式解的,出射光强可以通过Iout= I0 Tm(I0)求得。
文中,利用该方法制作的包含2层全连接层的神经网络,识别元音字母的正确率为76.7%。而等价的电子神经网络可实现的正确率为91.7%。该方法仍有较大提升空间。随后,该研究组在MZI全光神经网络的基础上进行了进一步的研究,利用电子器件的配合实现了光学卷积神经网络。但由于这种光学神经网络必须有电子器件实现对于图像的向量化以及对于化作乘法的卷积操作结果的求和,所以无法以真正的光学神经网络的速度完成计算 - 可训练的光子神经网络
(Hughes, T. W., Minkov, M., Shi, Y. & Fan, S. H. Training of photonic neural networks through in situ backpropagation and gradient measurement. Optica 5, 864-871, doi:10.1364/Optica.5.000864 (2018).)
神经网络中的矩阵乘法,可以通过光路有效地完成。但是,目前并没有一种高效的网络训练方法应用于基于集成光子平台的神经网络。之前提出的全光神经网络,正确率远低于等价电子神经网络。2018年,美国斯坦福大学的Tyler W. Hughes等人提出一种高效、局部训练神经网络的方法,通过伴随变量的方法(adjoint variable)获得后向传播中光路的参数(主要是光路中关键元件的介电常数),与常见的神经网络计算梯度的方法类似。并且,这些梯度可以通过器件的强度测量来得到。
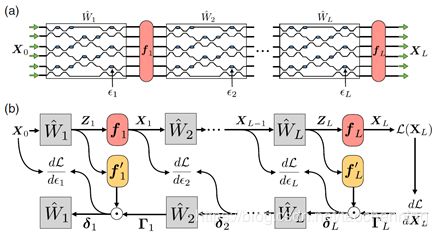
如图所示,假设输入、输出端分别为Xin和Zout,他们之间的关系可以表示为

其中W^是该层的传输矩阵。决定于该层相位偏移器的介电常数εl。同时,也组成了系统的全散射矩阵
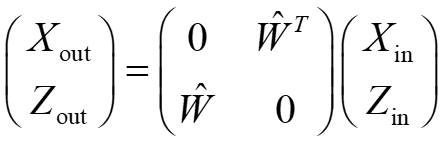
如果在线性运算后有一个点乘的非线性激活函数fl(·),那么每层l(输出层为L,l=1…L)可写为表达式

如果使用均方误差作为系统的损失函数,如下式
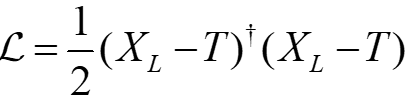
其中T是系统对应输入X0的目标输出。那么,可以计算出该系统最后一层的介电常数εL对应于损失函数的导数
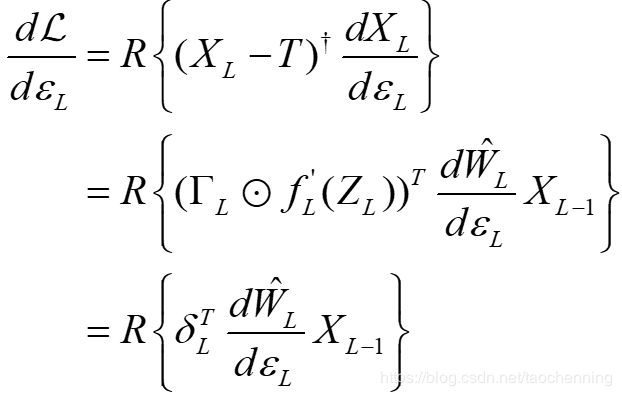
这里,符号⊙是矢量点乘运算符,R{·}代表实数部分,fl’(·)是对第l层激活函数求导,并定义。对于任意的l
接下去是通过电磁伴随变量的方法计算梯度。假设有一稳态的、频率为ω的源,Maxwell’s方程可以写成

更简洁的表达式是
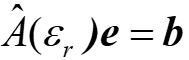
这里描述了相对介电常数的空间分布,k0 =ω/c是自由空间的波数,e是电场分布,j是电流密度,b是源,并且由于洛伦兹互易定理,。为了将这个公式与传输矩阵联系起来,定义一系列源bi,i∈1…2N,对应于各输入输出端(假设有N个输入端和N个输出端)。那么e和Xin之间的关系为

对应于输入端i=1…N,或者也可以写成

类似地,有
对应于输出端i+N=(N+1)…2N,或者写成
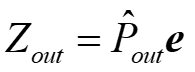
那么求梯度的式子可以写成
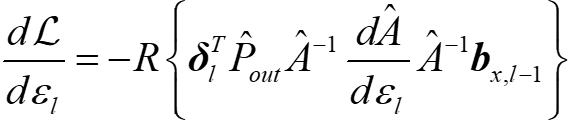
定义原始量(og)和伴随量(aj)
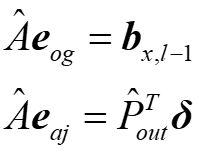
上式可以写成

其中rØ是相位偏移器对应的一系列点。注意到,eog和eaj干涉后形成的强度图案中最后一项即为计算梯度所需要的量
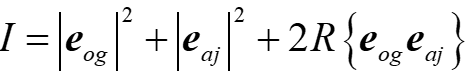
那么只要OIU中可以产生eaj,梯度的测量就可以单纯地通过测量光强实现。

上图展示了实验测量梯度的方法。首先,如(a)所示,正向输入原始场Xl-1,记录各相位偏移器处强度,即|eog|2。然后,反向输入(a)中实际输出与理想输出的差值,记录各相位偏移器强度,即| eaj*|2。(b)中反向输出为时逆伴随场,可以通过计算得到
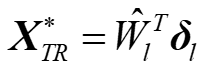
如©中所示,同时输入原始场和时逆场,发生干涉,记录各相位偏移器强度,将(a)、(b)步中的常数强度项减去,与相乘,即可获得梯度。
随后Tyler W. Hughes又将伴随变量方法应用在非线性光学器件上,梯度计算可以直接包括这些器件的非线性响应,这里就不做介绍了。文章是Hughes, T. W., Minkov, M., Williamson, I. A. & Fan, S. J. A. P. Adjoint method and inverse design for nonlinear。
nanophotonic devices. 5, 4781-4787 (2018).
总结一下,利用光学方法加速或直接实现神经网络计算,作为光学与人工智能的两大领域的有效结合,已经吸引了大量的研究人员的关注与重视,并在短短几年时间内得到了高速的发展。光学神经网络分为两种,一种为光电混合神经网络,指的是利用光学方式加速神经网络中计算负担较大,或是计算成本较高的部分,在光学加速完成后与常见的基于电路硬件的神经网络并无本质区别;而另外一种是全光神经网络,指的是在经过了一定的调制手段以后,将信息加载在光的强度、相位或者偏振等特征上,并通过光的干涉、衍射、偏振或者散射等特性直接实现神经网络的计算,在计算过程中并不涉及光电转换的过程,运算结果直接体现在光的输出特性上。光电混合神经网络在传统电路硬件的神经网络的基础上改进,一般具有加速运算并节约计算时间、能耗以及信息传输带宽的特点。而全光神经网络由于光的频率远高于电路频率的特点,一般具备超高速运算,超高运算带宽的特点。而由于发展年限较短,光学神经网络仍然存在许多值得改进的地方。对于基于角度敏感传感器的光电混合神经网络来说,第一层的ASP元件仅仅能够实现卷积操作,并在卷积操作以后必须转为电信号。而且ASP能够实现的卷积操作仅仅为某个方向上的某个特定频率的差分运算,同时由于ASP元件的效率很低,而且元件的数量也具有一定的要求,对于完全复原卷积神经网络的第一层来说并不具备实际价值。而基于衍射光学元件的光电混合神经网络与常见的4f傅里叶光学系统并没有本质上的区别,光学运算的结果仍然具有较大的信息量。由于输入了更多的相同大小的光学计算结果,后续的卷积与池化操作并未由光学方式进行代替,在原来的基础上甚至增加了电路的运算量,也无法起到以光学方法有效加速神经网络的效果。而对于全光衍射神经网络来说,D2NN结构确实能够高效计算神经网络中最常见的矩阵运算,但是由于在D2NN器件中,未引入任何非线性项以实现神经网络中至关重要的激活函数,实际上并不能够称作实现了神经网络。而全光纳米光子电路神经网络主要基于波导模式与相位调制的MZI,数学过程相较于其他所有全光神经网络更加清晰,便于加载任何形式的神经网络。但是由于全光纳米光子电路神经网络是将任意矩阵做SVD分解,再将酉矩阵分解为许多有效元素为2×2的旋转矩阵,每个旋转矩阵对应于一个MZI,如果需要实现较大尺寸的矩阵则对于MZI的个数有过大的要求(一个酉矩阵需要N(N-1)/2个MZI,N为矩阵尺寸),在实际应用中仍然存在较大限制。而可训练的光子神经网络将实际的应用效果直接加载在结构的优化过程中,结构的优化更加简单可靠,而且由于能够直接支持非线性项的引入,可以有效实现神经网络中必须的激活函数的要求。基于随机散射的结构可以类比于基于MZI的波导模式,尽管在数学过程上无法给出清晰的分解过程,但由于随机散射结构压缩了器件大小,大大降低了器件的制作成本。不过因为研究时间较短,基于可训练的神经网络还处于演示阶段,没有能够实现较为复杂的神经网络功能,希望未来能够有较为成熟的应用实例。目前,全光神经网络仍然具有一个共同的问题,即为无法实现在全光层面直接实现卷积计算,这对于全光神经网络在代替电路神经网络上是一个阻碍,使用其他方式在全光层面实现高效的卷积计算,以完全复原卷积神经网络仍然是一个巨大的挑战。同时,由于目前的神经网络的计算成本主要集中于训练过程中,所以光学神经网络需要具备可训练性,而不仅仅是可以复现神经网络。并且,为了更好的挖掘神经网络的潜力,全光神经网络必须具备非线性特性以实现重要的激活函数功能。希望在不远的将来,光学神经网络能够以光学方式代替神经网络中部分或全部的计算过程,为人工智能的发展与普及做出重要贡献。