编译与静态链接
最近一段时间做了关于一些软件的交叉编译工作,由于觉得并没有学到许多东西,所以抽时间看了关于静态链接方面的内容,读了一部分《程序员的自我修养——链接、装载与库》,记录一些读书笔记及自己的总结。
一、GCC做了什么?
我们在Linux中经常使用
gcc 源文件名.c -o 目标可执行文件名对一个编写好的C文件进行编译生成可执行文件,那么这之间的细节呢?
这里源文件名为 hello.c ,生成可执行文件名为 hello 为例子 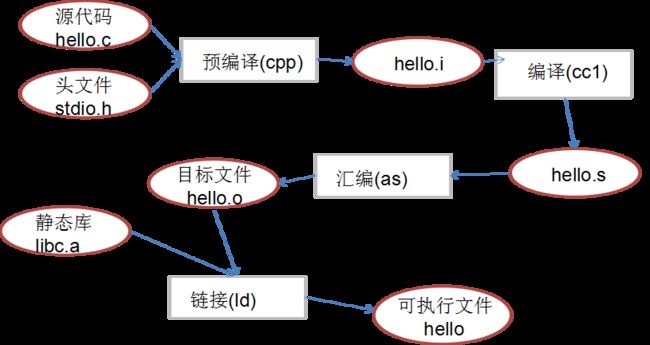
gcc一个C源文件时对过程进行了隐藏,实际为:预编译 cpp、编译 cc1、汇编 as、链接 ld,其中每一步后的英文名是所使用的工具的名称。
那么各自的步骤到底干了什么呢?
1、预编译:处理.c文件中以“#”开头的预编译指令。
这些预编译指令包括了宏定义、条件预编译指令等等,此步中也会进行删除掉所有的注释等操作。当无法判断一个宏定义是否正确或者头文件是否正确包含的话,可以直接打开此步生成的文件进行检查。
gcc -E hello.c -o hello.i2、编译:进行词法分析、语法分析、语义分析等工作,此步所生成的文件是以汇编代码构成的。
这一步是由编译器cc1完成(gcc中),主要分为词法分析、语法分析、语义分析、中间语言生成、目标代码生成与优化几步。
a.词法分析:将所有的C语言源代码分割为一系列的记号,这些记号主要为关键字、标识符、常量及特殊符号,比如表达式 a+b 在这步中就会被拆分为 a 和 b 两个标识符及 + 这个特殊符号。
b.语法分析:产生语法树,关于这步需要有一些数理逻辑的知识,即生成以表达式为节点的树,对应上面 a+b 的情况是 + 为一个节点,而 a 和 b 分别为左右子树的节点。
c.语义分析:确定每个节点的类型,比如整型、字符型等。
可以理解为在前一步的树的基础上在每个节点上都标示好类型,对于一些隐式转换及强制类型转换都会在这步中进行处理。d.中间语言生成:进行两步操作,首先将语法树转化为中间代码,然后在中间代码中对已经能够确定值的表达式进行求值。
其中中间代码一般为三地址码,即x = y op z的形式,其中op代表特殊符号,然后如果有些表达式能够确定其值,比如 t1=5+6 这种两个常量相加的语句就直接进行计算。e.目标代码生成与优化:如字面意思,进行目标代码的生成与优化。
关于目标代码的生成与具体的硬件平台有关,而优化部分有部分操作,比如合适的寻址方式、对于乘法运算使用位移进行代替,这些如果有接触汇编代码会比较了解。
编译器流程图: 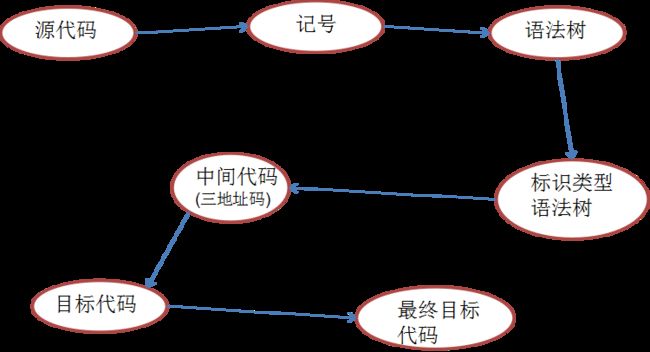
此步中生成的文件如果懂得汇编代码的话仍然是可读的
gcc -S hello.c -o hello.s3、汇编:将汇编代码转变成机器可以执行的指令。
此步中是根据汇编指令与机器指令的对照表进行一一翻译,基本上一个汇编语句对应一条机器指令。
此步生成的文件已经没法读了,打开后全部是乱码,因为已经全部机制指令了。
gcc -c hello.s -o hello.o
或
gcc -c hello.c -o hello.o
或
as hello.s -o hello.o4、链接:将几个输入的目标文件加工后合并为一个输出文件。
简单来说,可以看作拼拼图的过程,每个.o文件都是一块拼图碎片,链接就是将它们拼接成一幅图(可执行文件)的过程。
Linux中可执行文件都称为ELF文件,Windows中为PE文件,之后都会这样称呼
总结:
经过上面的几步我们大致了解了编译的过程,尤其是gcc的编译器cc1对源文件的操作步骤。
下面是在32位的Ubuntu中对 hello.c 文件进行动态编译显示的详细信息,静态编译与之类似:
gcc --verbose -fno-builtin hello.c //--verbose 表示显示编译的详细信息,-fno-builtin表示关闭内置函数优化选项,因为hello.c文件中用printf只对一个字符串进行输出,此时GCC会将其自动替换为puts函数。Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/i686-linux-gnu/4.8/lto-wrapper
Target: i686-linux-gnu
Configured with: ../src/configure -v --with-pkgversion='Ubuntu 4.8.4-2ubuntu1~14.04.1' --with-bugurl=file:///usr/share/doc/gcc-4.8/README.Bugs --enable-languages=c,c++,java,go,d,fortran,objc,obj-c++ --prefix=/usr --program-suffix=-4.8 --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --with-gxx-include-dir=/usr/include/c++/4.8 --libdir=/usr/lib --enable-nls --with-sysroot=/ --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --enable-gnu-unique-object --disable-libmudflap --enable-plugin --with-system-zlib --disable-browser-plugin --enable-java-awt=gtk --enable-gtk-cairo --with-java-home=/usr/lib/jvm/java-1.5.0-gcj-4.8-i386/jre --enable-java-home --with-jvm-root-dir=/usr/lib/jvm/java-1.5.0-gcj-4.8-i386 --with-jvm-jar-dir=/usr/lib/jvm-exports/java-1.5.0-gcj-4.8-i386 --with-arch-directory=i386 --with-ecj-jar=/usr/share/java/eclipse-ecj.jar --enable-objc-gc --enable-targets=all --enable-multiarch --disable-werror --with-arch-32=i686 --with-multilib-list=m32,m64,mx32 --with-tune=generic --enable-checking=release --build=i686-linux-gnu --host=i686-linux-gnu --target=i686-linux-gnu
Thread model: posix
gcc version 4.8.4 (Ubuntu 4.8.4-2ubuntu1~14.04.1)
COLLECT_GCC_OPTIONS='-v' '-fno-builtin' '-mtune=generic' '-march=i686'
/usr/lib/gcc/i686-linux-gnu/4.8/cc1 -quiet -v -imultiarch i386-linux-gnu hello.c -quiet -dumpbase hello.c -mtune=generic -march=i686 -auxbase hello -version -fno-builtin -fstack-protector -Wformat -Wformat-security -o /tmp/ccM5JRqF.s
GNU C (Ubuntu 4.8.4-2ubuntu1~14.04.1) version 4.8.4 (i686-linux-gnu)
compiled by GNU C version 4.8.4, GMP version 5.1.3, MPFR version 3.1.2-p3, MPC version 1.0.1
GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072
ignoring nonexistent directory "/usr/local/include/i386-linux-gnu"
ignoring nonexistent directory "/usr/lib/gcc/i686-linux-gnu/4.8/../../../../i686-linux-gnu/include"
#include "..." search starts here:
#include <...> search starts here:
/usr/lib/gcc/i686-linux-gnu/4.8/include
/usr/local/include
/usr/lib/gcc/i686-linux-gnu/4.8/include-fixed
/usr/include/i386-linux-gnu
/usr/include
End of search list.
GNU C (Ubuntu 4.8.4-2ubuntu1~14.04.1) version 4.8.4 (i686-linux-gnu)
compiled by GNU C version 4.8.4, GMP version 5.1.3, MPFR version 3.1.2-p3, MPC version 1.0.1
GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072
Compiler executable checksum: aaaa08c6fefb26a9d107c18441ada1ef
COLLECT_GCC_OPTIONS='-v' '-fno-builtin' '-mtune=generic' '-march=i686'
as -v --32 -o /tmp/ccs3h630.o /tmp/ccM5JRqF.s
GNU汇编版本 2.24 (i686-linux-gnu) 使用BFD版本 (GNU Binutils for Ubuntu) 2.24
COMPILER_PATH=/usr/lib/gcc/i686-linux-gnu/4.8/:/usr/lib/gcc/i686-linux-gnu/4.8/:/usr/lib/gcc/i686-linux-gnu/:/usr/lib/gcc/i686-linux-gnu/4.8/:/usr/lib/gcc/i686-linux-gnu/
LIBRARY_PATH=/usr/lib/gcc/i686-linux-gnu/4.8/:/usr/lib/gcc/i686-linux-gnu/4.8/../../../i386-linux-gnu/:/usr/lib/gcc/i686-linux-gnu/4.8/../../../../lib/:/lib/i386-linux-gnu/:/lib/../lib/:/usr/lib/i386-linux-gnu/:/usr/lib/../lib/:/usr/lib/gcc/i686-linux-gnu/4.8/../../../:/lib/:/usr/lib/
COLLECT_GCC_OPTIONS='-v' '-fno-builtin' '-mtune=generic' '-march=i686'
/usr/lib/gcc/i686-linux-gnu/4.8/collect2 --sysroot=/ --build-id --eh-frame-hdr -m elf_i386 --hash-style=gnu --as-needed -dynamic-linker /lib/ld-linux.so.2 -z relro /usr/lib/gcc/i686-linux-gnu/4.8/../../../i386-linux-gnu/crt1.o /usr/lib/gcc/i686-linux-gnu/4.8/../../../i386-linux-gnu/crti.o /usr/lib/gcc/i686-linux-gnu/4.8/crtbegin.o -L/usr/lib/gcc/i686-linux-gnu/4.8 -L/usr/lib/gcc/i686-linux-gnu/4.8/../../../i386-linux-gnu -L/usr/lib/gcc/i686-linux-gnu/4.8/../../../../lib -L/lib/i386-linux-gnu -L/lib/../lib -L/usr/lib/i386-linux-gnu -L/usr/lib/../lib -L/usr/lib/gcc/i686-linux-gnu/4.8/../../.. /tmp/ccs3h630.o -lgcc --as-needed -lgcc_s --no-as-needed -lc -lgcc --as-needed -lgcc_s --no-as-needed /usr/lib/gcc/i686-linux-gnu/4.8/crtend.o /usr/lib/gcc/i686-linux-gnu/4.8/../../../i386-linux-gnu/crtn.o 其中最重要的三句已经用红字表示了出来,可以看到一个最简单的helloworld程序都需要链接许多.o目标文件才能够得到ELF文件。
从上看出,gcc实际上是对cpp、cc1、as、ld几个后台程序的包装,执行它时会根据具体的参数要求去调用这几个后台程序,从而得到我们所需要编译出的ELF文件。
二、静态链接
刚刚将gcc的几个步骤拆开了了解各步骤作用,具体分析了其中cc1编译的部分,关于预编译与汇编的部分不细究,接下来就剩链接ld了。
从刚刚的gcc详细信息可以看出,实际过程中链接的.o文件有很多,那么为什么会这么多,它们在哪呢?
接着刚刚gcc中第四个部分链接的部分说下去,这里开始分为了两个分支:动态链接与静态链接,静态链接一般用于交叉编译等情况,而动态链接则较为常用,当我们需要静态链接时需要指定 -static 参数,否则都默认为动态链接。
动态链接与静态链接有什么不同?
动态编译的文件需要附带一个动态链接库,在文件执行时需要调用动态链接库中的一些命令,所以没有这个库就没办法运行。优点:既缩小了执行文件本身的体积,又加快了编译的速度;缺点:首先即便程序只用到了链接库很少的命令也需要携带一个庞大的动态链接库,否则程序无法执行,而且当其他设备上没有此链接库时就无法运行。
静态编译会在编译文件时将文件所需要调用的对应链接库中的部分提取出来,链接到可执行文件中去,使程序在执行时不依赖链接库。
可以看出动态编译与静态编译的优点与缺点基本是互补的,可移植性和编译速度两者对立。
这里我们只讨论静态链接。
前面说过链接器进行不同模块之间的拼接工作,主要包括地址和空间分配、符号决议及重定位步骤,下面来看这些步骤到底做了什么。
1、地址与空间分配
对于链接器ld来说,其需要做的事情就是把多个输入的目标文件(.o文件)合并为一个文件,即ELF可执行文件。
那么对于多个目标文件,如何合并?或者说,空间如何分配?
下面提供了两种方法:
a.按序叠加 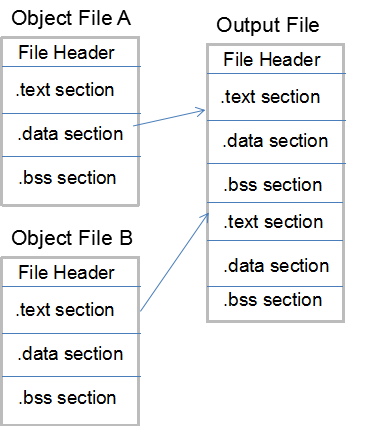
可以看到图中有着A、B两个目标文件,将它们组合起来时按照各自的代码段、数据段、bss段依次叠加,于是形成的ELF可执行文件中有着多个代码段、数据段等
此种方法很明显是非常浪费空间的,在进行地址与空间分配时,都需要一定的对齐,那么这样就会造成内存中存在大量的内部碎片,因此提出了第二种方案。
b.相似段合并 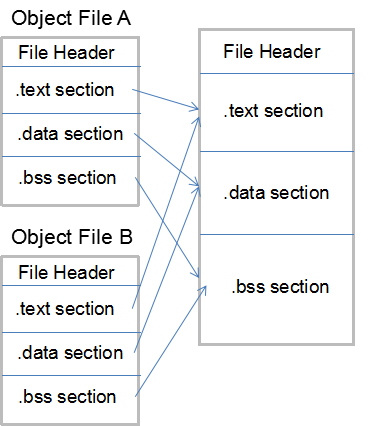
此种方法将多个目标文件相似段组合在一起,即代码段、数据段等都将它们合并然后进行分配。
这种方法比按序叠加的方法要减少许多浪费的空间,且一个ELF文件中代码段、数据段等都只有一个,更易查看,因此链接器基本使用第二种策略进行链接。
使用此种策略的链接器都采用两步链接法的方法进行链接,第一步为空间与地址分配,第二步为符号解析与重定位,这也是之前所说的链接的主要步骤。
上面是两种合并目标文件的策略,那么现在来看看到底什么叫做地址与空间的分配?
事实上这里的地址与空间包含了两层意思,一个是指ELF文件中的空间,另一个就是指文件装载后在虚拟地址中的虚拟地址空间,两者之间有什么区别呢?我理解是一个是存放文件所需要的空间,而另一个是执行时所需要的空间。看下bss段与代码段等段的区别就知道了,bss段只有在执行时才会用到,所以在实际的目标文件及ELF文件中,bss段是不会分配空间的,但是在装载后的虚拟地址空间中bss段就会为其分配相应的空间,而代码段则两种空间都会分配。
我们来看下两个目标文件的链接过程以及其中的段的地址空间分配:
/*a.c*/
extern int shared;
int main ()
{
int a = 100;
swap(&a, &shared);
}
/*b.c*/
int shared = 1;
void swap(int *a, int *b)
{
*a ^= *b ^= *a ^= *b;
}我们不需要去细究两个文件到底干了什么,只需要知道 a.c中调用了定义在b.c中的shared变量以及swap函数,接下来将两者分别编译,然后链接
gcc -c a.c b.c //编译成目标文件,产生a.o、b.o
ld a.o b.o -e main -o ab //链接a.o、b.o得到可执行文件ab,其中-e参数用于指定程序入口,ld的默认程序入口为_start使用objdump工具查看链接前后的地址分配情况:
说明一下参数,VMA代表虚拟地址,Size代表大小,我们只需要关注这两处即可。
这里使用的是32位的Linux系统,64位下可能情况有些不同,不过总的道理是一样的。
a.o: 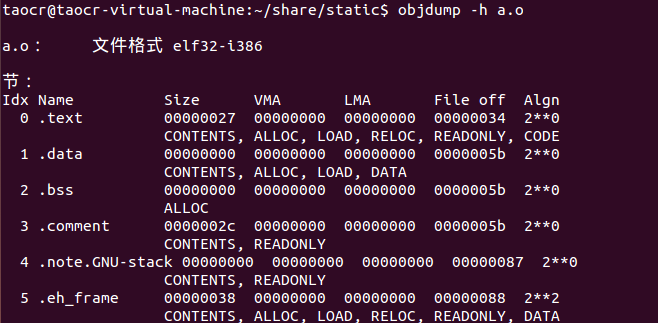
其中代码段大小为0x27字节,数据段大小为0字节,bss段也为0。
VMA为0是因为其是目标文件,虚拟空间还没有被分配,默认为0。
b.o: 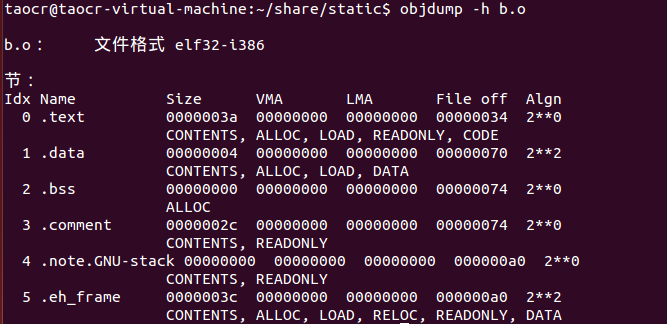
其中代码段大小为0x3a字节,数据段大小为0x04字节,数据段大小为0x04字节,bss段为0字节。
最后来看链接后的ELF文件ab: 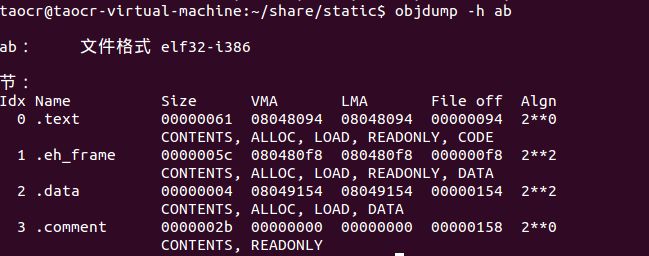
可以看到,代码段的大小为0x61字节,数据段为0x04字节,是a.o与b.o两个目标文件的代码段与数据段之和。
在此文件中也可以看到VMA有了实际的值,0x08048094是其在虚拟地址空间中的起始地址,其实在32位的Linux中ELF文件默认应从地址0x08048000开始分配,为什么这里是0x08048094我也不明白。。。
示意图: 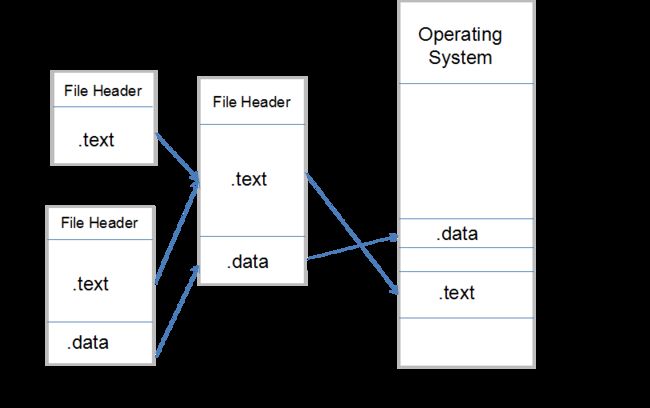
经过上面的步骤拆分,对于地址和空间的分配应该有一个直观的了解了,总结一下,其实就是将目标文件按相似段合并的策略合并后计算其每个段的长度、属性,进而对其进行地址分配。
2、符号解析与重定位
之前说过的两部链接法,前面说了空间与地址分配,现在解释什么叫做符号解析与重定位,这是静态链接的核心内容。
首先解释什么叫做重定位
链接时根据符号找寻相应模块中的地址,然后将地址全部修正,就是重定位。而修正的地方就称为重定位入口。
简单的来说,我们在编译a.c文件得到a.o文件时,所使用的shared变量以及swap函数,编译器对它们一无所知,不知道位置也不知道它们做了什么,编译器编译时假设它们在别的文件中,就先不管它们,在相应的地址位置上填充错误地址。那么在链接的过程中由于下一步要直接生成可执行文件,就不能再放任这些问题,也就是要找到它们定义的位置对错误地址进行修正,从而正确执行。
为了对这步进行理解,对a.o与ab可执行文件进行反汇编:
a.o: 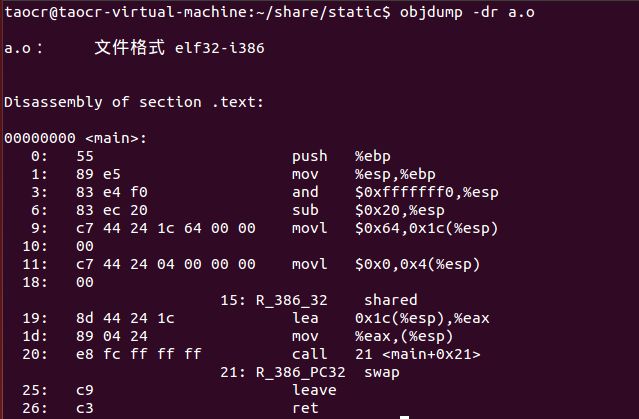
其中有两个重定位入口,就是标记15与21的地方,可以看到从15开始到下一步指令之间具体为0x00000000,表示shared变量的地址是0x00000000,很明显错误。而21开始的字节为0xfc ff ff ff,这里的0xfc ff ff ff是用小端方式保存的,读取出来的值应为0xff ff ff fc,表示值为-3,这里所记录的值应为call这条指令所跳转的目标地址与其下一条指令地址的偏移量,这里偏移-3即跳转地址为21,那么肯定错误。
ab: 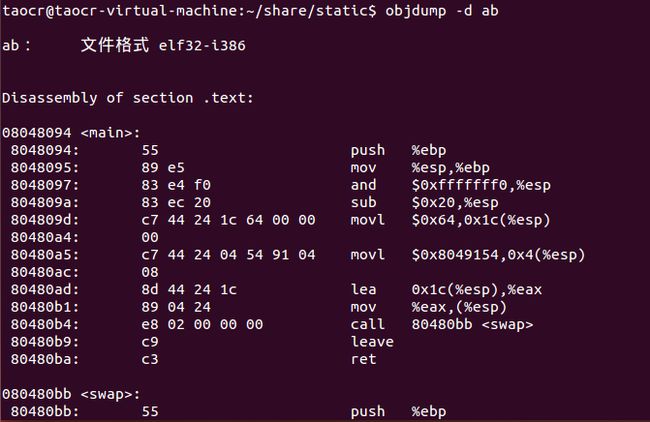
链接后的ab可执行文件中,可以看到原本标记的重定位入口处的地址都被修改,0x00000000改为0x08049154,根据前面我们对ab这个文件虚拟地址空间所画的示意图可以看出,位于数据段中。而另一个0xfc ff ff ff 改为了0x 02 00 00 00,按照刚才的小端方式来读即偏移量为2,即所跳转的地址与其下一步的指令地址的偏移量为2,可得出swap函数的起始地址为0x080480b9+0x00000002=0x080480bb,在图中可以看到正是swap的起始地址。
根据上面的过程对于重定位的概念应该已经了解了,其实就是在输入的目标文件中找寻需要重定位即地址错误的地方,将其地址进行修正。
那么链接器如何知道哪些地方需要被修正?答案是重定位表,这是在ELF文件中的一个结构,专门用来保存与重定位相关的信息。每一个需要被重定位的段都有着其重定位表,一个重定位表往往就是一个ELF文件中的段,那么就可能会有多个重定位段,举个例子:如果.text段与.data段都要重定位,那么就会存在.rel.text以及.rel.data两个段。
我们来看看重定位表,以对其有个直观的了解: 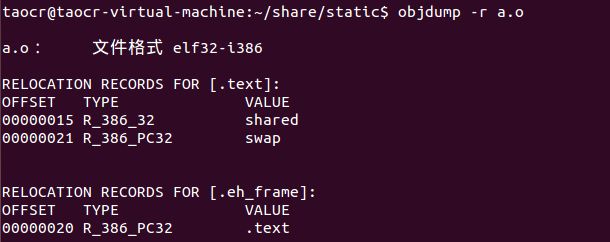
对于.eh_frame这段我们不讨论,这应该是辅助段。可以看到.text段的重定位表中有两个重定位入口shared与swap,链接器也正是根据重定位表来对a.o文件中的shared与swap进行标记并以此进行重定位的。
上面说了重定位,那么就剩下符号解析了
其实对于符号解析的过程一直都伴随着重定位的过程,我理解符号解析简单来说通过全局符号表要能得知一个符号它的属性、地址、大小、作用分别是什么,如果无法得知,那么无法进行符号解析。
其实重定位过程中,每一个重定位入口都是对一个符号的引用,链接器这个符号的引用进行重定位时,就要确定此符号的目标地址,就需要去查询全局符号表中相应的符号来获得目标地址,从而重定位
我们先来看看a.o的符号表: 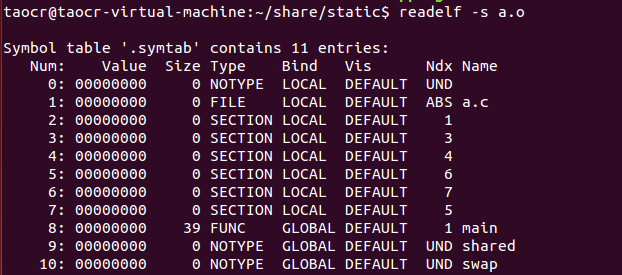
我们关注一下最下面的shared及swap符号,可以看到两个的Ndx项都是UND,这表示undefined即未定义类型,这种未定义的符号是因为此目标文件中有它们的重定位项。我们直接对a.o文件进行链接,看看结果: 
出现错误,shared和swap未定义,那么可以想象一下报错的整个过程:链接器扫描了所有的输入文件后,这些未定义的符号不能再全局符号表中找到,那么就会报未定义的错误。