前言
本系列全部基于 Spring 5.2.2.BUILD-SNAPSHOT 版本。因为 Spring 整个体系太过于庞大,所以只会进行关键部分的源码解析。
本篇文章主要介绍 Spring IoC 容器怎么加载 bean 的定义元信息。
下图是一个大致的流程图:
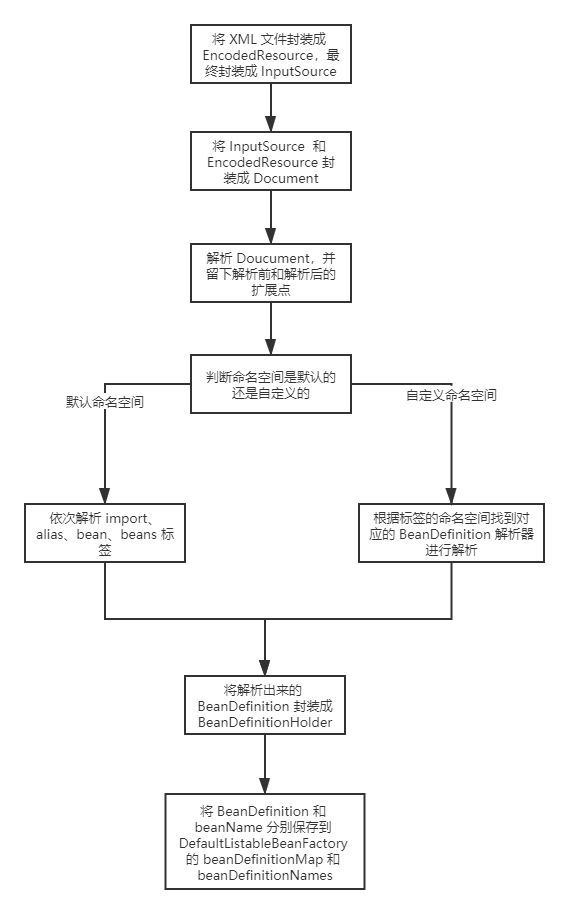
正文
首先定义两个简单的 POJO,如下:
public class User {
private Long id;
private String name;
private City city;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public City getCity() {
return city;
}
public void setCity(City city) {
this.city = city;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
", city=" + city +
'}';
}
}
public class City {
private Long id;
private String name;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "City{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
再编写一个 XML 文件。
最后再来一个测试类。
public class BeanDefinitionDemo {
public static void main(String[] args) {
DefaultListableBeanFactory beanFactory = new DefaultListableBeanFactory();
XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(beanFactory);
reader.loadBeanDefinitions("META-INF/bean-definition.xml");
User user = beanFactory.getBean("user", User.class);
System.err.println(user);
}
}
上面这段代码比较简单,无非就是声明 bean 工厂,然后通过指定的 XML 文件加载 bean 的定义元信息,最后通过 bean 工厂获取 bean。接下来介绍上面代码中的2个核心类 DefaultListableBeanFactory 和 XmlBeanDefinitionReader。
DefaultListableBeanFactory
下面是该类的类图及层次结构:
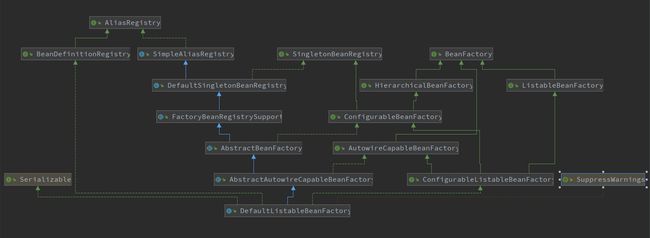
- AliasRegistry:定义对
alias的简单增删改等操作。 - SimpleAliasRegistry:主要使用
map作为alias的缓存,并对接口AliasRegistry进行实现。 - SingletonBeanRegistry:定义了对单例 bean 的注册及获取。
- BeanFactory:定义获取单个
bean及bean的各种属性。 - DefaultSingletonBeanRegistry:对接口
SingletonBeanRegistry各函数的实现。 - HierarchicalBeanFactory:继承
BeanFactory,也就是在BeanFactory定义的功能的基础上增加了对parentBeanFactory的支持。 - BeanDefinitionRegistry:定义了对
BeanDefinition的各种增删改操作。 - FactoryBeanRegistrySupport:在
DefaultSingletonBeanRegistry基础上增加了对FactoryBean的特殊处理功能。 - ConfigurableBeanFactory:提供配置
BeanFactory的各种方法。 - ListableBeanFactory:继承
BeanFactory提供了获取多个bean的各种方法。 - AbstractBeanFactory:综合
FactoryBeanRegistrySupport和ConfigurableBeanFactory的功能。 - AutowireCapableBeanFactory:提供创建
bean、自动注入、初始化以及应用bean的后处理器。 - AbstractAutowireCapableBeanFactory:综合
AbstractBeanFactory并对接口AutowireCapableBeanFactory进行实现。 - ConfigurableListableBeanFactory:
BeanFactory配置清单,指定忽略类型及接口等。 - DefaultListableBeanFactory:综合上面所有功能,主要是对
bean注册后的处理。
可以看到上面的接口大多数是定义了一些功能或在父接口上扩展了一些功能,DefaultListableBeanFactory 实现了所有接口,大多数默认情况下我们所使用的 beanFactory 就是 DefaultListableBeanFactory。
下面我们就开始分析 Spring 是如何解析 XML 文件,并读取其中的内容的。
AbstractBeanDefinitionReader#loadBeanDefinitions
public int loadBeanDefinitions(String location, @Nullable Set actualResources) throws BeanDefinitionStoreException {
// 获取resourceLoader,这边是PathMatchingResourcePatternResolver
ResourceLoader resourceLoader = getResourceLoader();
if (resourceLoader == null) {
throw new BeanDefinitionStoreException("Cannot load bean definitions from location [" + location + "]: no ResourceLoader available");
}
// 判断resourceLoader是否是ResourcePatternResolver,我们这边是符合的
if (resourceLoader instanceof ResourcePatternResolver) {
try {
// 根据路径获取所欲符合的配置文件并封装成Resource对象
Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);
// 根据Resource加载bean定义,并返回数量
int count = loadBeanDefinitions(resources);
if (actualResources != null) {
Collections.addAll(actualResources, resources);
}
return count;
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"Could not resolve bean definition resource pattern [" + location + "]", ex);
}
}
else {
// 只能通过绝对路径加载单个资源
Resource resource = resourceLoader.getResource(location);
// 根据Resource加载bean的定义,并返回数量
int count = loadBeanDefinitions(resource);
if (actualResources != null) {
actualResources.add(resource);
}
return count;
}
}
public int loadBeanDefinitions(Resource... resources) throws BeanDefinitionStoreException {
Assert.notNull(resources, "Resource array must not be null");
int count = 0;
for (Resource resource : resources) {
// 调用具体实现类的方法,加载 BeanDefinition,并返回数量,见下文详解
count += loadBeanDefinitions(resource);
}
return count;
}
上面方法主要是将资源文件转换为 Resource 对象,然后调用 loadBeanDefinitions(Resource...) 加载 BeanDefinition 。
XmlBeanDefinitionReader#loadBeanDefinitions
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
// 将Resource封装成EncodedResource,也就是对资源指定编码和字符集
return loadBeanDefinitions(new EncodedResource(resource));
}
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
// 当前正在加载的EncodedResource,第一次加载的话这里是空的
Set currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet<>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
// 如果当前encodedResource已经存在,代表出现了循环加载,抛出异常
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try {
// 获取Resource的输入流
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
// 将inputStream封装成org.xml.sax.InputSource
InputSource inputSource = new InputSource(inputStream);
// 如果encodedResource的编码不为空,设置inputSource的编码
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
// 加载bean定义(方法以do开头,真正处理的方法),见下文详解
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
// 关闭流
inputStream.close();
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
}
finally {
// 当前资源以及加载完毕,从currentResources中移除
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}
上面方法主要将 Resource 封装成 EncodedResource ,也就是制定资源的编码和字符集。然后获取 Resource 的输入流 InputStream ,并封装成 InputSource 设置其编码,最终调用 doLoadBeanDefinitions 开始真正的加载流程。
XmlBeanDefinitionReader#doLoadBeanDefinitions
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource) throws BeanDefinitionStoreException {
try {
// 根据 inputSource 和 resource 加载 XML 文件,并封装成 Document
Document doc = doLoadDocument(inputSource, resource);
// 用 doc 去解析和注册 bean definition,见下文详解
int count = registerBeanDefinitions(doc, resource);
return count;
}
// 省略异常处理
}
protected Document doLoadDocument(InputSource inputSource, Resource resource) throws Exception {
return this.documentLoader.loadDocument(inputSource, getEntityResolver(), this.errorHandler,getValidationModeForResource(resource), isNamespaceAware());
}
protected int getValidationModeForResource(Resource resource) {
// 如果手动指定了验证模式则使用指定的验证模式
int validationModeToUse = getValidationMode();
if (validationModeToUse != VALIDATION_AUTO) {
return validationModeToUse;
}
// 如果未指定则使用自动检测,其实就是判断文件是否包含 DOCTYPE
int detectedMode = detectValidationMode(resource);
if (detectedMode != VALIDATION_AUTO) {
return detectedMode;
}
// 如果没有找到验证,默认使用 XSD 模式,因为 DTD 已经不维护了
return VALIDATION_XSD;
}
// DefaultDocumentLoader.java
public Document loadDocument(InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception {
// 创建DocumentBuilderFactory
DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode, namespaceAware);
// 创建DocumentBuilder
DocumentBuilder builder = createDocumentBuilder(factory, entityResolver, errorHandler);
// 解析inputSource并返回Document对象
return builder.parse(inputSource);
}
detectValidationMode() 方法其实就是读取文件内容,判断是否包含 DOCTYPE,如果包含就是 DTD 否则就是 XSD。
获取 XML 配置文件的验证模式。XML 文件的验证模式是用来保证 XML 文件的正确性,常见的验证模式有 DTD 和 XSD。
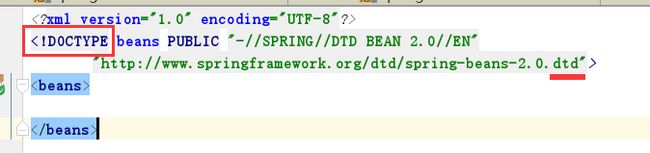
DTD XML 格式示例:
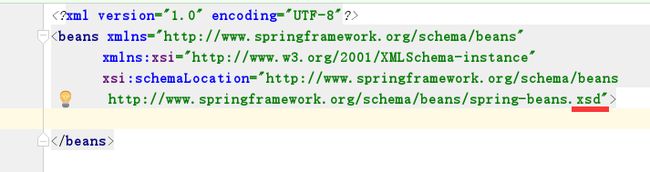
XSD XML 格式示例:
XmlBeanDefinitionReader#registerBeanDefinitions
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
// 获取DefaultBeanDefinitionDocumentReader
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
// 获取注册中心,再靠注册中心获取注册之前以及注册过的BeanDefinition数量
int countBefore = getRegistry().getBeanDefinitionCount();
// 解析并注册BeanDefinition,见下文详解
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
// 获取注册过后BeanDefinition数量减去注册之前的数量,得到的就是本次注册的数量
return getRegistry().getBeanDefinitionCount() - countBefore;
}
这里的 getRegistry() 方法返回的就是我们通过构造函数传入的 DefaultListableBeanFactory ,基本上这里都是 DefaultListableBeanFactory,因为就只有它实现了 BeanDefinitionRegistry 接口。
DefaultListableBeanFactory 中定义了存放 BeanDefinition 的缓存,如下:
public class DefaultListableBeanFactory extends AbstractAutowireCapableBeanFactory
implements ConfigurableListableBeanFactory, BeanDefinitionRegistry, Serializable {
// 存放BeanDefinition的缓存,key为 bean的名称,value就是其BeanDefinition
private final Map beanDefinitionMap = new ConcurrentHashMap<>(256);
}
所以 getBeanDefinitionCount() 方法返回的就是 beanDefinitionMap 中元素的数量。
DefaultBeanDefinitionDoucumentReader#registerBeanDefinitions
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
// 提取 root,注册 BeanDefinition (理论上 Spring 的配置文件,root 都应该是 beans 标签)
doRegisterBeanDefinitions(doc.getDocumentElement());
}
protected void doRegisterBeanDefinitions(Element root) {
BeanDefinitionParserDelegate parent = this.delegate;
// 专门处理解析
this.delegate = createDelegate(getReaderContext(), root, parent);
// 校验root节点的命名空间是否为默认的命名空间(默认命名空间http://www.springframework.org/schema/beans)
if (this.delegate.isDefaultNamespace(root)) {
// 处理 profile 属性
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
// 校验当前节点的 profile 是否符合当前环境定义的,如果不是则直接跳过,不解析该节点下的内容
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
return;
}
}
}
// 解析前处理,留给子类实现
preProcessXml(root);
// 解析注册 BeanDefinition,见下文详解
parseBeanDefinitions(root, this.delegate);
// 解析后处理,留给子类实现
postProcessXml(root);
this.delegate = parent;
}
profile 主要是用于多环境开发,例如:
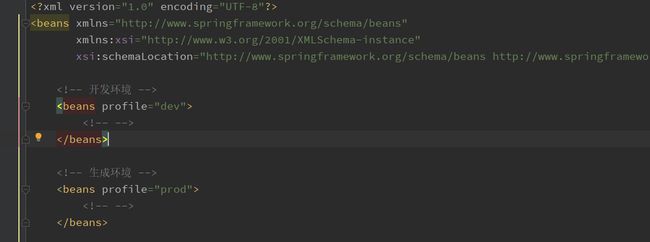
集成到 Web 环境时,在 web.xml 中加入以下代码:
Spring.profiles.active
dev
preProcessXml() 和 postProcessXml() 采用的 模板方法模式,子类可以DefaultBeanDefinitionDoucumentReader 来重写这两个方法,这也是解析前后的扩展点。
DefaultBeanDefinitionDoucumentReader#parseBeanDefinitions
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
// 校验root节点的命名空间是否为默认的命名空间,这里为什么再次效验,因为调用解析前调用了preProcessXml()方法,可能会对节点做修改
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
// 默认命名空间节点的处理,例如
delegate.parseCustomElement(ele);
}
}
}
}
else {
// 自定义命名空间节点的处理
delegate.parseCustomElement(root);
}
}
关于 默认命名空间节点 的处理 和 自定义命名空间节点 的处理,会在后续文章一一分析。
总结
本篇文章对 Spring 解析 XML 文件具体节点前的准备工作做了简要分析,但是对 Spring 的资源管理(Resource)没有做过多介绍,有兴趣的小伙伴可以自行去研究一下。
我模仿 Spring 写了一个精简版,代码会持续更新。地址:https://github.com/leisurexi/tiny-spring。
参考
-
《Spring 源码深度解析》—— 郝佳
-
https://blog.csdn.net/v123411739/article/details/86669952