1 机器学习入门——线性回归第三课
上一篇我们看到了线性回归在对多个属性建模时,能迅速给出模型预测,但很多时候效果并不太美好。毕竟方法太简单了,而且很多时候已有的属性很难拟合到一起形成比较靠谱的结果。
所有的数据下载地址:https://gitee.com/tianyalei/machine_learning,按对应章节查找。
再回过头来看看上个例子,创建一个能基于汽车的几个特性来推测其油耗(每加仑英里数,MPG)的回归模型(请务必记住,数据取自 1970 至 1982 年)。这个模型包括汽车的如下属性:汽缸、排量、马力、重量、加速度、年份、产地及制造商。此外,这个数据集有 398 行数据。
上一篇我们的误差率达到了30%,我们来分析一下怎么优化。
当属性数量不多时,我们首先考虑欠拟合的情况。欠拟合意思就是基于现有的这些属性,用他们来做线性回归,无论怎么调整参数,都很难达成较好的结果。原因就是属性不够,属性之间单独的一次方线性关系不足以拟合出好的模型。通过观察,我们可以假设,重量和气缸数量不能达成线性关系,但有可能和气缸的二次方更搭配。
只是假设而已,我们来验证一下。我们给样本加参数,怎么加呢?
我们知道(a+b)^2展开就是a^2+2ab+b^2。这样原本只有a、b两个属性,后来就变成了5个属性,多了3个。同理,我们可以选择给属性加次方。形成更多的属性,然后再来尝试线性回归。
我已经做好了程序,参照这篇,这个程序可以给任意属性增加任何次方的全组合,只支持csv文件。
我先把autoMpg.arff文件变成csv文件,里面可能有一些?值,就是空值,可以手工修补一下。然后用程序处理为所有属性的3次方,得到autoMpg-all.csv。然后我们从中抽取70%的数据作为训练集autoMpg-power.csv,剩下的作为测试集,用来测试训练的结果是否靠谱autoMpg-power-test.csv。
OK,一切就绪,导入autoMpg-power.csv。
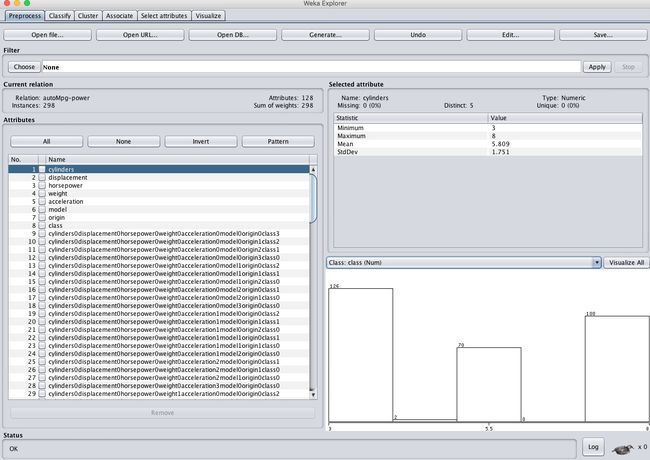
可以看到属性一下子变多了,现在有128个属性了。
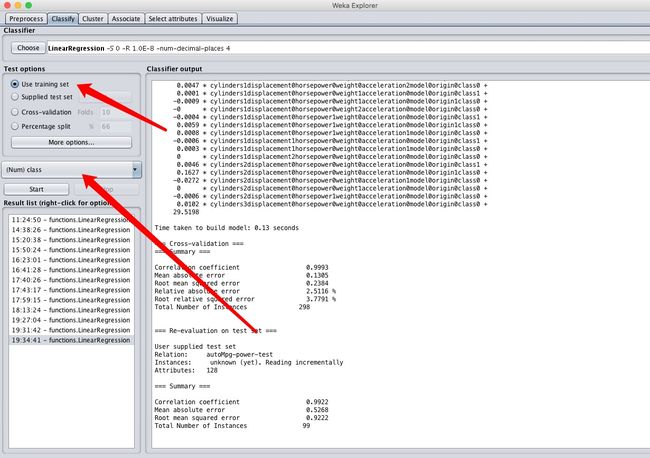
同样还是选择线性回归,主要箭头的位置,class不要选错了,这里要选择作为结果的属性。
点击start开始训练。
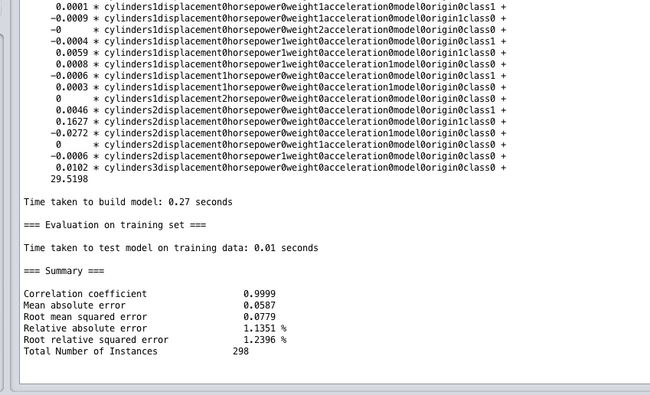
看一下结果,误差率只有1.1%,均方根误差只有0.05加仑,比上一篇的结果强完了!
作为对比,看看上一次的结果: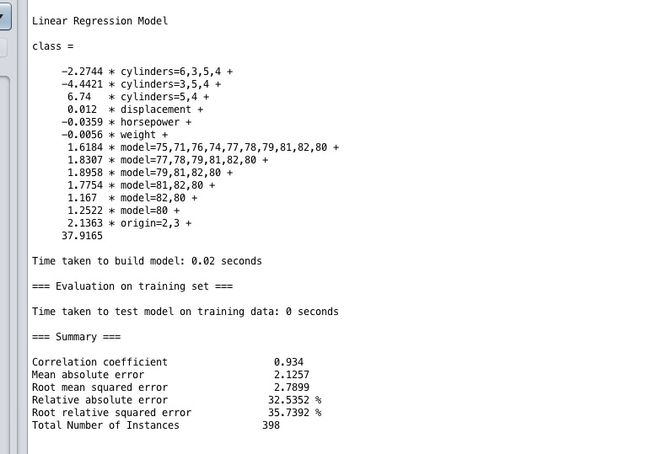
这差距真不是一点半点,当然我们还没完。我们还要拿剩下的30%测试数据来检测一下。
选择autoMpg-power-test.csv,然后注意class不要选错了
然后在刚才的模型上右键,选择
看一下测试集在模型上跑的结果。如果训练集的结果特别好,但是测试集特别差,说明我们出现了过拟合的情况,此时就需要减属性、降梯度等等手段了。
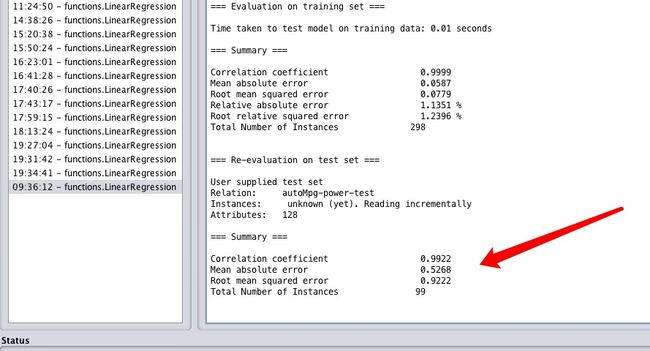
可以看到测试集在模型上的运行结果,效果仍旧比加属性前强了N倍,但是貌似相对误差0.5达到了训练集0.05的10倍了,虽然预测结果0.5加仑耗油量的偏差在实际生活中完全可以接受,但是还是出现了一些过拟合的情况。也就是训练集效果太好,测试集表现比训练集差。
后续我又尝试了2次方、4次方的情况,发现3次方的效果还是最好的。所以我们的优化到此为止了,在线性回归算法上,我们认识这个结果基本是最优。
实战
OK,下面就要把我们已经学会的应用到实战中了,在知名的UCI网站,有大量的测试数据集,都是实际产生的真实数据。
我们使用Wine Quality红酒质量测试,winequality-red.csv,导入到weka。我们先来目视一下这个数据集的特点。
导入测试,使用线性回归测试一下,得到结果
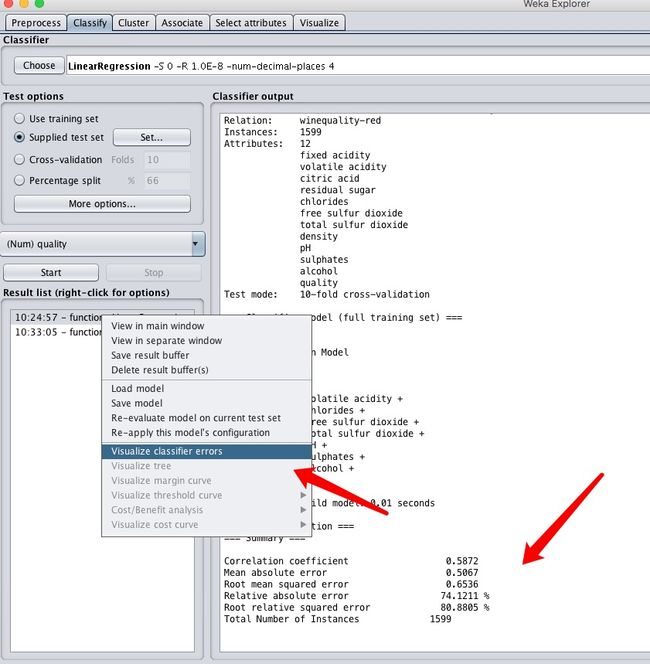
可以看到误差在74%,平均偏差在0.5,这个结果明显不是多么美好,我们来观察一下数据特点。Visualize classifier errors。
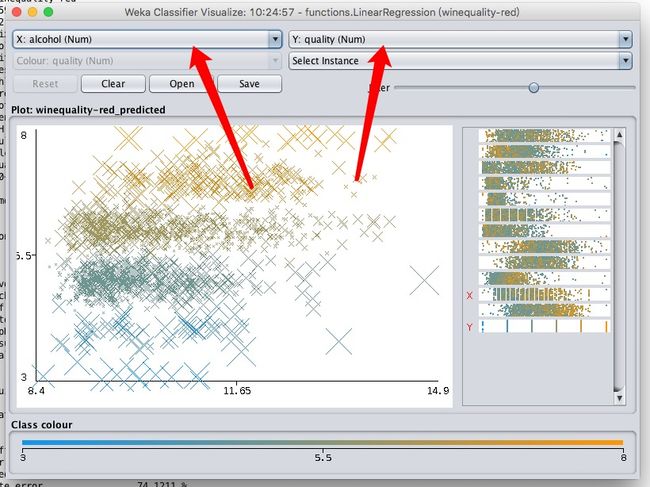
设置Y轴为最终的目标quality,x轴可以分别尝试其他的各个属性,来看看各个属性对最终质量产生的影响。
譬如alcohol酒精度,从图上可以大概分析出在8.4-12之间时,最终质量集中5-6.5之间,而且对质量的提升很缓慢,总体成正相关,但不明显。
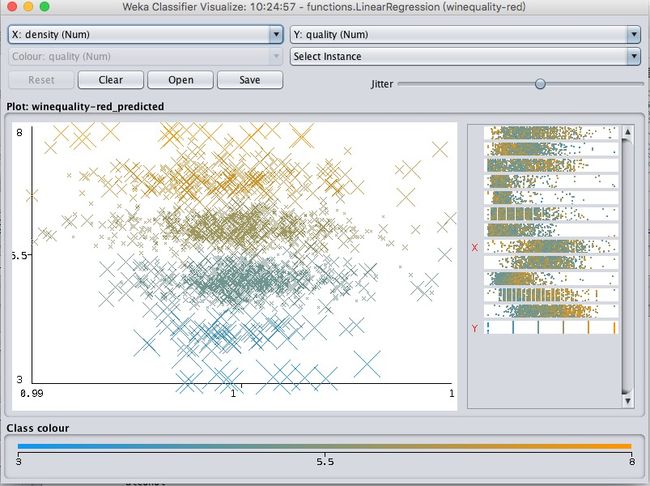
density密度,总体上呈负相关,但也不明显。
简单来看看图,其实可以明白,这几个属性对最终的值影响都不算太明显,不能看出明显的线性关系。所以最终的模型效果比较差,错误率很高。
所以就需要调整参数了。至于怎么做,我就不细说了,我直接上结果。
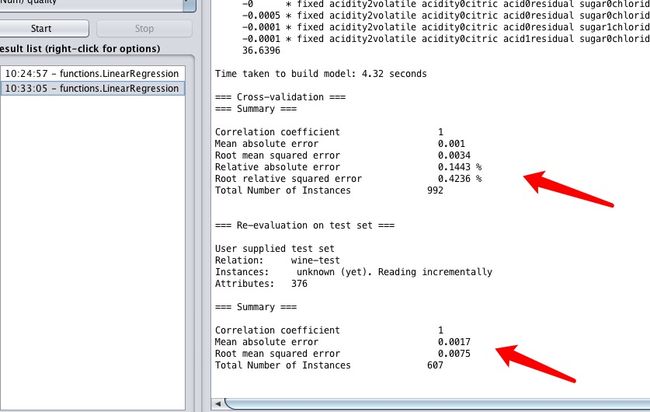
这是调整后的结果数据。上面是训练集,下面是测试集。可以看到无论是训练集还是测试集,都保持了非常优秀的表现。平均均方根误差只有0.001,百分比也很低。那么这个优化后的模型就完全可以实际应用了。效果很好。