Flume日志采集,avro采集,以及通过参数控制下沉到hdfs的文件大小,时间等控制
1 Flume日志收集
1.1 总体介绍
官方地址:http://flume.apache.org/
1.1.1 背景
flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用。Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera。但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.94.0 中,日志传输不稳定的现象尤为严重,为了解决这些问题,2011 年 10 月 22 号,cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(next generation);改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。
flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。
flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
1.1.2 特点
Flume的可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Besteffort(数据发送到接收方后,不会进行确认)
可恢复性
还是靠Channel.推荐使用FileChannel,事件持久化在本地文件系统里面(性能比较差)。
核心概念
Agent:使用JVM运行Flume。每台机器运行一个agent,但是可以再一个agent中包含多个sources和sinks。
Client: 生产数据,运行一个独立的线程。
Source: 从Client收集数据,运行一个独立线程。
Channel: 连接sources和sinks,这个有点像一个队列。
Events: 可以是日志记录、avro对象等。
Flume以agent为最小的独立运行单位。一个agent就是一个JVM。单agent由Source、Sink和Channel三大组件构成,如下图:
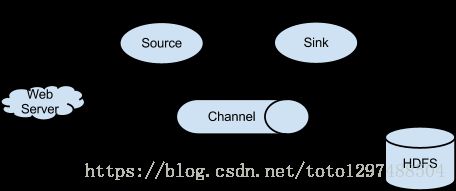
值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source,Channel和sink可以自由组合。组合方式基于用于设置的配置文件,非常灵活。比如:Channel可以把时间暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS,HBase,甚至是另外一个Source等等。Flume支持用户建立多级流,也就是说,多个agent可以协同工作,并且支持Fan-in、Fan-out、Contextual Routing、Backup Routes。如下图所示:

1.1.3 采集形式
日志收集中一个非常常见的场景是大量的日志生成客户端将数据发送给附加到存储子系统的一些消费者代理。例如,从数百个web服务器中收集的日志,发送给数十个写入HDFS集群的代理。

在离线阶段,Flume的日志收集,Agent1/Agent2/Agent3端也是Flume端,主要的作用是采集nginx日志,采集到的日志文件最后下沉到另外一个agent4,最终通过agent4将数据下沉到hdfs中。
1.2 Agent1/Agent2/Agent3 Flume采集端配置
1.2.1 前期准备
运行Flume-1.8.0的时候,需要JDK,否则会报错。修改jdk位置:
[root@bigdata1 conf]# cd /home/bigdata/installed/flume-1.8.0/conf
[root@bigdata1 conf]# vim flume-env.sh
export JAVA_HOME=/home/bigdata/installed/jdk1.8.0_731.2.2 配置Flume内存参数
[root@bigdata1 flume-1.8.0]# cd /home/bigdata/installed/flume-1.8.0/conf
[root@bigdata1 flume-1.8.0]# vim flume-env.sh
修改flume-1.8.0/bin/flume-ng,主要修改JAVA_OPTS这个参数的值,具体的值是:
JAVA_OPTS="-Xmx256m"内容是:

1.2.3 创建文件夹
进入线上服务器flume所在位置。
[root@bigdata1 flume-1.8.0]# cd /xxxxx/apache-flume-1.8.0-bin
[root@bigdata1 flume-1.8.0]# ll
总用量 6296
drwxrwxrwx 2 bigdata bigdata 62 3月 22 10:46 bin
-rwxrwxrwx 1 bigdata bigdata 81264 9月 15 2017 CHANGELOG
drwxrwxrwx 2 bigdata bigdata 286 6月 5 21:10 conf
-rwxrwxrwx 1 bigdata bigdata 5681 9月 15 2017 DEVNOTES
-rwxrwxrwx 1 bigdata bigdata 2873 9月 15 2017 doap_Flume.rdf
drwxrwxrwx 10 bigdata bigdata 4096 9月 15 2017 docs
drwxr-xr-x 3 root root 123 6月 11 15:51 fileCHK
drwxr-xr-x 2 root root 170 6月 11 16:50 fileData
drwxrwxrwx 2 bigdata bigdata 8192 3月 22 10:46 lib
-rwxrwxrwx 1 bigdata bigdata 27663 9月 15 2017 LICENSE
drwxr-xr-x 2 root root 23 5月 15 14:47 logs
-rw------- 1 root root 4054498 6月 11 16:50 nohup.out
-rwxrwxrwx 1 bigdata bigdata 249 9月 15 2017 NOTICE
-rwxrwxrwx 1 bigdata bigdata 2483 9月 15 2017 README.md
-rwxrwxrwx 1 bigdata bigdata 1588 9月 15 2017 RELEASE-NOTES
drwxrwxrwx 2 bigdata bigdata 68 3月 22 10:46 tools
-rw-r--r-- 1 root root 1242266 6月 11 16:20 zookeeper.out
[root@bigdata1 flume-1.8.0]#要注意的是,上面的fileCHK,fileData为自己手动创建的,创建命令:
[root@bigdata1 flume-1.8.0]# cd /xxxxx/apache-flume-1.8.0-bin
[root@bigdata1 flume-1.8.0]# mkdir fileCHK
[root@bigdata1 flume-1.8.0]# mkdir fileData1.2.4 查看/杀死Flume进程的方式
查看Flume的方式:
[root@bigdata1 flume-1.8.0]# grep flume | grep -v grep杀死Flume的方式:
[root@bigdata1 flume-1.8.0]# kill -9 `ps -ef | grep flume | grep -v grep | awk '{print $2}'`1.2.5 Conf文件配置
进入conf文件夹,创建采集日志的配置文件
[xxx@xxx]# vim file-collect-logs.conf内容是:
#定义agent各个组件的名称
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#描述source端
a1.sources.r1.type=exec
#要注意的是,这里使用的是-F,只有这样才能保证nginx日志文件变化之后,不会出错
a1.sources.r1.command=tail -n +0 -F /var/log/nginx/tomcat_access.log
a1.sources.r1.channels=c1
#a1.sources.r1.restart=true
#a1.sources.r1.restartThrottle=5000
a1.sources.r1.threads=100
#Describe the sink
##type设置成avro来设置发消息
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
##下沉到bigdata1这台机器
a1.sinks.k1.hostname = xxx.xxx.xxx.xxx
##下沉到bigdata1中的4141
a1.sinks.k1.port = 4141 (此处和线上配置不一致)
a1.sinks.k1.batch-size = 10000
#使用File通道
a1.channels.c1.type=file
a1.channels.c1.checkpointDir=/usr/local/work/apache-flume-1.8.0-bin/fileCHK
a1.channels.c1.dataDirs=/usr/local/work/apache-flume-1.8.0-bin/fileData
a1.channels.c1.keep-alive=601.2.6 Flume启动
采集端配置好之后,等待接收端Flume启动后,启动采集端Flume,启动方式是:
[x@xxx apache-flume-1.8.0-bin] cd /xxx/apache-flume-1.8.0-bin
[x@xxx apache-flume-1.8.0-bin] nohup bin/flume-ng agent -c conf -f conf/file-collect-logs.conf -n a1 -Dflume.root.logger=INFO,console &其中杀死进程的方式:
kill -9 `ps -ef | grep flume | grep -v grep | awk '{print $2}'`要注意的是:
在Flume修改配置之后是不需要重启Flume的。直接保存配置文件即可让配置启用。
1.3 Agent4 avro接收端Flume参数配置
1.3.1 前期准备
运行Flume-1.8.0的时候,需要JDK,否则会报错。修改jdk位置:
[root@bigdata1 conf]# cd /home/bigdata/installed/flume-1.8.0/conf
[root@bigdata1 conf]# vim flume-env.sh
export JAVA_HOME=/home/bigdata/installed/jdk1.8.0_731.3.2 配置Flume内存参数
参考1.2.1
1.3.3 创建文件夹
进入Flume所在位置,创建fileCHK 和 fileData
[root@bigdata1 flume-1.8.0]# cd /xxxx/installed/flume-1.8.0
[root@bigdata1 flume-1.8.0]# ll
总用量 6360
drwxrwxrwx 2 bigdata bigdata 62 3月 22 10:46 bin
-rwxrwxrwx 1 bigdata bigdata 81264 9月 15 2017 CHANGELOG
drwxrwxrwx 2 bigdata bigdata 286 6月 5 21:10 conf
-rwxrwxrwx 1 bigdata bigdata 5681 9月 15 2017 DEVNOTES
-rwxrwxrwx 1 bigdata bigdata 2873 9月 15 2017 doap_Flume.rdf
drwxrwxrwx 10 bigdata bigdata 4096 9月 15 2017 docs
drwxr-xr-x 3 root root 123 6月 11 15:51 fileCHK
drwxr-xr-x 2 root root 170 6月 11 17:18 fileData
drwxrwxrwx 2 bigdata bigdata 8192 3月 22 10:46 lib
-rwxrwxrwx 1 bigdata bigdata 27663 9月 15 2017 LICENSE
drwxr-xr-x 2 root root 23 5月 15 14:47 logs
-rw------- 1 root root 4121563 6月 11 17:18 nohup.out
-rwxrwxrwx 1 bigdata bigdata 249 9月 15 2017 NOTICE
-rwxrwxrwx 1 bigdata bigdata 2483 9月 15 2017 README.md
-rwxrwxrwx 1 bigdata bigdata 1588 9月 15 2017 RELEASE-NOTES
drwxrwxrwx 2 bigdata bigdata 68 3月 22 10:46 tools
-rw-r--r-- 1 root root 1242266 6月 11 16:20 zookeeper.out
[root@bigdata1 flume-1.8.0]#
创建fileCHK 和 fileData
[root@bigdata1 flume-1.8.0]# cd /xxxxx/apache-flume-1.8.0-bin
[root@bigdata1 flume-1.8.0]# mkdir fileCHK
[root@bigdata1 flume-1.8.0]# mkdir fileData1.3.4 查看/杀死Flume进程的方式
参看1.2.4
1.3.5 编写Flume sink—>hdfs的配置文件
[root@bigdata1 conf]# cd /home/bigdata/installed/flume-1.8.0/conf
[root@bigdata1 conf]# vim avro-collect-logger.conf具体内容如下:
#定义agent中的各各组件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
##描述和配置source端
##source中的avro组件是一个接收者服务
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
#这里的bigdata1是机器hostname,可以写成ip地址。外界调用的时候,可以使用这个ip和下面的端口号port联合调用
a1.sources.r1.bind = bigdata1
a1.sources.r1.port = 4141
a1.sources.r1.threads = 100
# Describe the sink
## 表示下沉到hdfs,类型决定了下面的参数
a1.sinks.k1.type = hdfs
## hdfs目录路径
a1.sinks.k1.hdfs.path = /nginx/%y-%m-%d
##写入hdfs的文件名前缀,可以使用flume提供的日期及%{host}表达式
a1.sinks.k1.hdfs.filePrefix = events-
## 表示到了需要触发的时间时,是否要更新文件夹,true:表示要
a1.sinks.k1.hdfs.round = true
#多久时间后close hdfs文件。单位是秒,默认30秒。设置为0的话表示不根据时间close hdfs文件
#配置下面的参数,表示40分钟滚动一次
a1.sinks.k1.hdfs.rollInterval = 3600
## 表示每隔value分钟改变一次(在0~24之间)
#a1.sinks.k1.hdfs.roundValue = 0
## 切换文件的时候的时间单位是分钟
#a1.sinks.k1.hdfs.roundUnit = minute
## 文件大小超过一定值后,close文件。默认值1024,单位是字节。设置为0的话表示不基于文件大小,134217728表示128m
## 0表示不按照文件大小进行滚动。
a1.sinks.k1.hdfs.rollSize = 0
## 写入了多少个事件后close文件。默认值是10个。设置为0的话表示不基于事件个数
a1.sinks.k1.hdfs.rollCount = 0
## 批次数,HDFS Sink每次从Channel中拿的事件个数。默认值100
a1.sinks.k1.hdfs.batchSize = 100000
## 使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream:为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
#HDFS操作允许的时间,比如hdfs文件的open,write,flush,close操作。单位是毫秒,默认值是10000,一小时为:3600000,这里稍微设置的大写
a1.sinks.k1.hdfs.callTimeout = 7200000
a1.sinks.k1.hdfs.writeFormat = Text
#配置这个参数之后,不会因为文件所在块的复制而滚动文件了,只会根据你的配置项来滚动文件了。
#设置这个参数之后,上面的rollInterval、rollSize、rollCount等才会起作用。
#hdfs.minBlockReplicas是为了让flume感知不到hdfs的块复制,这样滚动配置才不会受影响。
#假如hdfs的副本为3.那么配置的滚动时间为10秒,那么在第二秒的时候,flume检测到hdfs在复制块,那么这时候flume就会滚动
#这样导致flume的滚动方式受到影响。所以配置flume hdfs.minBlockReplicas配置为1,就检测不到副本的复制了。但是hdfs的副本还是3
a1.sinks.k1.hdfs.minBlockReplicas=1
#描述channel,适用场景是要求并发高,并且机器内存足够,丢失数据不会很影响总体结果的场景。但是重启和宕机,数据会丢失。
#配置不好的时候,会出现内存等的问题。
#a1.channels.c1.type=memory
#a1.channels.c1.capacity=10000
#a1.channels.c1.transactionCapacity=10000
#a1.channels.c1.byteCapacityBufferPercentage = 20
#a1.channels.c1.byteCapacity = 800000
#a1.channels.c1.keep-alive = 60
#适用场景,并发要求不高,要求硬盘足够即可,数据最后存在file中的,机器重启ls
或flume重启,只要调整参数,可以保证数据不丢失。
a1.channels.c1.type=file
a1.channels.c1.checkpointDir=/home/bigdata/installed/flume-1.8.0/fileCHK
a1.channels.c1.dataDirs=/home/bigdata/installed/flume-1.8.0/fileData
a1.channels.c1.keep-alive=60
a1.channels.c1.capacity=10000000
a1.channels.c1.transactionCapacity=10000000
#绑定source和sink到channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c11.3.6 Flume启动
[root@bigdata1 flume-1.8.0]# cd /home/bigdata/installed/flume-1.8.0
[root@bigdata1 flume-1.8.0]# nohup bin/flume-ng agent -c conf -f conf/avro-collect-logger.conf -n a1 -Dflume.root.logger=INFO,console &1.3.7 查看未关闭的块
hadoop fsck -openforwrite | more 查看未关闭块1.3.8 查看运行日志
可以通过查看nohup.out的方式查看运行日志。