facebook开源语音识别框架wav2letter++环境搭建
首先说明,本人只擅长在windows下开发。这次是因为公司需要做语音识别,采用wav2letter开源框架,所以在linux下搞一搞,如果有不对的地方还请指正。
先说下电脑配置: OS: Ubuntu16.04 GPU:Nvidia GTX 1060 5GB CPU : intel i7
os:ubuntu18.04 GTX1080Ti 安装先看下一篇中的注意事项
https://mp.csdn.net/postedit/89088082
facebook号称wav2letter是目前最快的语音识别系统,我没研究过别的语音识别,不知道它的快慢是什么程度,到后面我会把训练时间和识别速度贴出来。
我是运行的CUDA版本wav2letter,要运行CPU和opencv版本的同学请绕过。
按照作者介绍需要安装一下工具:
arrayfire,flashlight,libsndlife,MKL,KenLM,gflags,glog,CUDA,cudnn等
我这里把我的安装顺序说一下,因为我电脑里以前是做图像识别时配置的环境,在此基础上,安装作者的说明开始安装,结果在安装编译完wav2letter,准备训练的时候,总是提示,找不到或打不开flac文件(语音训练数据包)。安装了好几遍,还是这个问题,一怒之下,重装系统。所以我的环境是从干净的ubuntu系统开始安装。
一、安装ubuntu系统以及安装Nvidia驱动,CUDA,CUDNN参考我前面的那篇文章https://blog.csdn.net/tudou880306/article/details/81076000.
需要注意的时,作者要求CUDA>=9.2,作者推荐在CUDA9.2上安装。这个会影响到arrayfire的安装.
二、其它软件包安装
我是倒着安装的,什么意思?就是先下载wav2letter源码下来,然后cmake.. 配置环境,看看缺什么装什么。当然刚开始缺的是cmake,git,等常用的,不做介绍。
1.下载完源码后,首先安装下面的安装包,虽然作者提示在安装完arrayfire,flashlight,lisndfile,kenlm再apt下面的,但都一样,这样先安装完,对后面的libsndfile等库的编译,很方便了。
2.接下来,就按照下面的执行,当然cmke 会报很多错。大概会先提示找不到MKL(Intel's Math Kernel Library)
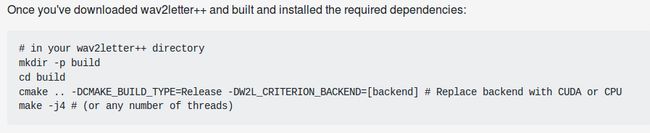
MKL的安装比较简单,去官网下载,注册个邮箱啥的,这里推荐不要下最新的,我这里下的是2018.update4(l_mkl_2018.4.274.tgz). 直接运行install_GUI.sh 界面安装就可以,安装完后添加环境变量,网上有很多,我就直接截图了。如果没有添加环境变量,在配置wav2letter时会找不到MKL,也可以在终端直接运行
export MKLROOT=/opt/intel/mkl # or path to MKL
3.接下来再次cmake . . 一下,会提示找不到flashlight,但是flashlight的安装要依赖arrayfire,所以要先安装arrayfire,这里安装的版本要注意,最新版本的arrayfire要求CUDA>=10.0了,我们的是9.2。所以推荐安装arrayfire3.6.1,也只能安装这个版本,因为flashlight要求arrayfire的版本>=3.6.1。安装arrayfire的时候,我建议从源码编译安装 ,不要用official binary installer,下载3.6.1源码 git clone -b v3.6.1 --recursive https://github.com/arrayfire/arrayfire.git
安装的时候最好把CPU 版本需要的插件装上,,因为后面编译wav2letter的时候需要,我也不知道为什么CUDA版本的wav2letter会用到。运行下面的命令就行。
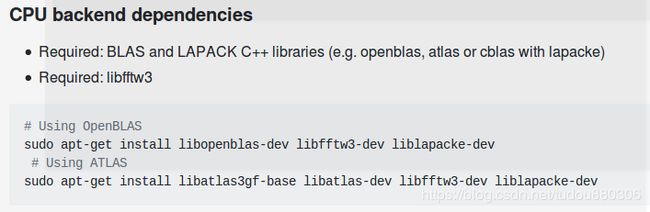
编译命令安装官网命令执行
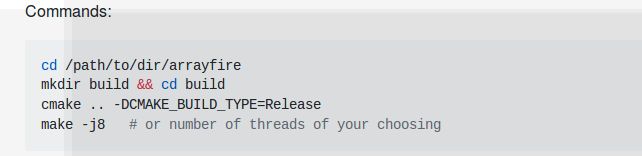
默认安装路径就行,编译完记得make install,然后make test 确保测试用例都通过,当然有些CPU和OPENCV的可以忽略。
4.接下来安装flashlight。参考官方文档就好https://fl.readthedocs.io/en/latest/installation.html
注意要安装nccl,看清自己的版本号,从官网下载nccl-repo-ubuntu1604-2.4.2-ga-cuda9.2_1-1_amd64.deb
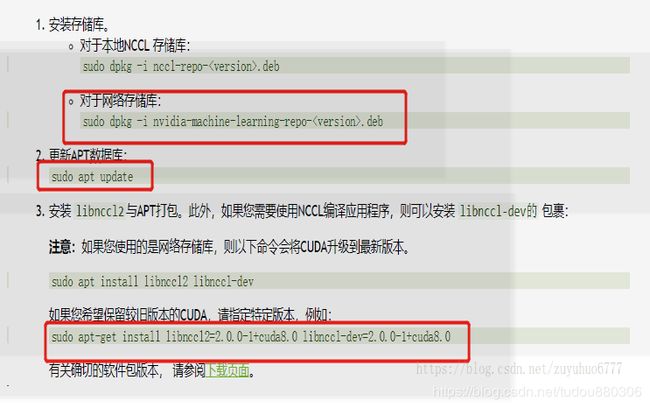
命令中的版本号要注意,尤其是第三条命令,我们应该是sudo apt-get install libnccl2=2.4.2-1+cuda9.2 libnccl-dev=2.4.2-1+cuda9.2
5.安装libsndfile,这个我前面就一直装不好,因为wav2letter的作者要求libsndfile支持flac,ogg,等,我编译libsndfile的时候也编译了,就是运行的时候,读取flac文件老出错。还是建议从源码安装,下载最新代码,不习惯的也可以自动安装。先介绍从源码安装。不管是哪种安装方式,下面的requirements和 recommended packages都需要安装,

缺什么装什么,应该只缺opus,因为这个是作者新加的,这个必须装才能和flac,ogg,vorbis一起编译。
从官网上下载opus,http://www.opus-codec.org/downloads/ 我下载的是1.3版本的,之后编译安装 ./configure && make && make install
然后应该就可以配置libsndfile了,一定注意看终端输出信息,会输出哪些enable,哪些disable, 其中的ENABLE_EXTERNAL_LIBS一定是enable,BUILD_SHARED_LIBS我不确定是否有必要enable了,默认好像是off,我自己是设置的on,cmake .. 后一定注意看最后一句输出,大意是如果要作为其它程序的依赖包,则需要在PKG_CONFIG_PATH中设置环境变量,我之前没注意,不知道是不是这个原因,wav2letter总是读取不到flac文件。在环境变量中export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig:$PKG_CONFIG_PTH 注意我这里都是默认安装路径。pkgconfig文件夹下应该有sndfile.pc文件才对。然后编译安装,安装下面的包


安装完后记得make test 或make check 查看是否所有测试都通过。
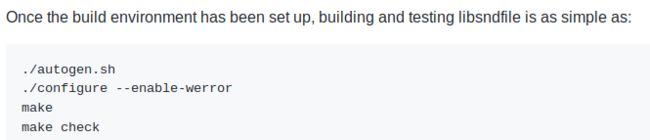
如果是自动安装,尤其是需要注意提前安装好recommended packages 和opus,然后执行下面命令
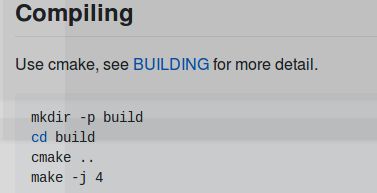
6.最后应该只剩kenlm了,这个也比较简单从官网下载源码https://github.com/kpu/kenlm
按照作者说明编译安装
7.最后再cmke .. wav2letter ,看看是否环境都配置正确,经常会提示找不到arrayfire,根据终端输出信息,在cmake时加上-DArrayFireDIR=/opt/arrayfire. 如果找不到MKL,或者kenlm则

最后应该能顺利编译通过。接下来按照作者说明下载训练数据,转换数据格式,开始训练。这些应该没啥问题
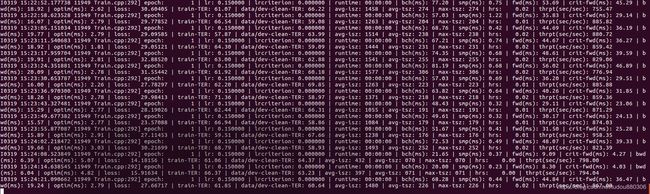
但是我以前没弄过语音识别,我只搞图像识别,所以不清楚训练快慢,图像识别,在我电脑上调惨到GPU满载,训练迭代10w次需要两周。语音这个作者说需要训练10个epoch,理想结果是40个epoch。我这训练了五个小时了,还没结束一个epoch,也不知道结果行不行,一会儿先拿模型decode下试试。后续再更新