吴恩达 deeplearning.ai 课程《改善深层神经网络:超参数调试、正则化以及优化》____学习笔记(第一周)
____tz_zs学习笔记
第一周 深度学习的实用层面(Practical aspects of Deep Learning)
我们将学习如何有效运作神经网络(超参数调优、如何构建数据以及如何确保优化算法快速运行)
设置ML应用(Setting up your ML application)
1.1 训练 / 开发 / 测试集(Train / Dev / Test sets)
老师语:在我看来,从一个领域或者应用领域得来的直觉经验,通常无法转移到其它应用领域。最佳决策取决于数据量、参数设置、硬件配置等诸多因素。对于很多应用系统,即使是经验丰富的深度学习行家也不太可能一开始就预设出最匹配的超参数。

应用深度学习是一个典型的迭代过程,需要多次循环往复,才能为你的应用找到合适的神经网络。
循环过程的效率是项目进展速度的一个关键因素。而创建高质量的训练数据集、验证集和测试集,能帮助提高循环效率。

经验法则:1、要确保验证集和测试集的数据来自同一分布。2、如果不需要无偏评估,没有测试集(只有训练集、验证集)也是可以。

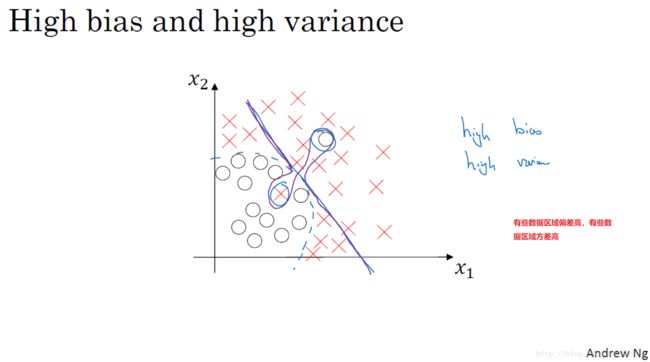
1.2 偏差 / 方差(Bias / Variance)
最优误差(也被称为贝叶斯误差)很小的情况下:
通过查看训练集误差,我们可以判断数据拟合情况,可以判断是否有偏差问题。然后查看验证集错误率有多高,我们可以判断方差是否过高。

·

·
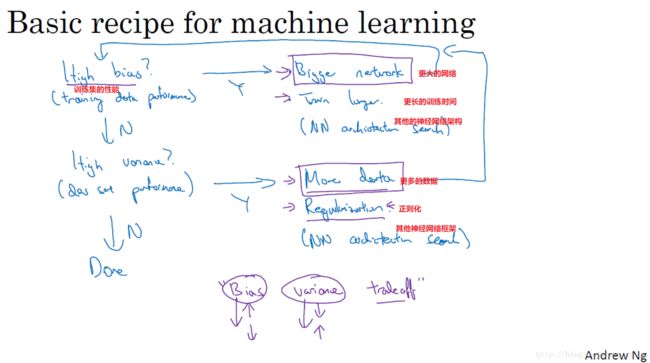
1.3 机器学习基础(Basic Recipe for Machine Learning)
训练神经网络时常用的基本方法
神经网络的正则化(Regularization your neural network)
1.4 正则化(Regularization)
减少过拟合(高方差)问题的方法:
1、准备更多的数据(但是,有时候没那么多数据或者获取更多的数据的成本很高)
2、正则化
我们先从简单的开始,下图为logistic回归中加入正则化。

神经网络中实现正则化

1.5 为什么正则化可以减少过拟合?(Why regularization reduces overfitting?)
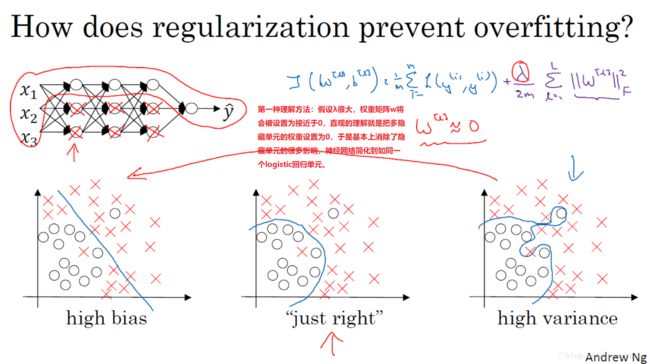
·
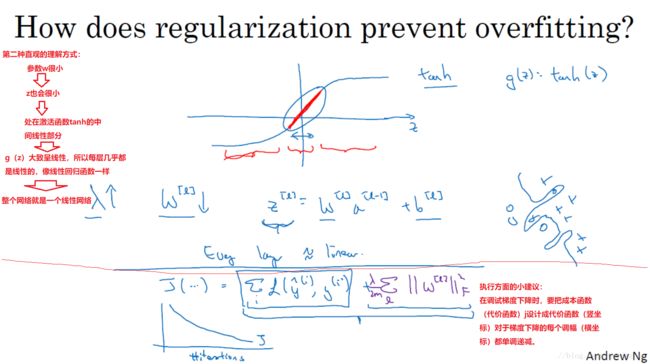
1.6 Dropout 正则化(Dropout Regularization)
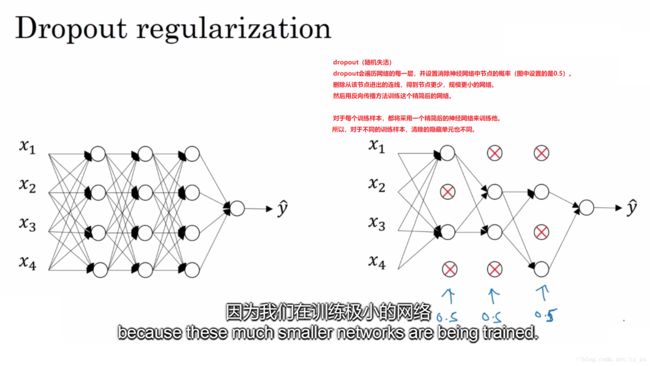
·

·

1.7 理解 Dropout(Understanding Dropout)
理解角度一:每次迭代中,使用的是一个较小的神经网络(因为随机归零了很多节点),而较小的神经网络是有正则化效果的。
理解角度二:节点不能依赖任何一个特征,因为每个特征都有可能被随机清除了,所以不会给其中一个很重的权重,而是倾向于每个都给一点点,这样,dropout就产生了收缩“权重的平方范数”的效果。与L2正则化类似,实施dropout的结果是它会压缩权重。dropout被正式地作为一种正则化的替代形式,与L2正则化不同的是,被应用的方式不同 dropout也会有所不同,甚至更适用于不同的输入范围。
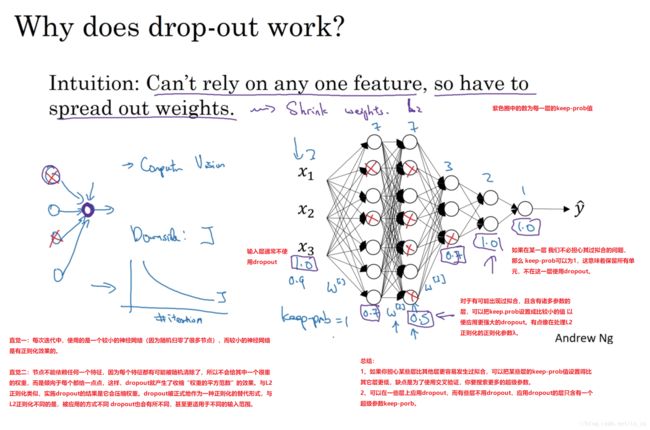
总结:
1、如果你担心某些层比其他层更容易发生过拟合,可以把某些层的keep-prob值设置得比其它层更低,缺点是为了使用交叉验证,你要搜索更多的超级参数。
2、可以在一些层上应用dropout,而有些层不用dropout,应用dropout的层只含有一个超级参数keep-porb。
提醒:
计算视觉中的输入量非常大,输入了太多的像素,以至于没有足够的训练数据,从而一直存在过拟合,所以dropout在计算机视觉中应用得比较频繁。有些计算机视觉研究人员非常喜欢用它,几乎成了默认的选择,但是要牢记一点:dropout是一种正则化方法,除非过拟合,否则不要使用。所以它在其它领域应用得比较少。
dropout一大缺点就是代价函数J不再被明确定义,因为每次迭代都会随机移除一些节点。老师的方法:我通常会关闭dropout函数,将keep.prop的值设为1,运行代码,确保J函数单调递减,然后再打开dropout函数。
1.8 其他正则化方法(Other regularization methods)
data augmentation(数据扩增)

early stopping(提早停止训练神经网络)
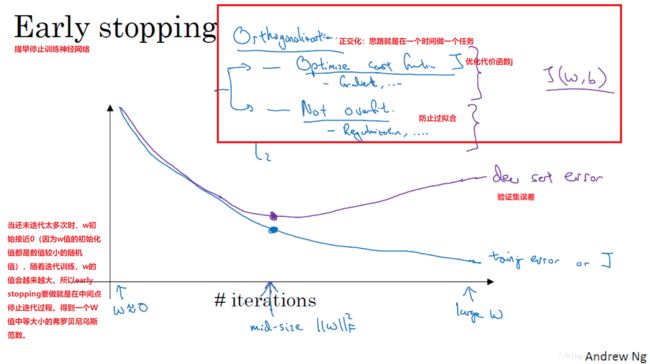
L2正则化和early stopping的对比
early stopping与L2正则化相似,都是选择参数W范数较小的神经网络来防止过拟合。
early stopping的优点是:只运行一次坡度下降,你可以找出W的较小值、中间值和较大值,而无需像L2正则化那样尝试超级参数λ的很多值。缺点是:你不能独立地处理优化代价函数j和防止过拟合这两个问题。因为提早停止梯度下降,也就是停止了优化代价函数J(这时有可能j还不是最优),同时停止了过拟合进程,你没有采用多钟方法分别处理两个问题,而是用一种方法同时解决两个问题。这样导致要考虑的东西变的更复杂了。
L2正则化缺点是:你必须尝试很多正则化参数λ的值(这也导致搜索大量λ值的计算代价太高)训练神经网络的时间可能很长。
虽然L2正则化有缺点,我个人更倾向于使用L2正则化,尝试许多不同的λ值,假如你可以负担大量计算的代价。使用early stopping也能得到相似结果,而且不用尝试这么多λ值。
优化问题(setting up your optimization problem)
1.9 归一化输入(Normalizing inputs)
训练神经网络其中一个加速训练的方法就是(normalizing inputs)归一化输入。

确保所有特征都在相似范围内,通常可以帮助学习算法运行得更快,而且执行这类归一化并不会产生什么危害。

1.10 梯度消失与梯度爆炸(Vanishing / Exploding gradients)
训练神经网络,尤其是训练深度神经网络,所面临的一个问题是梯度消失或梯度爆炸。也就是说,当你训练深度网络时,导数或坡度有时会变得非常大,或非常小,甚至以指数方式变小。
本节课介绍深度神经网络如何产生的梯度消失和梯度爆炸问题。

1.11 神经网络的权重初始化(Weight Initialization for Deep Networks)
针对梯度消失和梯度爆炸问题的一个不完整的解决方案(虽然不能彻底解决问题,但它确实降低了坡度消失和爆炸问题):谨慎地选择随机初始化参数,为权重矩阵初始化合理的值,使他既不会增长过快,也不会太快下降到0,从而得到权重或梯度不会增长或消失过快的深度网络。

1.12 梯度的数值逼近(Numerical approximation of gradients)
双边误差公式的结果更准确

·

1.13 梯度检验(Gradient checking)
梯度检验帮我节省了很多时间,也多次帮我发现backprop实施过程中的bug,接下来,我们看看如何利用它来调试或检验backprop的实施是否正确。

·

1.14 实现梯度检验的笔记(Gradient Checking Implementation Notes)
神经网络实施梯度检验的实用技巧和注意事项

·