deeplearning.ai 吴恩达网上课程学习(十五)——卷积神经网络及其TensorFlow代码实现


前面提到过:
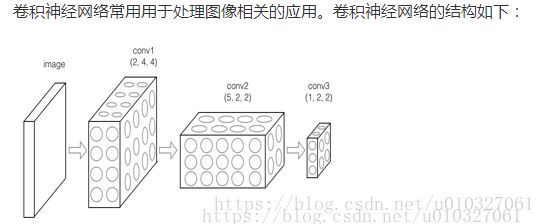
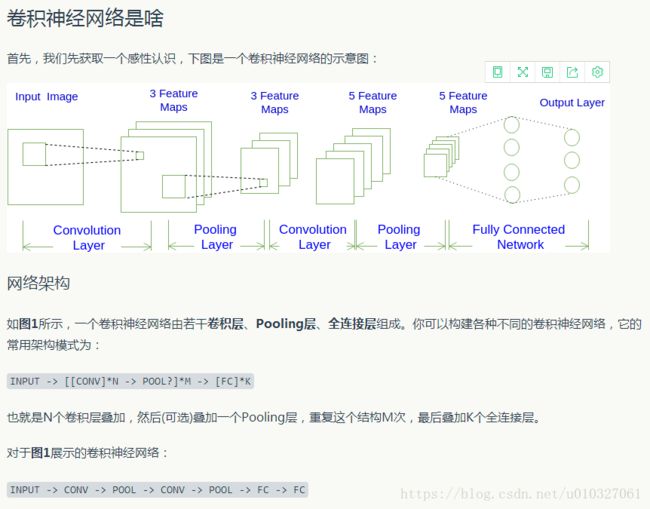


本文主要针对于卷积神经网络的讲解。
1、卷积神经网络
1.1.计算机视觉:
随着深度学习技术的发展,计算机视觉领域的研究也得到了快速的发展。在对各种图像进行处理的过程中,往往在少量的图像中便蕴含着大量数据,难以用一般的DNN进行处理。而卷积神经网络(Convolutional Neural Network, CNN)作为一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,在图像处理工作上有着出色的表现。
1.2.卷积神经网络:
前面在神经网络中提到过,构建一个深度神经网络来进行人脸识别时,深度神经网络的前面一层可以用来进行边缘探测,其次一层用来探测照片中组成面部的各个特征部分,到后面的一层就可以根据前面获得的特征识别不同的脸型等等。其中的这些工作,都是依托CNN实现的。
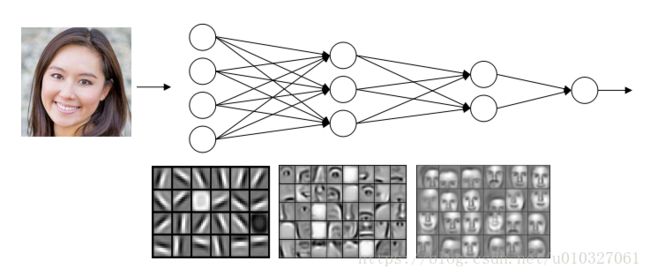
1.3.通过边缘检测的例子来阐述深度学习中卷积的基本概念。


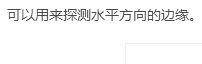
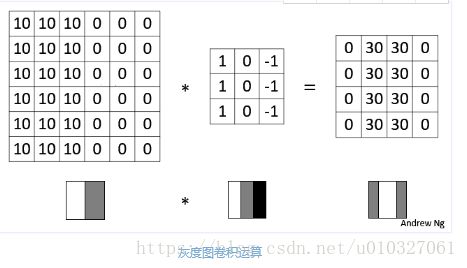


其实过滤器的9个参数也可以通过学习的方式获得,虽然比较费劲,但是可能会学到很多其他除了垂直,水平的边缘特征,例如45°,70°等各种特征。
1.4. Padding(填充):
前面可以看到,大小为6×6的矩阵与大小为3×3的滤波器进行卷积运算,得到的结果是大小为4×4的矩阵。假设矩阵的大小为n×n,而滤波器的大小为f×f,f一般是个奇数,则卷积后结果的大小就为(n−f+1)×(n−f+1)。(相当于去除了图像最外面一圈的像素)
(1)为什么要填充: 原来的矩阵与滤波器进行卷积后的结果中损失了部分,每经过一次卷积计算,原数据都会减小。
(2)填充方式:在进行卷积操作前,在原矩阵的边界上填充一些值,以增加矩阵的大小,通常都用“0”作为填充值。

(3)卷积方式:
- Valid 卷积:不进行填充处理,直接卷积卷积后结果的大小就为(n−f+1)×(n−f+1)。
- Same 卷积:进行填充,并使得卷积后结果的大小与原来的一致,这满足 (n+2p-f+1) = n ,时p=f−12。
p是填充数量,f是滤波矩阵大小,n是原矩阵大小。
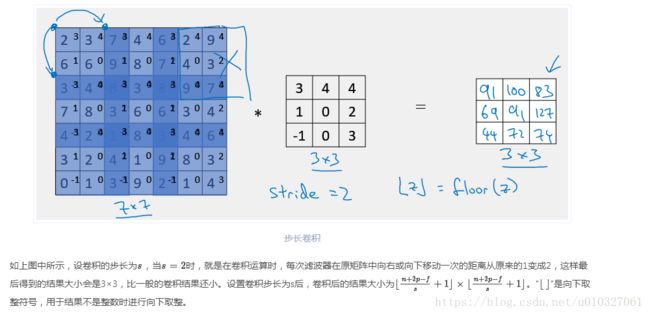
1.5. Stride(卷积步长):
可以压缩信息。
1.6. 三维卷积:

此外,还可以同时用多个滤波器来处理一个矩阵,以检测多个特征。如上图中第一个可以是用来检测检测图像矩阵的垂直边缘的滤波器,第二个可以是用来检测图像矩阵的水平边缘,把得到的两个结果组合在一起,结果是一个大小为4×4×2的矩阵。
上图则使用了两个过滤器,得到的特征矩阵大小为 4 * 4 * 2.
1.7 符号:

2.卷积神经网络结构:
2.1 单层卷积网络:
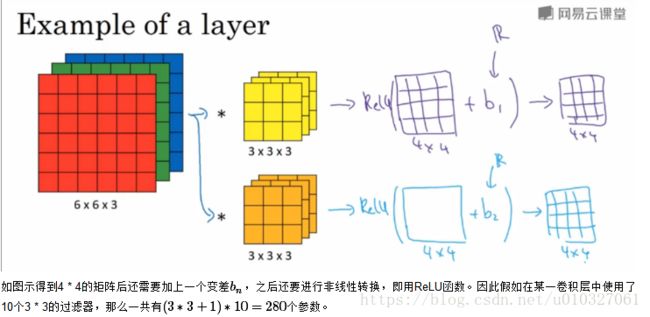

2.2 简单的卷积网络结构:
通常一个卷积神经网络是由输入层(Input)、卷积层(Convolution)、池化层(Pooling)、全连接层(Fully Connected)组成。
在输入层输入原始数据,卷积层中进行的是前面所述的卷积过程,用它来进行提取特征。全连接层就是将识别到的所有特征全部连接起来,并输出到分类器(如Softmax)。
2.3 Pooling layer(池化层):
作用是压缩数据,加速运算,同时提高所提取特征的鲁棒性。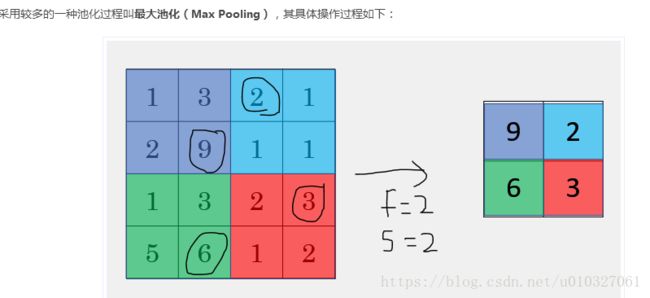

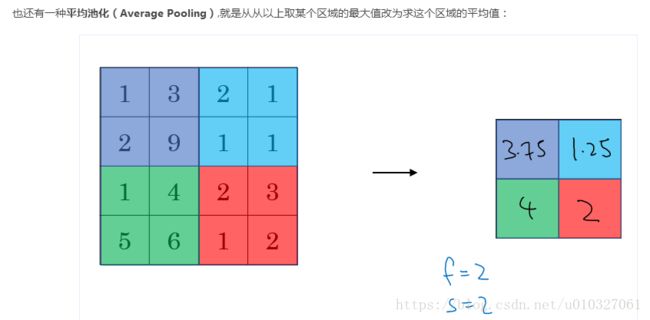

2.4 卷积网络结构示例:
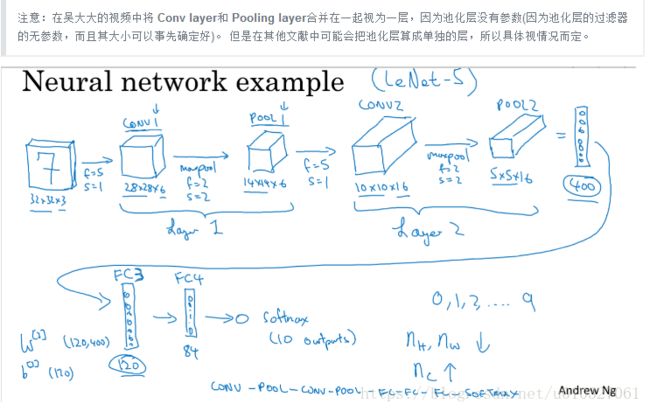
其中,一个卷积层和一个池化层组成整个卷积神经网络中的一层,图中所示整个过程为Input->Conv->Pool->Conv->Pool->FC->FC->FC—>Softmax。
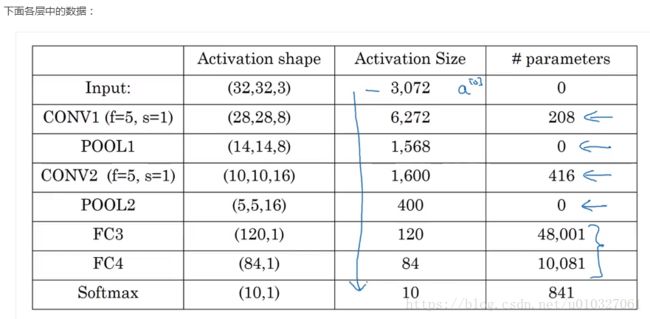
可以看出,激活的大小随着向卷积网络深层的递进而减小,参数的数量在不断增加后在几个全连接过程后将逐渐减少。
2.5 经典卷积网络:
2.5.1 LeNet-5:
LeNet-5是LeCun等人1998年在论文[Gradient-based learning applied to document recognition]中提出的卷积网络。其结构如下图:

该网络主要针对灰度图像训练的,用于识别手写数字。
当时很少用到Padding,所以可以看到随着网络层次增加,图像的高度和宽度都是逐渐减小的,深度则不断增加。
另外当时人们会更倾向于使用Average Pooling,但是现在则更推荐使用Max Pooling。
还有就是最后的预测没有使用softmax,而是使用了一般的方法。
2.5.2 AlexNet:
AlexNet是Krizhevsky等人2012年在论文[ImageNet classification with deep convolutional neural networks]中提出的卷积网络。其结构如下图:
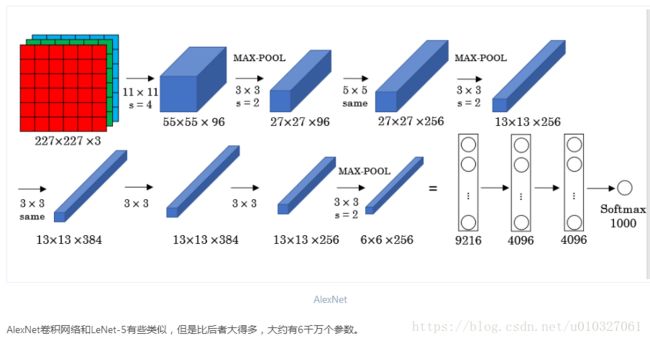 不同的地方主要有如下:
不同的地方主要有如下:
激活函数使用的是Relu,最后一层使用的是Softmax
参数更多,有6000万个参数,而LeNet-5只有6万个左右
使用Max Pooling
2.5.3 VGG-16:
VGG-16是Simonyan和Zisserman 2015年在论文[Very deep convolutional networks for large-scale image recognition]中提出的卷积网络。其结构如下图:
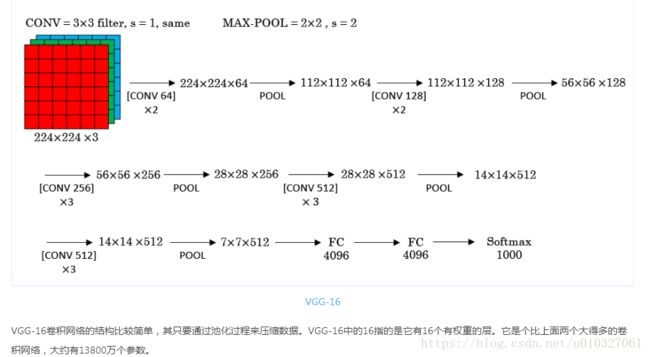
因为它有将近1.38亿个参数,即使放到现在也是一个很大的网络,但是这个网络的结构并不复杂。下面主要介绍一下上图网络。
首先该网络使用的是Same卷积,即保证高度和宽度不变,另外因为总共有16层卷积操作,所以就不把每一层都用图像的方式表现出来了,例如[CONV 64 X2]表示的是用64个过滤器进行Same卷积操作2次,即右上角所画的示意图,(224,224,3) -> (224,224,64) -> (224,224,64)
上面三个是比较经典的网络,如果想深入的理解,可以阅读其论文,不过吴大大建议的阅读顺序是AlexNet->VGG->LeNet。
2.6 残差网络ResNets:
当一个神经网络某个深度时,将会出现梯度消失(Vanishing Gradient)和梯度爆炸(Exploding Gradient)等问题。而ResNets能很好得解决这些问题。
ResNets全称为残差网络(Residual Networks),它是微软研究院2015年在论文[Deep Residual Learning for Image Recognition]中提出的卷积网络。
(1)残差块:(Residual Block)


(2)残差网络

结合之前的课程我们知道如果使用普通网络训练模型,训练误差会随着网络层次加深先减小,而后会开始增加,而残差网络则不会有这种情况,反而它会随着层次增加,误差也会越来越小,这与理论相符。
对于一个神经网络中存在的一些恒等函数(Identity Function),残差网络在不影响这个神经网络的整体性能下,使得对这些恒等函数的学习更加容易,而且很多时候还能提高整体的学习效率。
为什么残差网络比普通的神经网络好?参看:https://www.zhihu.com/question/38499534
用一句话解释就是,深度网络容易造成梯度在back propagation的过程中消失,导致训练效果很差,而深度残差网络在神经网络的结构层面解决了这一问题,使得就算网络很深,梯度也不会消失。
2.7 Network In NetWork 网络中的网络以及1*1卷积:
2013年新加坡国立大学的林敏等人在论文[Network In NetWork]中提出了1×1卷积核及NIN网络。
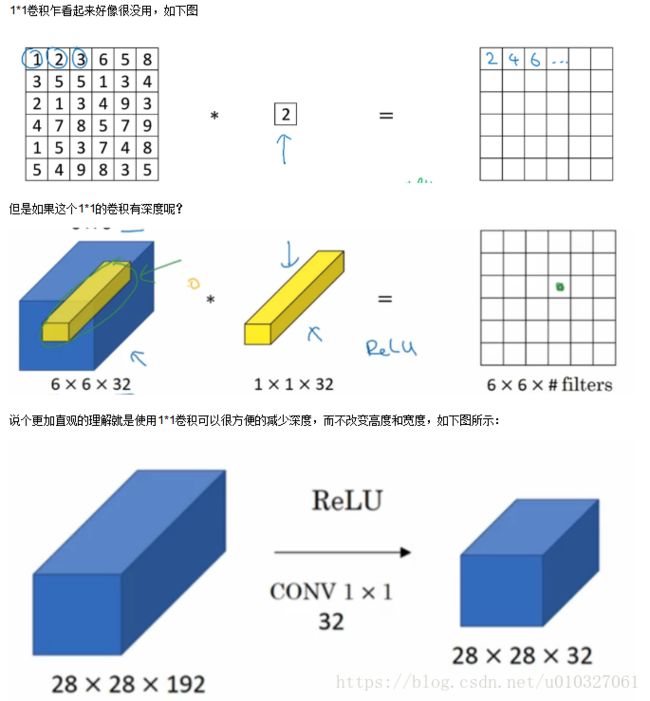

换句话说,1×1的卷积核操作实现的其实就是一个特征数据中的多个Feature Map的线性组合,所以这个方法就可以用来改变特征数据的信道数。
2.8 Inception Network
最早的Inception结构的V1版本是由Google的Szegedy 2014年在论文[Going deeper with convolutions]中提出的,它是ILSVRC 2014中取得最好成绩的GoogLeNet中采用的的核心结构。通过不断改进,现在已经衍生有了V4版本。
如下图,我们使用了各种过滤器,也是用了Max Pooling。但是这些并不需要人工的选择其个数,这些都可以通过学习来确定下来。所以这种方法很好的帮助我们选择何种过滤器的问题,这也就是Inception网络。
计算成本:
通常在设计一个卷积网络的结构时,需要考虑卷积过程、池化过程的滤波器的大小,甚至是要不要使用1×1卷积核。在Inception结构中,考虑到多个不同大小的卷积核(滤波器)能够增强网络的适应力,于是分别使用三个大小分别为1×1、3×3、5×5的卷积核进行same卷积,同时再加入了一个same最大池化过程。最后将它们各自得到的结果放在一起,得到了图中一个大小为28×28×256的结果。然而,这种结构中包含的参数数量庞大,对计算资源有着极大的依赖,上面的例子中光是与大小为5×5的滤波器进行卷积的过程就会产生1亿多个参数!
瓶颈层:
在其中的过程中,再加入1×1卷积能有效地对输出进行降维。如上图中所示,中间的一层就像是一个沙漏的瓶颈部分,所以这一层有时被称为瓶颈层(Bottleneck Layer)。通过1×1卷积,最后产生参数数量有1240万左右,相比起原来的1亿多要小了许多。
在论文中提出的整个Inception模型结构如下:
在一个卷积网络中加入多个这种模型,就构成了一个Inception网络,也就是GoogLeNet:
其中还包含一些额外的最大池化层用来聚合特征,以及最后的全连接层。此外还可以从中间层的一些Inception结构中直接进行输出(图中没有画出),也就是中间的隐藏层也可以直接用来参与特征的计算及结果预测,这样能起到调整的作用,防止过拟合的发生。
Inception模型后续有人提出了V2、V3、V4的改进,以及引入残差网络的版本,这些变体都源自于这个V1版本。
在建立一个卷积神经网络时,可以从参考Github等网站上其他人建立过的相关模型,必要时可以直接拿来根据拥有的数据量大小进行前面介绍过的迁移学习,从而减轻一些工作负担。
当收集到的图像数据较少时,可以采用优化神经网络中讲过的数据扩增法,对现有的图像数据进行翻转、扭曲、放大、裁剪,甚至是改变颜色等方法来增加训练数据量。
(改变颜色Color shifting:我们都知道图像是由RGB三种颜色构成的,所以该数据扩充方法常采用PCA color augmentation,即假如一个图片的R和G成分较多,那么该算法则会相应的减少R,G的值,而增加B的值)
4.卷积神经网络的原生实现及应用示例
https://www.missshi.cn/api/view/blog/5a93842b5b925d1941000001
在上文中,首先将以Python语言为例,原生实现卷积神经网络的相关层,从而更加深入的了解卷积网络的基本原理。
接下来,我们会以Tensorflow库为例进行卷积神经网络应用示例的学习,从而学习如何利用Tensorflow快速进行模型的搭建和训练。
5.pytorch代码以及详解:
机器学习pytorch平台代码学习笔记(9)——卷积神经网络
参考文献:
先推荐一篇好文章:https://www.zybuluo.com/hanbingtao/note/485480
1. http://binweber.top/2017/11/28/deep_learning_7/#卷积神经网络
2. http://www.cnblogs.com/marsggbo/p/8166487.html
3.https://baijia.baidu.com/s?id=1584738954576041362&wfr=pc&fr=app_lst
4.https://www.missshi.cn/api/view/blog/5a93842b5b925d1941000001