Hive 基本操作命令
前言
前面两章, 我们介绍了如何安装Hive和如何远程链接Hive. 本章, 我们介绍下Hive的基本文件结构和操作.
基础知识
- Hive的所有数据都存储在
HDFS上, 没有专门的数据存储格式(支持 Text、SequenceFile、ParquetFile、RCFILE等) (Text与SequenceFile为Hadoop自带的文件格式,ParquetFile与RCFILE为两个不同的公司开发出的文件格式. 其中ParquetFile在Spark内有广泛的使用.) - 创建表的时候只要指定列分隔符和行分隔符, Hive即可解析数据.
- Hive内主要包含以下的数据模型:
DB/Table/Externel Table/Partition/Bucket.- DB : 在
HDFS内表现为$hive.metastore.warehouse.dir目录下的一个文件目录. - Table : 在
HDFS内表现为所属DB目录下的一个文件夹. - Externel Table: 与
Table累死, 不过其位置可以指定任意路径. - Partition : 在
HDFS中表现为Table目录下的子目录. - Bucket : 在
HDFS中表现为同一个表目录下根据Hash散列之后的多个文件夹.
- DB : 在
命令手册
表
对于表命令的相关参数如下所示:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type[COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_namedata_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name,col_name, ...)
[SORTED BY (col_name[ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
基本操作
本节, 将主要介绍如何在Hive内创建DB/普通表/外部表/分区表/分块表.
DB
- 创建
DB/ 使用DB
# 查看DB
0: jdbc:hive2://localhost:10000> show databases;
+----------------+
| database_name |
+----------------+
| default |
| flow |
+----------------+
2 rows selected (1.772 seconds)
# 使用DB
0: jdbc:hive2://localhost:10000> use flow;
No rows affected (0.134 seconds)
# 创建DB
0: jdbc:hive2://localhost:10000> create database tmp123;
No rows affected (0.488 seconds)
0: jdbc:hive2://localhost:10000> show databases;
+----------------+
| database_name |
+----------------+
| default |
| flow |
| tmp123 |
+----------------+
3 rows selected (0.359 seconds)
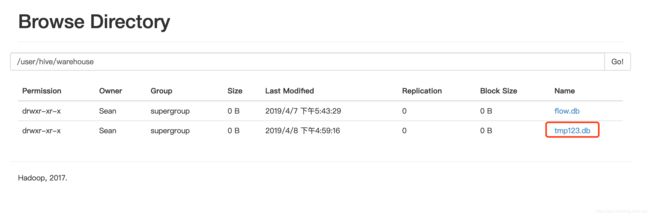
值得注意的是, 创建完成后, 会在HDFS上的/user/hive/warehouse目录创建相应的文件.
普通表相关操作
# 创建普通表
0: jdbc:hive2://localhost:10000> create table course (Cno int,Cname string) row format delimited fields terminated by ',' stored as textfile;
No rows affected (0.305 seconds)
使用load命令, 导入数据.
# 导入本地文件
0: jdbc:hive2://localhost:10000> load data local inpath '/Users/Sean/Desktop/course.txt' into table course;
注: 导入HDFS内的文件不需要在前面加local.
# course.txt
1,数据库
2,数学
3,信息系统
4,操作系统
5,数据结构
6,数据处理
- 查询
0: jdbc:hive2://localhost:10000> select * from course;
+-------------+---------------+
| course.cno | course.cname |
+-------------+---------------+
| 1 | 数据库 |
| 2 | 数学 |
| 3 | 信息系统 |
| 4 | 操作系统 |
| 5 | 数据结构 |
| 6 | 数据处理 |
+-------------+---------------+
6 rows selected (0.334 seconds)
外部表相关操作
- 创建外部表
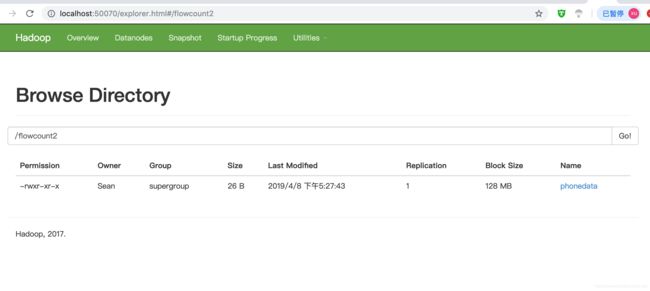
create external table t_phone_type2(id int, name string) row format delimited fields terminated by " " stored as textfile location '/flowcount2/';
- 导入数据
0: jdbc:hive2://localhost:10000> load data local inpath '/Users/Sean/Desktop/phonedata' into table t_phone_type2;
No rows affected (0.8 seconds)
0: jdbc:hive2://localhost:10000> select * from t_phone_type2;
+-------------------+---------------------+
| t_phone_type2.id | t_phone_type2.name |
+-------------------+---------------------+
| 1 | xiaomi |
| 2 | huawei |
| 3 | iphone |
+-------------------+---------------------+
3 rows selected (0.271 seconds)
- 查看表结构
# 查看表结构
0: jdbc:hive2://localhost:10000> desc t_phone_type;
+-----------+------------+----------+
| col_name | data_type | comment |
+-----------+------------+----------+
| id | int | |
| name | string | |
+-----------+------------+----------+
2 rows selected (0.218 seconds)
# 查看表结构的详细信息
0: jdbc:hive2://localhost:10000> desc extended t_phone_type;
+-----------------------------+----------------------------------------------------+----------+
| col_name | data_type | comment |
+-----------------------------+----------------------------------------------------+----------+
| id | int | |
| name | string | |
| | NULL | NULL |
| Detailed Table Information | Table(tableName:t_phone_type, dbName:flow, owner:Sean, createTime:1554627433, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:id, type:int, comment:null), FieldSchema(name:name, type:string, comment:null)], location:hdfs://localhost:9000/flowcount, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{serialization.format= , field.delim= }), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[], parameters:{transient_lastDdlTime=1554627433, totalSize=291, EXTERNAL=TRUE, numFiles=2}, viewOriginalText:null, viewExpandedText:null, tableType:EXTERNAL_TABLE, rewriteEnabled:false) | |
+-----------------------------+----------------------------------------------------+----------+
4 rows selected (0.231 seconds)
0: jdbc:hive2://localhost:10000>
#格式化查看 desc formatted t_phone_type;
0: jdbc:hive2://localhost:10000> desc formatted t_phone_type;
+-------------------------------+----------------------------------------------------+-----------------------+
| col_name | data_type | comment |
+-------------------------------+----------------------------------------------------+-----------------------+
| # col_name | data_type | comment |
| | NULL | NULL |
| id | int | |
| name | string | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | flow | NULL |
| Owner: | Sean | NULL |
| CreateTime: | Sun Apr 07 16:57:13 CST 2019 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Retention: | 0 | NULL |
| Location: | hdfs://localhost:9000/flowcount | NULL |
| Table Type: | EXTERNAL_TABLE | NULL |
| Table Parameters: | NULL | NULL |
| | EXTERNAL | TRUE |
| | numFiles | 2 |
| | totalSize | 291 |
| | transient_lastDdlTime | 1554627433 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | -1 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| Storage Desc Params: | NULL | NULL |
| | field.delim | |
| | serialization.format | |
+-------------------------------+----------------------------------------------------+-----------------------+
30 rows selected (0.211 seconds)
0: jdbc:hive2://localhost:10000>
- 删除表
drop table t_phone_type2;
值得注意的是, 外部表删除后, 其在HDFS上存储的文件并不会被删除.
分区表
- 创建分区表
create table t_phone_type_part(id int, name string) partitioned by (country string) row format delimited fields terminated by " ";
- 导入数据(指定分区)
0: jdbc:hive2://localhost:10000> load data local inpath '/Users/Sean/Desktop/phonedata' into table t_phone_type_part partition(country='china');
No rows affected (0.637 seconds)
0: jdbc:hive2://localhost:10000> load data local inpath '/Users/Sean/Desktop/phonedata' into table t_phone_type_part partition(country='Japan');
No rows affected (0.666 seconds)
- 查询分块表
0: jdbc:hive2://localhost:10000> select * from t_phone_type_part;
+-----------------------+-------------------------+----------------------------+
| t_phone_type_part.id | t_phone_type_part.name | t_phone_type_part.country |
+-----------------------+-------------------------+----------------------------+
| 1 | xiaomi | Japan |
| 2 | huawei | Japan |
| 3 | iphone | Japan |
| 1 | xiaomi | china |
| 2 | huawei | china |
| 3 | iphone | china |
+-----------------------+-------------------------+----------------------------+
6 rows selected (0.245 seconds)
可以看到的是, 根据分区的属性, 创建了虚拟列. 其信息也是存储在两个文件内.

- 添加分片 / 删除分片
0: jdbc:hive2://localhost:10000> alter table t_phone_type_part add partition(country="American");
No rows affected (0.211 seconds)
0: jdbc:hive2://localhost:10000> alter table t_phone_type_part drop partition(country="Japan");
No rows affected (0.25 seconds)
分块表
- 创建分块表
create table t_buk(id string,name string) clustered by (id) sorted by (id) into 4 buckets row format delimited fields terminated by ',' stored as textfile;
- 导入数据-错误
0: jdbc:hive2://localhost:10000> load data local inpath '/Users/Sean/Desktop/sc.txt' into table t_buk;
Error: Error while compiling statement: FAILED: SemanticException Please load into an intermediate table and use 'insert... select' to allow Hive to enforce bucketing. Load into bucketed tables are disabled for safety reasons. If you know what you are doing, please sethive.strict.checks.bucketing to false and that hive.mapred.mode is not set to 'strict' to proceed. Note that if you may get errors or incorrect results if you make a mistake while using some of the unsafe features. (state=42000,code=40000)
# 大概意思就是, 对于分桶表的操作要使用 insert...select的语法进行操作
- 导入数据-正确
# 创建临时表
create table t_buk_tmp(id string,name string) row format delimited fields terminated by ',' stored as textfile;
# 导入数据到临时表
load data local inpath '/Users/Sean/Desktop/sc.txt' into table t_buk_tmp;
# insert-select方式导入
insert into t_buk select * from t_buk_tmp ;
# 分区且有序 (cluster by 已经具有 sort by的含义)
insert into t_buk select * from t_buk_tmp cluster by(id) into t_buk sort by (id);
hive创建桶表
# 有人写的需要打开开关, 我没有需要这样操作(大概是版本不同导致)
set hive.enforce.bucketing = true;
# 默认的数量 (reduce数量要与分桶数量一致)
set mapreduce.job.reduces = 4;
分桶表的最大作用就是提高join操作的效率.
select a.id,a.name,b.id,b.name from a left join b on a.id = b.id;
# 如果a和b为分桶表, 那么join操作不需要做全表的笛卡尔集合了.
Select & 排序 相关操作
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[CLUSTER BY col_list| [DISTRIBUTE BY col_list][SORT BY| ORDER BY col_list]
][LIMIT number]
order by会对输入做全局排序, 因此只有一个reducer, 会导致当输入规模较大时, 需要比较长的计算时间;sort by不是全局排序, 其数据进入reducer前完成排序. 因此,如果使用sort by进行排序, 且设置mapred.reduce.tasks>1, 则sort by只保证每个reducer有序, 不保证所有都有序.distributed by根据distributed by指定的内容, 将数据分到不同的reducer, 分发算法为hash散列.cluster by除了具有clutser by的功能之外, 还会对该字段进行排序.- 分桶和sort字段为同一个字段时,
cluster by = distributed by + sort by.

show相关操作
# 显示所有表
show tables;
# 显示数据库
show databases;
# 显示分区(如果表不是分区表,会报错)
show partitions t_name;
# 显示存在的函数
show functions;
# 显示表的内容
desc extended t_name;
# 结构化显示表结构
desc formatted table_name;
0: jdbc:hive2://localhost:10000> show partitions t_phone_type_part;
+-------------------+
| partition |
+-------------------+
| country=American |
| country=china |
+-------------------+
2 rows selected (0.221 seconds)
hive partition 分区详解一
Hive分区partition详解
join相关操作
- LEFT JOIN & RIGHT JOIN & FULL JOIN
select a.*,b.* from a join b on a.id=b.id;
- LEFT SEMI JOIN 取代
IN/EXISTS
# 原版SQL
select a.key,a.value from a where a.key exist in( select b.key from b);
# 改写
select a.key,a.val from a left semi join b on (a.key=b.key);
select s.Sname from student s1 left semi join student s2 on s1.Sdept=s2.sdept and s2.Sname='hellokitty';
# others
select * from student s1 left join student s2 on s1.Sdept=s2.sdept and s2.Sname='hellokitty';
select * from student s1 right join student s2 on s1.Sdept=s2.sdept and s2.Sname='hellokitty';
select * from student s1 inner semi join student s2 on s1.Sdept=s2.sdept and s2.Sname='hellokitty';
select s.Sname from student s1 left semi join student s2 on s1.Sdept=s2.sdept and s2.Sname='hellokitty';
多重插入
from student
insert into table student_p partition(part='a')
select * from Sno<10001;
insert into table student_p partition(part='a')
select * from Sno<10001;
保存查询结果
- 将查询结果保存到一个新的
hive表内
create table t_tmp as select * from t_buk;
- 将查询结果保存到一个已经存在的
hive表呢
insert into table t_tmp select * from t_buk;
- 导出到目录文件(本地/HDFS)
# Local
insert overwrite local directory '/home/hadoop/test' select * from t_p;
# HDFS
insert overwrite directory '/home/hadoop/test' select * from t_p;
自定义函数 & Transform操作
# 添加Jar包
add jar /home/admin1/hadoop/lx/udf.jar;
CREATE TEMPORARY FUNCTION convert AS 'cn.tf.hive.ConvertUDF';
select phone,convert(phone),url,convert(upflow,downflow) from t_flow;
Hive的HQL语句及数据倾斜解决方案
Reference
[1]. Hive基本操作与案例
[2]. hive的基本操作,hive的具体实例