Ubuntu 16.04 Tensorflow-gpu 1.4.1+GTX1080 +pycharm 环境搭建(附高清无码大图)
牢骚
上来必须牢骚一下这几天的装机感受,准确的说是5天!就为这么点破玩意。
首先是准备Ubuntu16.04 ,一开始以为win10家和ubuntu家是吵架了,Ubuntu装完开机引导各种失败各种看贴,最终总结出2点经验:
- 主板Boot Mode 必须改成uefi模式;
- Ubuntu的“安装启动引导器的设备”必须选择/boot所在分区;
花了两天解决了Ubuntu系统的种种问题后,完美。直奔主题开始准备安装Tensorflow,不对准确的说是Tensorflow-gpu,毕竟我的1080已经饥渴难耐了,区区一个cpu版怎么能满足我向朋友们扯犊子的深度需要呢。
下面是所需的软件清单:
- Python2.7
- 显卡驱动
- CUDA 8.0 (请不要处女座,非得要求最新版本,不要问我是怎么死的)
- cuDNN v6.0 (同样,请不要作死,非得要最新版本)
- tensorflow-gpu1.4.1
- pycharm
准备工作
一开始使用的是系统默认的源,50M的宽带供养一个tensorflow时居然只有20来k,虽说男人不能太快,但是过于持久实在扛不住,果断换源。
- 更新Ubuntu16.04源,用的是中科大的源:
cd /etc/apt/
sudo nano sources.list 把下面的这些源添加到source.list文件头部:
deb http://mirrors.ustc.edu.cn/ubuntu/ xenial main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu/ xenial-security main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu/ xenial-updates main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu/ xenial-proposed main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu/ xenial-backports main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu/ xenial main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu/ xenial-security main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu/ xenial-updates main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu/ xenial-proposed main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu/ xenial-backports main restricted universe multiverse
最后更新源和更新已安装的包:
sudo apt-get update
sudo apt-get upgrade
将pip源指向清华大学的源镜像:https://mirrors.tuna.tsinghua.edu.cn/help/pypi/,具体添加一个 ~/.config/pip/pip.conf 文件,设置为:
[global] index-url = https://pypi.tuna.tsinghua.edu.cn/simple
既然都源换了,那就顺带把需要的几个库也装好吧,早买晚买,早晚要买,一步到位。
sudo apt-get install python-pip
sudo apt-get install python-numpy swig python-dev python-wheel准备完毕,一键起飞。
1.显卡驱动安装
打开terminal输入以下指令:
sudo apt-get update然后在系统设置->软件更新->附加驱动->选择nvidia最新驱动->应用更改
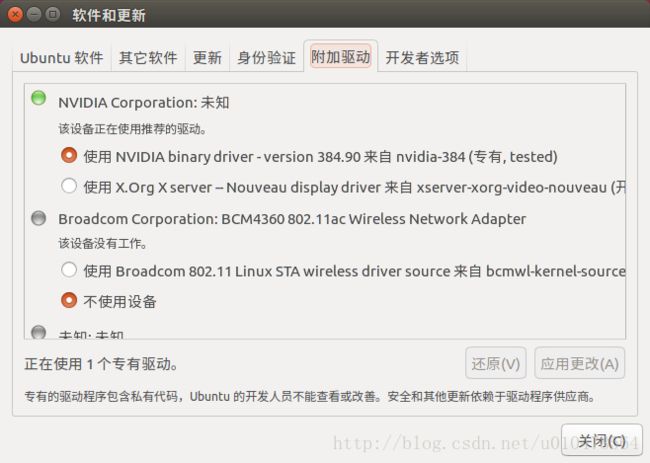
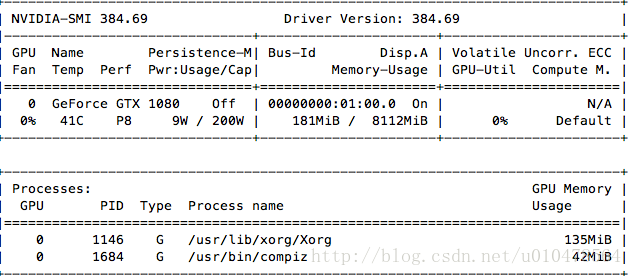
安装结束后,运行nvidia-smi,如果出现下图,恭喜,显卡驱动大功告成,接下来小步快走直奔小康。
2.安装CUDA
本着新得就是好得的原则,我上来就从官网上选了CUDA9.0,然和事实却不是这样的.
tensorflow官方版本目前不支持CUDA9, 但CUDA8是妥投没问题的。不信请看大神如何优雅刨坑。
http://www.52nlp.cn/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E6%9C%8D%E5%8A%A1%E5%99%A8%E7%8E%AF%E5%A2%83%E9%85%8D%E7%BD%AE-ubuntu17-04-nvidia-gtx-1080-cuda-9-0-cudnn-7-0-tensorflow-1-3
CUDA下载地址如下:https://developer.nvidia.com/cuda-80-ga2-download-archive
请勇敢地选择 runfile[local] 版本。

下载完毕,进入文件的保存路径,运行如下代码:
sudo sh cuda_8.0.61_375.26_linux.run开始安装,首先是一份长达两公里的协议,一直按回车到底以后,输入accept。其他的操作如下所示
Do you accept the previously read EULA?
accept/decline/quit: accept
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 367.48?
(y)es/(n)o/(q)uit: n
Install the CUDA 8.0 Toolkit?
(y)es/(n)o/(q)uit: y
Enter Toolkit Location
[ default is /usr/local/cuda-8.0 ]:
Do you want to install a symbolic link at /usr/local/cuda?
(y)es/(n)o/(q)uit: y
Install the CUDA 8.0 Samples?
(y)es/(n)o/(q)uit: y除了询问是否安装显卡驱动选 n ,其他地方均为y。CUDA自带的显卡驱动就像一个小三,只能偷摸玩玩,正式场合还得原配出马才行。
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 367.48?
(y)es/(n)o/(q)uit: n紧接着,配置环境变量:
方法多样,我选择了修改~/.bashrc。勇敢地打开它,在尾部加上这么两句话,然后请默默离开。
export PATH=/usr/local/cuda-8.0/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64:$LD_LIBRARY_PATH 出门在外莫忘生计,不对是保存后请运行:
source ~/.bashrc 安装结束。我想男人的好,只有在他身边的那个女人才知道。是应该编译一个sample, 试试不就知道姿势对不对了。
编译之前还有一件事必须处理了,ubuntu的gcc编译器是5.4.0,然而cuda8.0不支持5.3以上的编译器,因此需要降级,把编译器版本降到5.4以下,这里我选的是gcc 4.8。
- sudo apt-get install gcc-4.8
- 查看默认的gcc版本 ,指令如下:
gcc --version不出意外的话会返回ubuntu16.04自带的5.4.0这个版本号,现在使用gcc命令编译时还是会用新版本。
3. 接着设置默认gcc版本,代码如下:
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.8
1004.再看一眼gcc的默认版本,你好我也好,应该是4.8了。
接着编译cuda自带的Sample,指令如下:
cd /usr/local/cuda/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery结果应该是这样的:

此情此景不经想让人吟诗一首:啊!~~~
3.安装cuDNN
下载地址如下:
https://developer.nvidia.com/rdp/cudnn-download
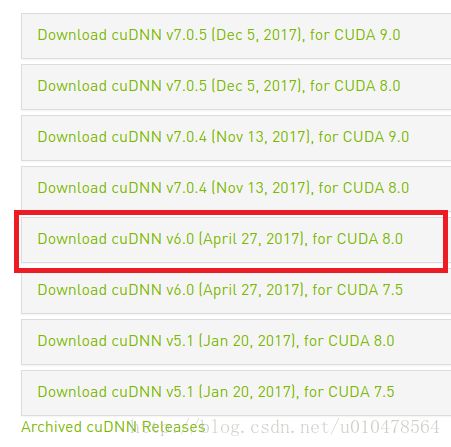
头一次又是抱着买贵的就买对的传统美德,下载了V7.0.5,最后运行tensorflow报错,报错是这样子的:
libcudnn.so.6:cannot open sharedobjectfile: No such file or directory根据错误代码,应该是找不到libcudnn.so.6。到指定文件夹下发现只有7.0和8.0的版本,没有6.0,查找原因是因为当前已经是1.4版本,而tensorflow-gpu1.4已经开始去找cudnn6了。
所以千万不要被这花花世界迷惑了,成功的标配—-v6.0 for CUDA8.0。
载下来以后,发现是一个tgz的压缩包,使用tar进行解压:
tar -xvf cudnn-8.0-linux-x64-v6.0.tgz解压后再把相应的文件拷贝到对应的CUDA目录下即可
sudo cp cuda/include/cudnn.h /usr/local/cuda/include/
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/cudnn.h
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*是啊,cuDNN的安装就是这两步,要是爱情也这么简单就好了。
4.安装Tensorflow1.4.1
在安装Tensorflow之前,按照Tensorflow官方安装文档的说明,需要先安装一个libcupti-dev库:
sudo apt-get install libcupti-dev
千呼万唤始出来,安装tensorflow:
pip install tensorflow-gpu接下来就是默默得等待了,换源之后果然快的惊人,充电两小时,开心五分钟。
安装完毕,进入python:
>>> import tensorflow as tf
>>> hello = tf.constant('Hello, TensorFlow!')
>>> sess = tf.Session()
>>> print(sess.run(hello))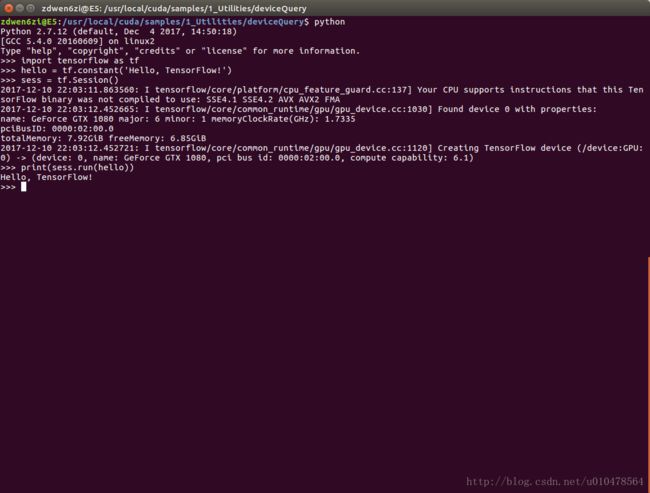
事情到这里应该就算结束了,
但是我们怎么能满足于在控制台里静静的装逼呢。
安装pycharm
从官网下载pycharm,地址如下:
http://www.jetbrains.com/pycharm/download/#section=linux下载完成后,解压,然后进入pycharm的bin目录,打开控制台运行 sh ./pychram.sh,跟着提示来安装。大功告成!
打开软件后,先配置python解释器,我用的是2.7,选跟控制台的python的同一路径:
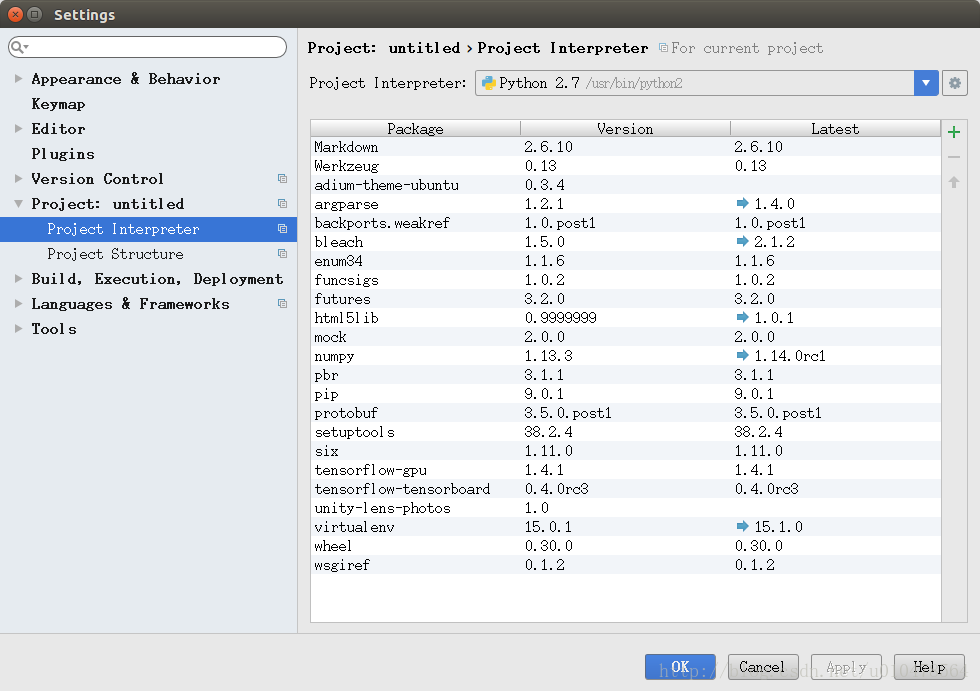
万事俱备,准备起飞。
随便敲了几行代码进去,结果怎么跟想象的不一样呢,十分尴尬!
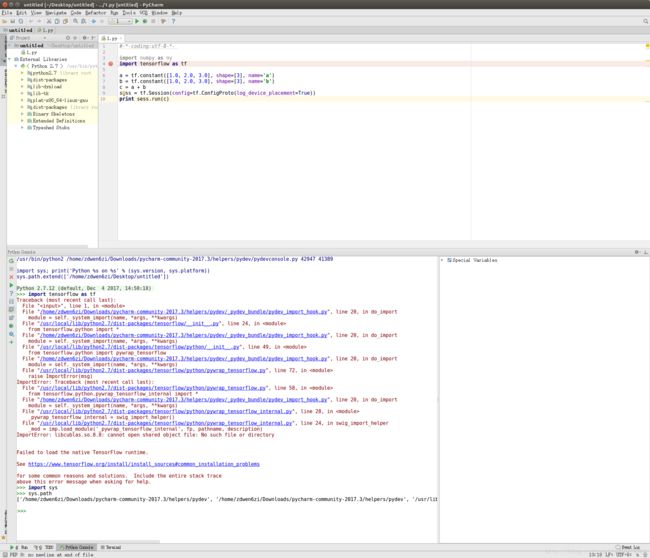
报错为:
ImportError:libcublas.so.8.0:cannot open shared object file:No such file or dircetory进过两天的冥想,终于知道的了问题所在,还是环境变量设置的问题,
于是依照另一位大神的指导重新配置了cuda的环境变量:
- 更改~/.bashrc
export PATH=/usr/local/cuda-8.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}- 设置环境变量和动态链接库,在命令行输入:
sudo gedit /etc/profile
在打开的文件末尾加入:
export PATH = /usr/local/cuda/bin:$PATH- 创建链接文件,在命令行输入:
sudo gedit /etc/ld.so.conf.d/cuda.conf
在打开的文件中添加如下语句:
/usr/local/cuda/lib64- 最后使链接立即生效:
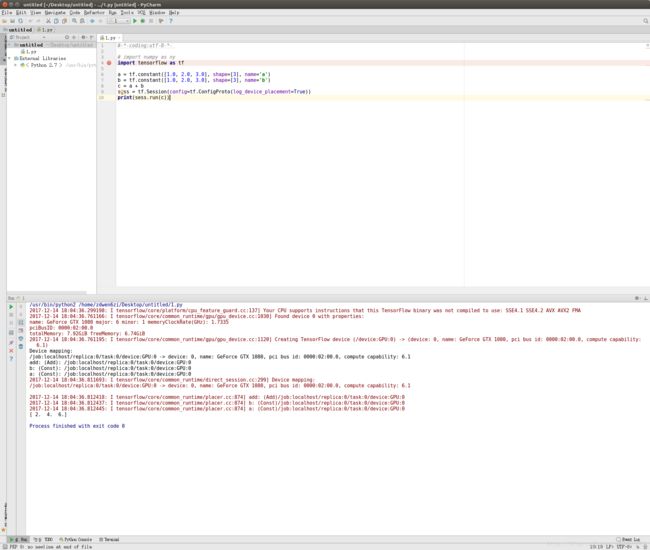
sudo ldconfig总结
刚翻过了几座山
又越过了几条河
崎岖坎坷怎么它就这么多
用了将近五天时间终于从一个又一个坑里爬了出来,谁知道八年抗战才刚刚开始。
以上均为抛砖引玉,希望能给还在痛苦挣扎的朋友一些借鉴,同时也欢迎各位大神前来拍砖,在交流中不断进步!
史料参考:
http://blog.csdn.net/u014595019/article/details/53732015
http://www.52nlp.cn/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E4%B8%BB%E6%9C%BA%E7%8E%AF%E5%A2%83%E9%85%8D%E7%BD%AE-ubuntu-16-04-nvidia-gtx-1080-cuda-8
http://www.52nlp.cn/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E6%9C%8D%E5%8A%A1%E5%99%A8%E7%8E%AF%E5%A2%83%E9%85%8D%E7%BD%AE-ubuntu17-04-nvidia-gtx-1080-cuda-9-0-cudnn-7-0-tensorflow-1-3
http://www.linuxidc.com/Linux/2017-01/139321.htm