1. 概说
缓冲区溢出又叫堆栈溢出(还有许许多的称呼),这是计算机程序难以避免的漏洞,除非有新的设计方式将程序运行的堆栈设计取代。
溢出的目的是重写程序的运行堆栈,使调用返回堆栈包含一个跳向预设好的程序的程序(代码),这个程序通常称为shellcode,通过这个shellcode就能获得如期的shell,更有可能获得root。
2. 缓冲区溢出的原理
计算机中每一个运行中的程序都有相同的内存布局(逻辑布局),Linux/Unix的程序布局大体如下:
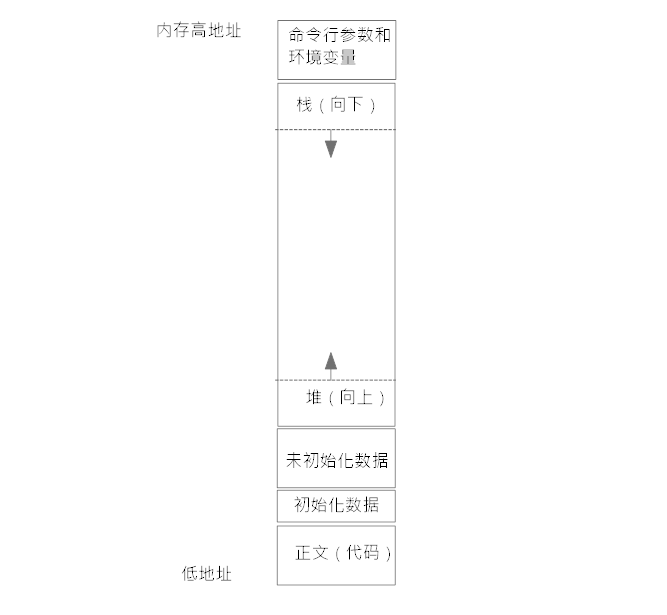
缓冲区溢出就是利用这个布局中的堆栈段来作文章的。
堆: 通常用来作为动态存储分配,如C标准库函数 malloc 就是在堆里申请内存空间的
栈: 自动变量和每次函数调用时所需保存的信息存放的地方。栈是自顶向下生长的,栈还有一个特别的地方,就是先进后出,往栈放数据就好比往洞里塞东西,当拿东西的时候只能先把最外面的拿走。
其中,最重要的一点: 栈中保存了函数调用时的返回地址。
缓冲区溢出的目的就是要将栈中保存的返回地址篡改成成溢出的数据,这样就间接修改了函数的返回地址,当函数返回时,就能跳转到预设的地址中,执行植入的代码。
3. 缓冲区溢出需要掌握的知识
程序运行时的堆栈布局,请看上图。
C语言基础知识,这个可以看C语言相关的入门书籍,如《The C Programming language》。
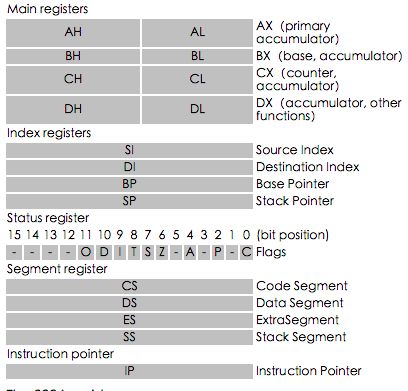
汇编基础,可以看入门的书籍,如《Assembly.Language.Step-by-Step》,下面简单介绍一下:
寄存器: 通用寄存器有 AX, BX, CX,DX, DI, SI, BP, SP 共有8个,x86_64bit的cpu新增了八个通用寄存器,分别是r8,r9…r15, 8-15共8个。
非通用寄存器,即专用寄存器,最重要的是IP, 它总是指向cpu要执行的下一条指令的地址。这个很重要,缓冲区溢出的目的就是要修改ip的值。
通常寄存器名称前都有修饰符,主要用来区分寄存器所代表的值的位数,32位的寄存器前面有E,如EAX、EBX等,64位的寄存器前面则有R,如RAX,RBX等。
BP和SP虽然是通用寄存器,但它专用为栈的基址(BP)指向栈的底部,SP指向栈的顶部。
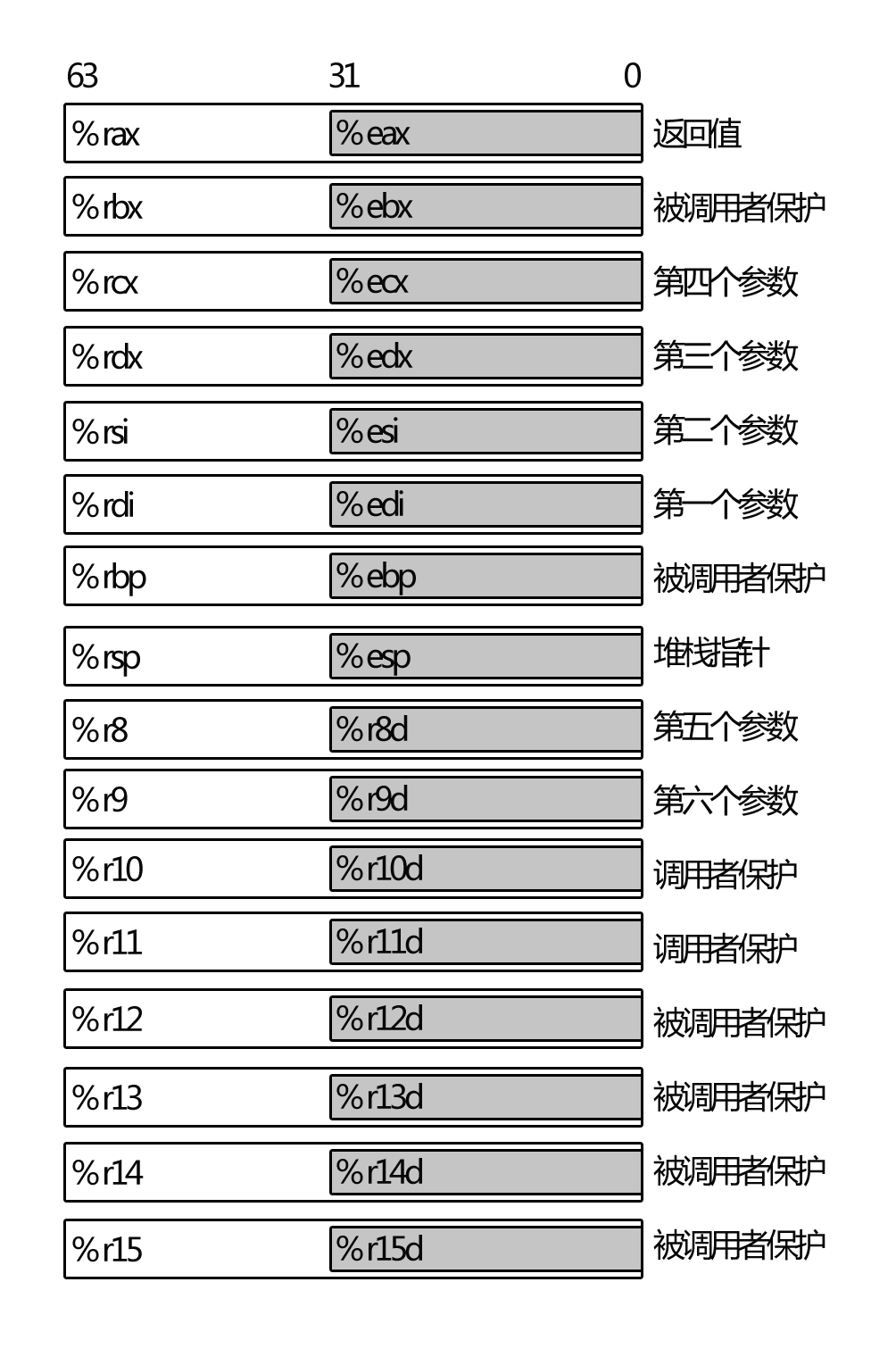
64位CPU因为通用寄存器比32位的多,所以函数的参数分别用di,si,dx,cx,r8,r9去保存。
AX寄存器通常用来保存函数返回值。
4. 见证缓冲区溢出
4.1 测试代码
通过下面的一个小程序,我们一起来见证一下缓冲区溢出。
#include
#include
#define BUFSIZE 10
void foo()
{
printf("Exploit\n");
}
int main(int argc, char *argv[])
{
char buf[BUFSIZE];
strcpy(buf, argv[1]);
printf("Buf: %s\n", buf);
return 0;
}
对照上图的内存布局图,上面这段小程序中,argv字符串数组就是命令行参数,环境变量(environ)默认不需要显式写出来。
接下来,通过下面的命令,我们将代码编译成二进制可执行文件。
gcc -g -o stack1 stack1.c
gcc带-g参数方便gdb调试。
4.2 运行测试
我们定义了buf的大小是10,下图是测试向buf复制10字节、20字节、24字节、23字节的情况:
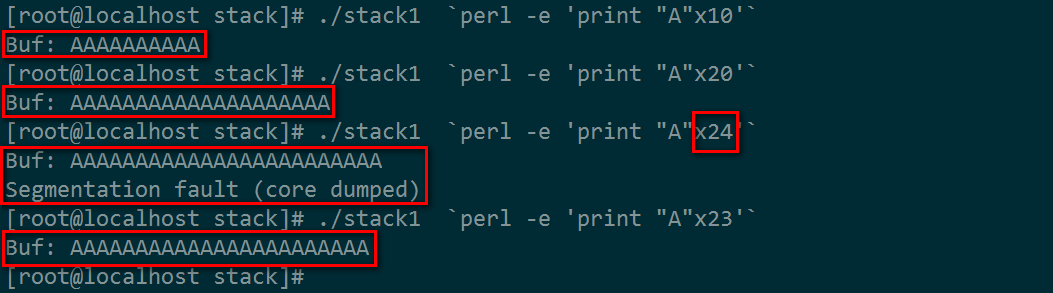
上图中,我用centos 64bit系统测试,当向buf传入24字节时,程序产生了段错误(segmentation fault)。
那么这有问题来了:
- buf的定义是 10 字节,为什么可以传入大于10字节的数据而不出错?
- 当存入24字节时,程序为什么出现段错误?
- 这和缓冲区溢出有关系吗?
先解释第3个问题,上图所参生的错误就是缓冲区溢出造成,我们成功的制造了一次缓冲区溢出案例。
4.3 缓冲区的空间估算
至于第一个问题,是因为所有内存存放数据都遵循约定的方式:存储的数据必需是4、8、16、32和64的倍数,这种方式叫内存对齐。
为什么要对齐呢?
这和cpu存取数据的效率有关,数据对齐方便存取,就和东西摆放得整齐方便寻找一个道理。
所以,虽然定义了buf的大小是10,但向其填充大于10的数据,只要在一定范围内,容忍度还是有的。
那么,为什么它的容忍度不是30,不是20,而偏偏是24呢?因为24就是数据对齐的边界,本来是可以容忍24个字节的,但是符串的结尾有一个空字符’【/0】’,例子中存入24个A时,实际上存入了25个字符,超过了24的边界,越界了,所以就出问题啦!
文字的说服力不如图片,下面请看图:
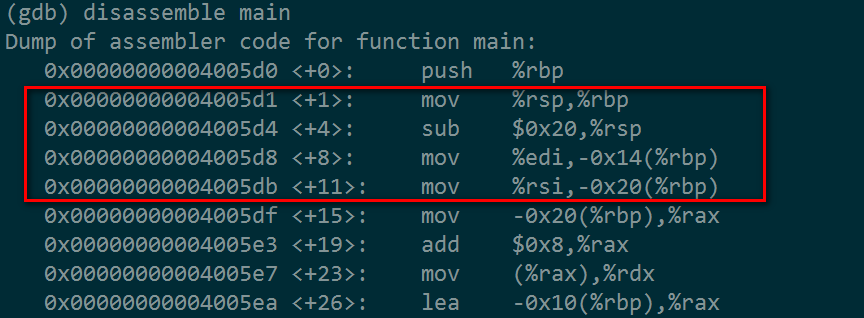
上图是main函数的反汇编代码,我们截取一小部分来看。
红色框部分就是当前栈空间和main的参数传递。
mov %rsp, %rbp 设置当前栈指针地址为基址
sub %0x20, %rsp 新的栈指针
上面两条语句作用是将一段新的内存空间设置为新的栈段,栈的空间大小是0x20(32字节)
mov %edi, -0x14(%rbp) 参数1,距离栈的基址只有0x14(20字节)
mov %rsi, -0x20(%rbp) 参数2
参数1是main的argc, 参数2就是argv字符串数组(其中argv[0]是/root/stack/stack1,argv[1]是我们将要存入buf的数据),我们来验证一下是否正确:
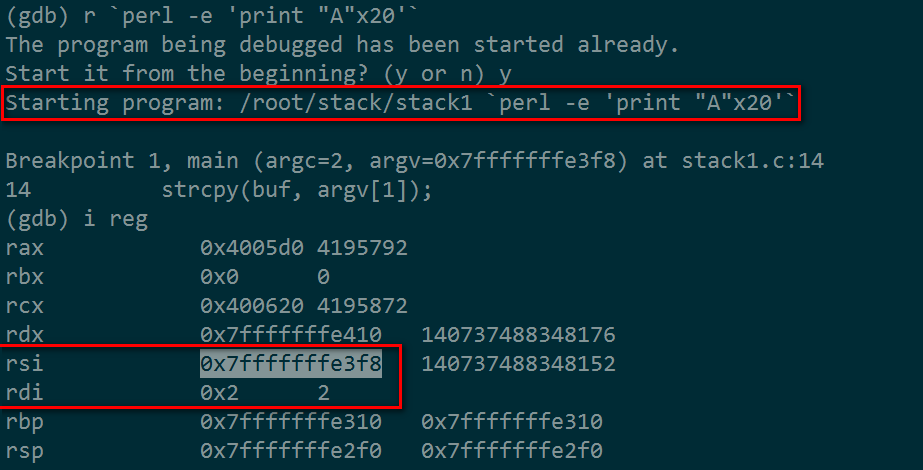
上图我们启动stack1程序,用perl打印20个A作为参数传递,可以看到%rdi = 2, 是argc, %rsi 则是一个双重指针,正符合*argv[]的定义,我们再看看这个指针的数据是什么?

上图显示的正是我们所预期的。
在这里,也可以复习一下什么是双重指针,如**ptr, arry[][]诸类的定义,它们所指的数据,都要经过两层间接才能接触到。同理如果是***ptr这些定义,则要经过三层间接才找到最终数据。
言归正转,说说buf为什么只能容纳24个字节
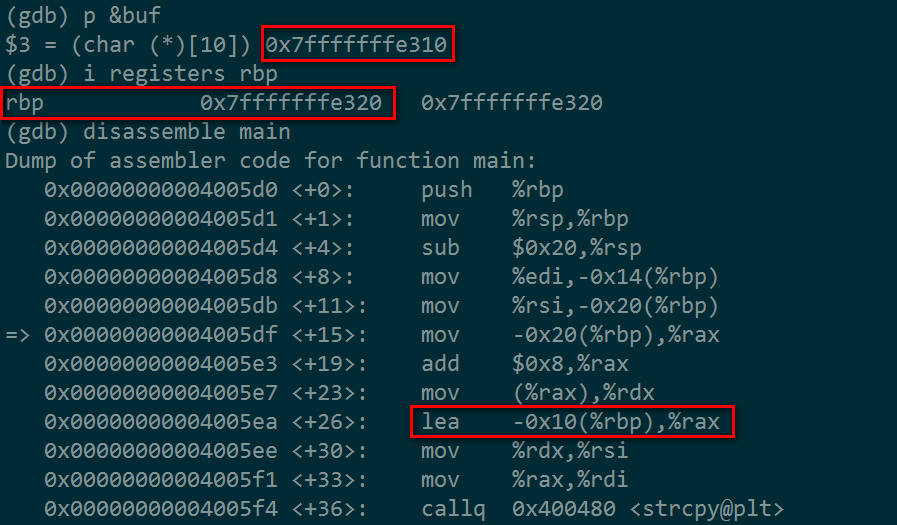
1.对照上图可知,buf的地址在当前的栈空间内,距离栈基RBP只有0x10(16字节),即是说buf至少可以容纳16字节,这是内存数据对齐到8,buf定义是10byte,为了对齐,需要分配16byte。
2.下面再看rbp上面的内容。
 基栈之上
基栈之上
图中可以看到在rbp上的更高的地址里有八个字节多余的,这也是为了对齐而分配的。
这个数字和前面16字节,加起来就刚好是24字节, 注意:这里不同的计算机体系、系统会有不同结果。
而0x7fffffffe328里放的数据就是main函数返回地址(0x00007ffff7a3ab15)。这里的数据读法又涉及不同的计算机体系,有大端小端(Big-endian/Little-endian)之分,区分大小端的方法看上图的数据存放,只要开头的是数据高位,则这个计算机内存数据存储方式就是大端(高字节储存在低地址),因为地址的显示方式是从低往高显示,所以大端就是开始的数据是大的意思。
4.4 main函数返回地址
我们再看下面的图,这是main函数执行时的栈数据
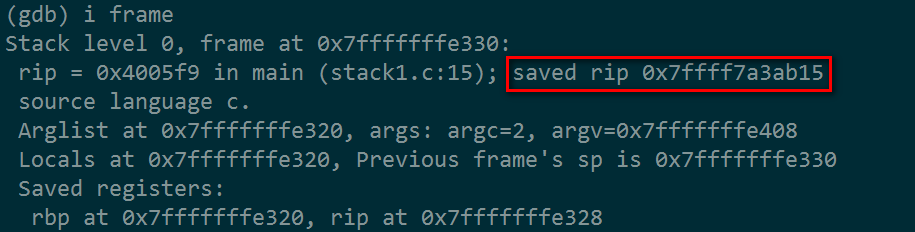
上图红色框部分就是main函数保存在栈的返回地址,当main函数执行完毕后,CPU就会跳到这个地址里执行指令。
那么这个地址(0x7ffff7a3ab15) 保存在哪里呢?
根据程序内存布局,可以肯定,它是保存在栈段里!
下面我们先看看当前的栈帧:
红色框里指示了栈的空间位置,我们再敲入指令看看这个栈帧包含了什么数据

对照红色框里的数据,并没有0x7ffff7a3ab15,即是说main的返回地址并没有保存在当前栈帧空间里,那么是不是我们的肯定过于坚定了呢?
非也!我们再看:

0x7ffff7a3ab15原来躲在了更高的地址里,这个也在栈段范围内,是属于调于函数的栈帧内。
bp和sp代表的是当前的栈帧空间,程序的运行周期里会利用不同的栈空间,实现函数的调用,栈的分段就像电影的帧,所以称为栈帧。
4.5 缓冲区溢出
上述一系列说明,不难看出,我们最终的目的就是在buf里溢出数据去覆盖main的返回地址。
上面分析,我们只要向buf写入大于24字节的数据就可以到达到保存main返回地址的空间,测试也证明了这一点。
当写入大于24字节后,程序为什么会出现Segmentation fault (core dumped)这错误呢?
这是因为,我们覆盖main地址的数据并不是一个main有效的返回地址。
为了达到溢出的真正目的(运行shell,取得root权限),我们需要精心构建溢出数据。
首先我们要学会构建shellcode,那么shellcode是如何构建的呢?请看下回分解!